AI算法的数学原理(AI算法的数学原理)
#创作挑战赛#
深度学习的出现,让视觉识别得到了普遍的应用,这里简单说说它的数学原理。
黑白图像是一个二维的矩阵:宽度、高度,就可以确定像素值的位置。
彩色图像是一个三维的矩阵:宽度、高度、颜色,就可以确定像素值的位置。
原始图像里,大量的信息都是线性相关的:占的字节数很多,而且不能叠加。
图像处理,就是把原始图像通过一组基展开,让它的每一维之间是线性无关的。
说白了,就是把曲线坐标系尽量变成直角坐标系,让表达弧长的系数矩阵尽量简化。
看过我前几篇广义相对论的文章的,应该知道:
直角坐标系里,弧长的平方是 ds^2 = dx^2 dy^2.
曲线坐标系里,弧长的平方是 ds^2 = Adx^2 Bdy^2 Cdxdy,它的坐标实际上不是线性无关的,因为它有交叉的二次项dxdy。
所以,直角坐标系里弧长的矩阵只有2个值不为0,但曲线坐标系里不为0的值更多。
如下图:

人眼周围的像素,肯定都是相关的!
整个人脸的像素都是相关的,因为人脸也是一个特别复杂的曲面:
它也有个曲面方程:f(x, y, z, c) = 0.
x, y, z表示三维坐标,c表示颜色。
虽然没法简单地给出人脸的解析式,但可以用神经网络去近似它:
1,人脸是连续的。
就算脸上受伤了那也是连续的,否则麻烦就大了[捂脸]
既然是连续的,那么极值点最多只有可数个,为什么?
极值的定义是:在x0的某个邻域 N(x0, r) 内,有 f(x0) >= f(x) 或 f(x0) <= f(x).
这个邻域有一个足够小的半径r,在这个邻域内必然存在至少1个有理数。
因为有理数在实数里是稠密的,即:实数的任意一个邻域里都存在有理数。
那么,这个有理数就可以作为这个极值点的代号:它们是一一对应的。
并且,有理数是可数的。
所以,连续函数的极值点,最多只有可数个。
2,可数,就可以用离散的序列去近似。
不要去想数学上那些古怪的函数,在实际工程上暂时遇不到那类函数:任何人的脸都是连续的曲面。
既然是连续曲面,它就可以用折线去近似。
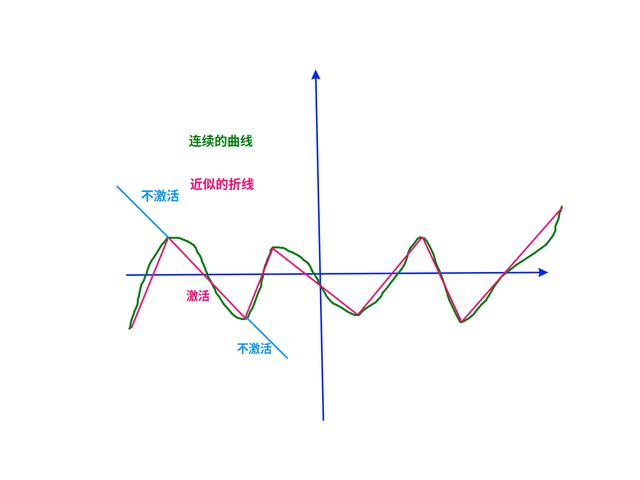
用折线去拟合曲线
极值点之间的曲线,可以认为是单调的!
所以,机器学习上才可以用sigmond、tanh、relu去当激活函数:它们3个都是单调的。
tanh(WX b):
权值W和偏置b确定当前折线的斜率和截距,
tanh函数确定这个位置的折线要不要激活:输出-1或1,还是输出随着WX b变化。
要在极值点以外,让WX b落在tanh()的非激活区!
上图的红线与绿线之间的空白区域,就是拟合的误差。
增加折线的数量,也就是增加神经元的个数,就可以减少误差。
所以,三层神经网络就可以把连续函数拟合到任意精度。

tanh的近似图像
3,BP算法的收敛性,
权值W和偏置b的数值,是通过误差反传算法(BP算法)来迭代求解的。
训练样本,就是人脸曲面的采样数据。
虽然不知道人脸曲面的解析式,但只要它能在一组基上展开,那么它就可以表示成级数的形式:
把不同的样本X带进这个级数之后,形成的关于系数a的一次方程组的行列式 != 0:
所以,当独立的样本数 > N的时候,解是存在的、唯一的。
所以,模型越复杂,需要的样本就越多。
但是不知道g(X)的解析式(而且这个矩阵很大),没法直接求解(只能迭代)。
BP算法要想随着迭代而收敛,迭代算子T就必须满足压缩映射条件:
|| Tx - Tx' || < || x - x'||.
同类样本之间的“神经距离”,应该随着迭代,比样本之间的欧几里德距离要小。
这样,“神经距离”才会类似于迭代次数的等比数列,比值q < 1 所以收敛。
所以,选择合适的学习率是非常重要的!
所以,神经网络的调参非常的坑[捂脸]
4,梯度消失问题,
因为sigmond / tanh的值越接近极限,导数越小,所以在网络层数太多的时候很难训练。
然后,就出现了relu函数。
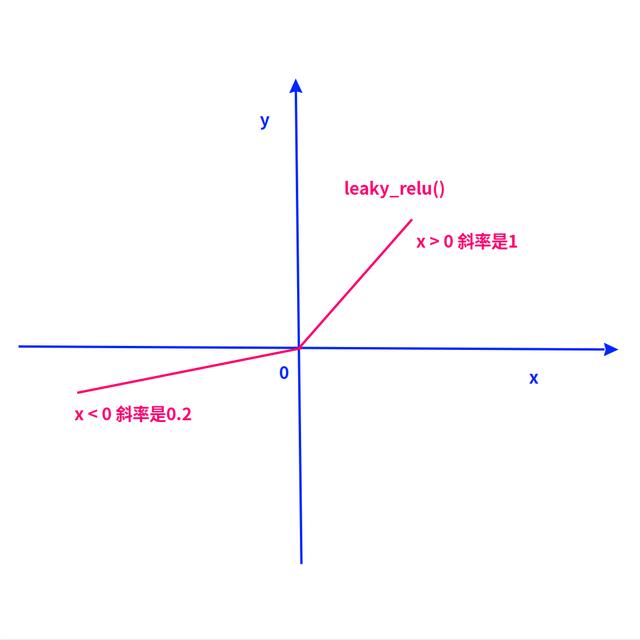
leaky_relu函数
随着网络层数增多,不管梯度 > 1 还是 < 1,都会导致梯度随着层数而急剧增大或减少!
这会让学习率很难选,因为它在每一层的效果不一样。
最好的梯度是1,这样所有层的训练难度是一样的。
然后,就出现了relu函数:x > 0时,y = x;x < 0时,y = 0.
后来,为了避免relu在x < 0时没法训练的问题,又改成了leaky_relu:x > 0时,y = x;x < 0时,y = 0.2x.
让函数在非激活区也有一个 < 1的梯度,勉强可以训练。
这么一改进之后,深度学习的模型终于可以训练了[呲牙]
实际上训练起来依然很复杂,如果样本的分类数量很多,还是一样的难训练[捂脸]
5,什么是非线性?
实际上,只要f(x) 对x的2个范围有不同的斜率,就是非线性。
f(x) = x是线性的,因为它对所有的x都有斜率1。
f(x) = tanh(x) 是非线性的,因为它的斜率一直随着x变化。
f(x) = {
x | x >= 0;
0.2x | x < 0} 也是非线性,因为它对正负数的斜率不一样。
非线性的作用,就是在WX b落到极值点之外的时候,要有一个非激活区。
有1个非激活区就行,因为可以用两层网络的串联形成2个非激活区。
(就跟模拟电路的高通滤波 低通滤波 = 带通滤波一样)
所以,relu做激活函数时,网络的层数比sigmond的要多。
6,让神经网络使用“最少的坐标”,
如果选择的基是最合适的,那么把原始图像展开所需的不为0的系数就会最少。
在深度学习的训练中,怎么做到这点?
实际是先让网络的权值随着层数的增加越来越少,然后用BP算法去训练它[呲牙]
因为每个样本都有类型的标注,同类之间的误差要尽量小,不同类之间的误差要尽量大:
当权值越来越少时,BP算法一样会尽量增大不同样本之间的距离;
然后,系数和基就都训练出来了
这个过程跟写代码一样:程序员为了减少代码行数,然后不断地把重复代码写成函数。
然后,函数越来越多,代码越来越少。
函数就是“基”,实参就是“系数”,每个版本就是一次“BP算法”。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






