贝叶斯优化优缺点分析(介绍贝叶斯优化)
统计,概率,优化
12分钟阅读

> Photo by M. B. M. on Unsplash
优化功能在许多现实生活中的分析用例中非常重要。通过优化,我们的意思是,用一组参数组合找到目标函数的最大值或最小值。发现MIN或MAX值以及参数应该是目标。在本文中,我们将讨论使用贝叶斯方法优化未知昂贵功能的基础知识。
昂贵的Blackbox功能优化 - 微积分从基本微积分开始,我们知道要找到一个函数的最大值或最小值,我们需要解决以下x的衍生方程:
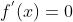
等式的根部将是参数x的最佳值,这又提供了函数f(x)的最佳值。只要您知道功能f(x)的完整代数形式,它很简单。但是,在许多现实生活方案中,事情并不那么简单。如果是黑匣子,那么您只会知道任何F(x)的输出和输入值。所以,分析你找不到衍生品。最重要的是,该函数调用可能非常昂贵。考虑以下两种用例:
1.找出神经网络的最佳覆盖物组合
考虑一个解决分类问题的大型和复杂的神经网络。HyperParameters可以是该网络中隐藏单元的数量,隐藏层数等。这些关系可以被认为是一个假设的函数,它将超参数作为输入,并将分类精度返回为输出。熄灭,您不知道此功能的实际代数形式。找到最佳组合的一种方法将通过重复培训网络来尝试各种随机组合。问题的根源在那里。我们不能承担重复的培训,因为它是一个非常大的和复杂的网络和训练需要花费大量的时间和资源。贝叶斯优化可以在这里提供帮助。
2.考古遗址的挖掘 - 找到最佳的“挖掘”地点
不仅适用于软件(如神经Netowork案例),贝叶斯优化也有助于克服物理世界的挑战。在考古遗址中,主要问题进入专家的思想:“在哪里挖?”。不需要提及,挖掘是一种昂贵的的“黑箱”操作,都在人力,金钱和时间方面。可以认为该函数好像它返回站点中可用的资源列表,参数可能是位置详细信息,以及其他一些非常域特定的东西。发现位置是挑战,贝叶斯方法可以解决它。
在所有情况下,估计需要函数的一些初始运行。考虑以下功能:
它是“白盒子”(因为衍生物可以在分析上发现),并且乍一看并不是非常昂贵的,但是为了便利,假设它是昂贵的和“黑匣子”的性质上,花了很多时间来返回输出。让我们运行一些模拟,
x = np.random.randn(5,2)
y = costly_function(x)
pd.DataFrame(data={'y':y, 'x0':x[:,0], 'x1':x[:,1]})
结果,

该功能需要两个参数x0和x1。对于昂贵的函数,如上述功能,我们只能称之为几次。可能发生,即可以在文件或数据库中给我们初始函数结果和输入。然后,我们必须了解最佳(最小或最大)值和参数组合负责(在这种情况下x0和x1)。我们永远不会知道实际的代数形式,衍生物的分析形式,因此必须在数值上进行优化。
在贝叶斯优化中,初始输入/输出组合集通常如上所述给出,或者可以从功能生成。对于上面讨论的两个用例,它可以如下实现:
- 在不同的超参数组合上培训了神经网络的次数,捕获和存储精度。此集合可用作初始数据点。
- 在考古挖掘操作中,可以执行几个初始挖掘以收集有关网站的信息。它用作初始数据点。
简而言之,它是一个受限制的优化,其解决了以下两个问题:
i)找出以分析衍生物在数字方式中提供黑盒功能最佳值的最佳参数。
ii)将整个过程中的函数调用的数量尽可能最小,因为它非常昂贵。(除了最初的少数运行)
贝叶斯优化命名法贝叶斯方法是基于“BlackBox”功能的统计建模和参数空间的智能探索。很少有命名会是重要的知识。
1.代理模型
它是“BlackBox”功能的统计/概率建模。它作为后来的代理。为了通过不同的参数进行实验,该模型用于模拟功能输出,而不是调用实际昂贵的功能。高斯过程回归(它是多变量高斯随机过程)被用作贝叶斯优化中的“代理”。
2.收购功能
它是一个度量函数,它决定哪个参数值,可以从函数返回最佳值。它有许多变化。我们将与“预期改进”合作。
3.探索与开发
典型的策略可以在参数空间中的本地和全局最优值之间进行补偿。考虑如下所述的图表:

在进行参数空间探索的同时,可以找到许多这样的本地最佳数据点,其中功能具有高或低的值。但是,在一些其他地区可以存在更优化的值,因此该过程不应停止。它被称为“探索”。另一方面,还应对那些始终如一地从功能返回最佳(高或低)值的点。这是“开发”。所以,两者都有一些意义。这是一个琐碎的决定,“何时探索不同位置的更优化的数据点或何时何时利用并进入相同的方向”。这是贝叶斯优化击败传统随机搜索或网格搜索方法的区域,因为它需要中间地面。它有助于使用少量实际函数调用更快地实现目标。其他两种方法用于盲目搜索,完全忽略这一事实。搜索必须非常精确&“to tep”,以降低成本。贝叶斯的方法很好地照顾好。
简而言之,采集函数使用“探索vs开发”策略以迭代方式决定最佳参数搜索。在这些迭代中,替代模型有助于获得函数的模拟输出。任何贝叶斯方法都是基于“先前/后部”二重奏的概念。如前一节所述的函数的初始运行用作起始点或“前导”,并且在每次迭代中,这些“前瞻”富含“后部”数据点。在几个迭代之后,达到最佳数据点,并且整个过程停止在那里。我们将在接下来的行动中看到所有这些。
逐步实现我们将使用相同的“成本昂贵”,在上一节中声明的两个参数,因为我们的目标函数是优化的,即,目前我们需要最大化它。假设该函数是“黑匣子”,并将给予少数运行输出。我们将定义一个类“贝叶斯optimizer”并在一步一步的方式中声明其函数和属性。
让我们首先创建类的结构并声明其属性。
from sklearn.gaussian_process import GaussianProcessRegressor
from scipy.stats import norm
from scipy.optimize import minimize
import sys
import pandas as pd
class BayesianOptimizer():
def __init__(self, target_func, x_init, y_init, n_iter, scale, batch_size):
self.x_init = x_init
self.y_init = y_init
self.target_func = target_func
self.n_iter = n_iter
self.scale = scale
self.batch_size = batch_size
self.gauss_pr = GaussianProcessRegressor()
self.best_samples_ = pd.DataFrame(columns = ['x', 'y', 'ei'])
self.distances_ = []
“Gauss_PR”是上一节中提到的代理模型。“x_init”和“y_init”就像常规的初始运行中函数的参数和输出。您将及时查看其他属性的用法。
现在,我们将在同一类中创建一个名为“_get_expected_improventment”的函数,这是贝叶斯方式的核心。这是前面提到的所需采集函数。让我们在跳入这方面讨论一些理论。
每当尝试新的数据点时,我们需要计算称为“预期改进”或“EI”的度量标准,其提供数据点的重量。公式由:

在哪里


这一开始看起来很糟糕。 “MU(F(x))”是来自高斯过程的预测(即’y’值),用于新数据点x。 “MAX {F(x)}”是从当前阶段的整个前沿列表的预测的最大值(再次从高斯过程获得)。 “Sigma(F(x))”像往常一样是新数据点X的预测的标准偏差。 “mu(f(x))”&“max {f(x)}之间的差异只是为了检查搜索过程的改进。更高的值表示新数据点从函数返回高值,该功能“显着”高于到目前为止所获得的最大值。通过将差异与累积概率密度乘以差异来获得这种“意义”。因此,它给出了预期或整体的“平均”改进和摘录,这是“开发”部分。该值也由神奇因子“Sigma(F(x))”增强。它给出了“ei”度量的不确定性,并且是处理“探索”部分的秘诀。 “mu(f(x))”和“sigma(f(x))”平衡彼此的平衡效果很好,结果EI(x)采用中间地面。
现在,我们将看到此功能的实现,
def _get_expected_improvement(self, x_new):
# Using estimate from Gaussian surrogate instead of actual function for
# a new trial data point to avoid cost
mean_y_new, sigma_y_new = self.gauss_pr.predict(np.array([x_new]), return_std=True)
sigma_y_new = sigma_y_new.reshape(-1,1)
if sigma_y_new == 0.0:
return 0.0
# Using estimates from Gaussian surrogate instead of actual function for
# entire prior distribution to avoid cost
mean_y = self.gauss_pr.predict(self.x_init)
max_mean_y = np.max(mean_y)
z = (mean_y_new - max_mean_y) / sigma_y_new
exp_imp = (mean_y_new - max_mean_y) * norm.cdf(z) sigma_y_new * norm.pdf(z)
return exp_imp
它避免了实际函数调用并使用高斯进程作为代理。因此,通过代理高斯进程,不发生不同点的试验,而不是实际功能。这是“降低成本”的秘密之一。
如何迭代建立这种高斯过程,我们稍后会看到。
接下来,该采集函数用于计算随机选择的数据点附近的“EI”度量,在数值上以数值导数计算最大化。不要在这里混淆!我们再次表示“数值衍生物”的功能。但是,它不是目标昂贵的功能。它是关于最大化采集功能。只是想一想!!我们只会对提供“EI”的最大值的数据点感兴趣,即,从当前最大值达到目标函数(’y’值)的最大提高。
熄灭,它将提供正确的方向,在那里我们应该继续搜索参数空间并避免不必要的盲目探索。这是“降低成本”的第二个秘诀。
我们将看到下一步的实施,
def _acquisition_function(self, x):
return -self._get_expected_improvement(x)
def _get_next_probable_point(self):
min_ei = float(sys.maxsize)
x_optimal = None
# Trial with an array of random data points
for x_start in (np.random.random((self.batch_size,self.x_init.shape[1])) * self.scale):
response = minimize(fun=self._acquisition_function, x0=x_start, method='L-BFGS-B')
if response.fun[0] < min_ei:
min_ei = response.fun[0]
x_optimal = response.x
return x_optimal, min_ei
尝试了一批(由“batch_size”)的随机生成的数据点,并且对于每个,获取功能最大化(实际上是否定函数最小化以匹配“SCIPY”库支持。最小化函数的负数相当于在那个方向上最大化它。同样,使用相应的参数X值拍摄并返回来自迭代的“EI”的最大值。用起点数量最大化,再次从结果中获得最大值实际上向参数X提供正确的方向,其具有正确的平均值和不确定性。它是宽度 - 搜索(不确定性)和深度搜索(平均值)之间的权衡,并获得两者的最佳效果。
现在,下一部分是实际工作。你看到有一个高斯进程回归作为代理模型。它用于在“先前”数据点之上迭代地构建模型。“优化”功能是所有这些功能。它如下所示。
def _extend_prior_with_posterior_data(self, x,y):
self.x_init = np.append(self.x_init, np.array([x]), axis = 0)
self.y_init = np.append(self.y_init, np.array(y), axis = 0)
def optimize(self):
y_max_ind = np.argmax(self.y_init)
y_max = self.y_init[y_max_ind]
optimal_x = self.x_init[y_max_ind]
optimal_ei = None
for i in range(self.n_iter):
self.gauss_pr.fit(self.x_init, self.y_init)
x_next, ei = self._get_next_probable_point()
y_next = self.target_func(np.array([x_next]))
self._extend_prior_with_posterior_data(x_next,y_next)
if y_next[0] > y_max:
y_max = y_next[0]
optimal_x = x_next
optimal_ei = ei[0]
if i == 0:
prev_x = x_next
else:
self.distances_.append(np.linalg.norm(prev_x - x_next))
prev_x = x_next
self.best_samples_ = self.best_samples_.append({"y": y_max, "ei": optimal_ei},ignore_index=True)
return optimal_x, y_max
上述步骤可以概括如下:
i)从初始“先前”数据点中找出最大和相应的参数x
ii)使用初始“先前”数据点构建高斯过程。高斯进程使用最大似然估计来找到参数之间的右侧分布。
iii)使用采集函数获取下一个最佳参数x。如早期的部分所述,它是在高斯模型的帮助下发生不同数据点的试验和错误的步骤,而无需调用实际的“昂贵”目标函数。
iv)使用真实目标函数获取该参数值x的“Y”值。这是“后后”数据点。
v)用“后部”数据更新“Priors”,从“Priors”更新当前最大值,然后再次转到步骤二)
vi)在最后,返回当前最大“y”值和相应的参数x。
您会注意到,我们还在做一些距离计算和捕获当前最佳样本(除了最大的最大y和相应的x时,没有任何内容。从函数“_get_next_probable_point”的两个连续可能的下一个x值之间计算距离。它显示了算法的进度。你会看到结果。
结果我们将使用两个具有2维的样本参数作为初始数据点。我们可以使用n维度,因为“uposity_function”是足够的通用来处理。
sample_x = np.array([[8,1],[6.2,5.3]])sample_y = costly_function(sample_x)
现在,是时候使用“贝叶斯优化器”课程,
bopt = BayesianOptimizer(target_func=costly_function, x_init=sample_x, y_init=sample_y, n_iter=200, scale=10, batch_size=30)bopt.optimize()
它触发了邻域大小的搜索和200次迭代。结果如下所示:

因此,参数x0 = 1.92和x1 = 3.62的昂贵函数的最大值为3.7。您可能已经注意到,在昂贵的函数的定义中,我们已经引入了随机噪声,以使其衍生物难以计算。
请记住,多次,身体或定义“成本高昂”的定义将永远不会可供您使用。在这里,为了我们理解,我们刚刚创建了一个虚拟功能。但是,实际上,这并不是这种情况。可以将样本x&y作为数据集给您,或者将有一些公共/私人托管的“blackbox”API,可以调用以获取任何x的y值。
现在,我们将来自计算的其他一些结果,
可以绘制距离,
pd.DataFrame(bopt.distances_).plot()

注意,两个连续可能的下一个X点之间的距离在迭代中逐渐减小。它是预期的。每次迭代后高斯模型变得更加成熟,其预测变得更加完善,结果准确的“EI”值。最终在每次迭代之后,它达到最佳X更近于最佳X,因此距离开始减小。
现在,我们将看到“Y”值如何在迭代中更改,
bopt.best_samples_['y'].plot()

注意,y以一步方式达到最大值。每次迭代都会产生更好的最大“y”估计。
现在,计算’ei’的同一个曲线
bopt.best_samples_['ei'].plot()

’ei’正在预期下降。想一想!!。在每次迭代之后,产生更好的Y,因此这意味着在我们朝向最佳方面取得更大的改善,可能会有更大的机会。
有趣的事实一个大问题“你如何决定n_iter?”改变其价值肯定会影响我们最大的估计。有一件事要注意到这里,
n_iter等于实际昂贵函数在除初始化部分之外的整个优化过程中调用的次数
因此,摘录其价值取决于我们准备好多少成本。
考虑使用神经网络模型的用例1。如果存在云环境,则每次“培训”的深度神经网络运行和预算约束,那么必须相应地设置“N_ITER”(如在这种情况下,目标函数是网络训练和获取准确性)。
贝叶斯方法试图通过减少实际呼叫来估算功能,因此在某些情况下,其准确性可能不像随机搜索或GridSearch一样好。
贝叶斯优化在成本更重要而不是非常微小的级别准确性时非常有用。
(本文由闻数起舞翻译自Avishek Nag的文章《Bayesian Optimization: A step by step approach》,转载请注明出处,原文链接:https://towardsdatascience.com/bayesian-optimization-a-step-by-step-approach-a1cb678dd2ec)
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






