短链接服务设计实例(系统方案设计一个)
关注转发,不间断分享实战内容。
短链接,通俗来说,就是将长的URL网址,通过程序计算等方式,转换为简短的网址字符串。
使用场景微博和Twitter都有140字数的限制,如果分享一个长网址,很容易就超出限制。
营销短信,字数的限制,当字数过长: 1.不美观 2.超出字符额外收费。
生成二维码的原始链接,当原始链接过长时,生成的二维码过于复杂,导致一些像素较低的手机无法扫描.
2. 设计目标功能要求:
- 给定一个 URL,我们的服务应该生成一个更短且唯一的别名。这称为短链接。此链接应该足够短,以便轻松复制并粘贴到应用程序中。
- 当用户访问短链接时,我们的服务应该将他们重定向到原始链接。
- 链接支持过期时间设置。
非功能性要求:
- URL 重定向应该以最小的延迟实时发生。
- 缩短的链接规则无法预测。
扩展要求:
- 分析;例如,重定向发生了多少次?
- 其他服务也应该可以通过 REST API 访问我们的服务。
可以使用 REST API 来公开我们服务的功能。以下可能是用于创建和删除 URL 的 API 的定义:
createURL (api_dev_key, original_url, custom_alias=None, user_name=None, expire_date=None)
参数:
api_dev_key(string):注册账号的API开发者密钥。除其他外,这将用于根据分配的配额限制用户。
original_url(字符串):要缩短的原始 URL。
custom_alias(字符串):URL 的可选自定义键。
user_name(字符串):在编码中使用的可选用户名。
expire_date (string): 缩短 URL 的可选过期日期。
返回:(字符串)
成功插入会返回缩短的 URL;否则,它会返回错误代码。
deleteURL (api_dev_key, url_key)
其中“url_key”是一个字符串,表示要检索的缩短的 URL;成功删除会返回“已删除 URL”。
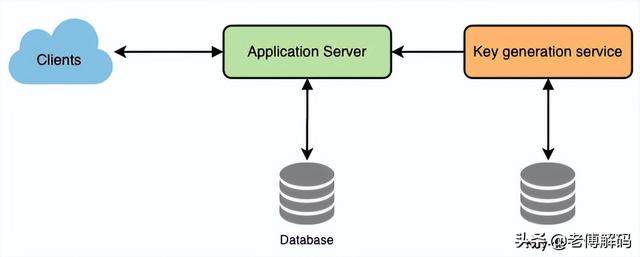
如何发现和防止滥用?恶意用户可以通过使用当前设计中的所有 URL 密钥使我们破产。为了防止滥用,我们可以通过他们的 api_dev_key 限制用户。每个 api_dev_key 可以限制为每个时间段内特定数量的 URL 创建和重定向(每个开发者密钥可以设置为不同的持续时间)。
4. 数据库设计结合储存数据设计:
- 我们需要存储数十亿条记录。
- 我们存储的每个对象都很小(小于 1K)。
- 记录之间没有关系——除了存储哪个用户创建了一个 URL。
- 我们的服务阅读量很大。
数据库架构:
我们需要两张表:一张用于存储有关 URL 映射的信息,另一张用于创建短链接的用户数据。
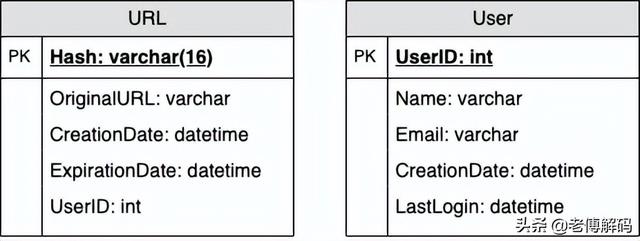
应该使用什么样的数据库?由于我们预计存储数十亿行,并且我们不需要使用对象之间的关系——NoSQL 选择更容易扩展
5. 基本系统设计与算法在第 1 节的示例中,缩短的 URL 是“https://tinyurl.com/vzet59pa”。这个 URL 的最后八个字符构成了我们要生成的短链。讨论以下两种解决方案: 摘要算法、自增序列算法
方案一:摘要算法
- 将长网址 md5 生成 32 位签名串,分为 4 段, 每段 8 个字节
- 对这四段循环处理, 取 8 个字节, 将他看成 16 进制串与 0x3fffffff(30位1) 与操作, 即超过 30 位的忽略处理
- 这 30 位分成 6 段, 每 5 位的数字作为字母表的索引取得特定字符, 依次进行获得 6 位字符串
- 总的 md5 串可以获得 4 个 6 位串,取里面的任意一个就可作为这个长 url 的短 url 地址
这种算法,虽然会生成4个,但是仍然存在重复几率
方案二:自增序列算法
设置 id 自增,一个 10进制 id 对应一个 62进制的数值,1对1,也就不会出现重复的情况。这个利用的就是低进制转化为高进制时,字符数会减少的特性。
第一种算法的好处就是简单好理解,永不重复。但是短码的长度不固定,随着 id 变大从一位长度开始递增。如果非要让短码长度固定也可以就是让 id 从指定的数字开始递增就可以了。百度短网址用的这种算法。
6. 数据分区和复制为了扩展我们的数据库,我们需要对其进行分区,以便它可以存储有关数十亿个 URL 的信息。因此,我们需要开发一种分区方案,将我们的数据划分并存储到不同的数据库服务器中。
一个基于范围的分区:我们可以根据哈希键的第一个字母将 URL 存储在单独的分区中。因此,我们将所有以字母“A”(和“a”)开头的 URL 哈希键保存在一个分区中,将那些以字母“B”开头的 URL 哈希键保存在另一个分区中,依此类推。这种方法称为基于范围的分区。我们甚至可以将某些不太频繁出现的字母组合到一个数据库分区中。因此,我们应该开发一种静态分区方案,以始终以可预测的方式存储/查找 URL。
这种方法的主要问题是它可能导致数据库服务器不平衡。例如,我们决定将所有以字母“E”开头的 URL 放入 DB 分区,但后来我们意识到我们有太多以字母“E”开头的 URL。
另外基于散列的分区:在这个方案中,我们获取我们正在存储的对象的散列。然后我们根据哈希计算要使用的分区。在我们的例子中,我们可以使用“键”或短链接的哈希值来确定我们存储数据对象的分区。
我们的散列函数会将 URL 随机分布到不同的分区中(例如,我们的散列函数总是可以将任何“键”映射到 [1…256] 之间的数字)。这个数字将代表我们存储对象的分区。
这种方法仍然会导致分区过载,这可以使用一致哈希解决。
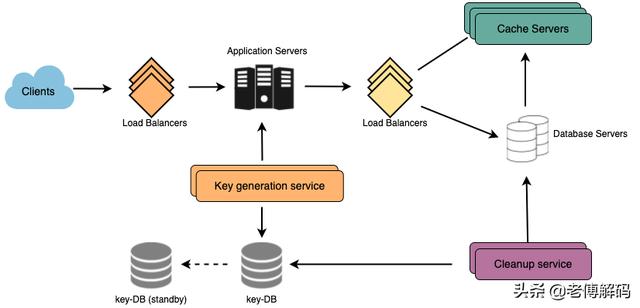
7.缓存可以缓存经常访问的 URL,结合缓存中间件例如 Memcached、redis,它可以存储完整的 URL 及其各自的哈希值。因此,应用服务器在访问后端存储之前,可以快速检查缓存是否具有所需的 URL。
我们应该有多少缓存内存?我们可以从每天 20% 的流量开始,根据客户的使用模式,我们可以调整我们需要多少缓存服务器。如上所述,我们需要 170GB 的内存来缓存 20% 的日常流量。由于现代服务器可以拥有 256GB 内存,我们可以轻松地将所有缓存放入一台机器中。或者,我们可以使用几个较小的服务器来存储所有这些热门 URL。
哪种缓存驱逐策略最适合我们的需求?当缓存已满,并且我们想用更新/更热的 URL 替换链接时,我们将如何选择?最近最少使用 (LRU) 可能是我们系统的合理策略。根据此政策,会首先丢弃最近最少使用的 URL,可以使用 Linked Hash Map 或类似的数据结构来存储我们的 URL 和哈希,这也将跟踪最近访问过的 URL。
如何更新每个缓存副本?每当缓存未命中时,我们的服务器就会访问后端数据库。每当发生这种情况时,我们都可以更新缓存并将新条目传递给所有缓存副本。每个副本都可以通过添加新条目来更新其缓存。如果副本已经有该条目,它可以简单地忽略它。

我们可以在系统的三个地方添加负载均衡层:
- 客户端和应用服务器之间
- 应用服务器和数据库服务器之间
- 应用服务器和缓存服务器之间
条目应该永远存在,还是应该被清除?如果达到用户指定的过期时间,链接会发生什么?
如果我们选择不断搜索过期链接来删除它们,这会给我们的数据库带来很大的压力。相反,我们可以慢慢删除过期链接并进行惰性清理。我们的服务会确保只删除过期的链接。
- 每当用户尝试访问过期链接时,我们都可以删除该链接并向用户返回错误。
- 可以定期运行单独的清理服务,以从我们的存储和缓存中删除过期链接。该服务应该非常轻量级,并且仅在预计用户流量较低时才运行。
- 可以为每个链接设置一个默认的过期时间(例如,两年)。
- 删除过期链接后,我们可以将密钥放回密钥数据库中以供重复使用。
- 我们是否应该删除在一段时间内(比如六个月)未访问过的链接?这可能很棘手。由于存储变得越来越便宜,我们可以决定永远保持链接。
用户能否创建私有 URL 或允许一组特定用户访问 URL?
可以将权限级别(公共/私有)与数据库中的每个 URL 一起存储,还可以创建一个单独的表来存储有权查看特定 URL 的 UserID。如果用户没有权限并尝试访问 URL,可以发回错误 (HTTP 401)。鉴于我们将数据存储在像 Cassandra 这样的 NoSQL 宽列数据库中,表存储权限的键将是“哈希”(或 KGS 生成的“键”)。这些列将存储那些有权查看 URL 的用户的用户 ID。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com