三层交换机能做透明模式吗(虚拟二层的典型代表)
1.1 概念
GRE全称是Generic Routing Encapsulation,是一种协议封装的格式,具体格式内容见:https://tools.ietf.org/html/rfc2784
协议封装指的是用一种格式的协议封装另一种格式的协议。如
1. TCP/IP协议可以看成是一种封装:TCP传输层协议被网络层的IP协议封装,通过IP协议来进行传输。(这种封装的目的主要是通过分层来严格的区分协议的设计,使得具体的协议设计的时候可以更加的清晰)
2. IP SAN,就是通过IP协议封装scsi协议,使得我们可以直接通过IP网络来进行磁盘数据的传输。(这种封装主要是为了使用现有的设施,方便厂商推广自己的产品,同时通过两种协议的结合产生更多的功能。对于GRE来说,更趋向于这种封装)
1.2 GRE封装格式
GRE的目的是设计一种通用的封装格式,所以如果将它与一些为特定目的进行设计的封装协议比较,那么GRE是没有太多优势的。
A GRE encapsulated packet has the form: --------------------------------- | | | Delivery Header | | | --------------------------------- | | | GRE Header | | | --------------------------------- | | | Payload packet | | | ---------------------------------
1. Delivery Header: 在GRE中,需要被传输和封装的报文称之为payload packet,而用于封装和传输的协议则成为delivery protocol。
2. GRE header: GRE在封装的时候,除了payload packet外,会生成一个GRE header。
3. payload packet: 我们真实要发送的数据包
当A(192.168.1.1) ping B(192.168.2.1)时,报文是如下形式的:

从A到RA
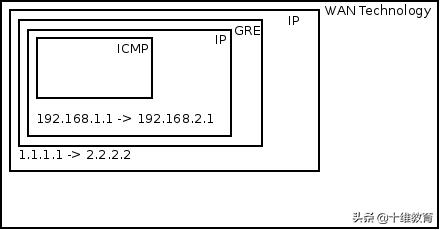
从RA到RB
1.2 Neutron中的GRE
(http://assafmuller.com/2013/10/14/gre-tunnels-in-openstack-neutron/)
- br-tun网桥信息:
[root@NextGen1 ~]# ovs-vsctl show 911ff1ca-590a-4efd-a066-568fbac8c6fb [... Bridge br-int omitted ...] Bridge br-tun Port patch-int Interface patch-int type: patch options: {peer=patch-tun} Port br-tun Interface br-tun type: internal Port "gre-2" Interface "gre-2" type: gre options: {in_key=flow, local_ip="192.168.1.100", out_key=flow, remote_ip="192.168.1.101"} Port "gre-1" Interface "gre-1" type: gre options: {in_key=flow, local_ip="192.168.1.100", out_key=flow, remote_ip="192.168.1.102"}
- VM1(10.0.0.1) pings VM2(10.0.0.2) in different nodes :
Before VM1 can create an ICMP echo request message, VM1 must send out an ARP request for VM2’s MAC address. A quick reminder about ARP encapsulation – It is encapsulated directly in an Ethernet frame – No IP involved (There exists a base assumption that states that ARP requests never leave a broadcast domain therefor IP packets are not needed). The Ethernet frame leaves VM1’s tap device into the host’s br-int. br-int, acting as a normal switch, sees that the destination MAC address in the Ethernet frame is FF:FF:FF:FF:FF:FF – The broadcast address. Because of that it floods it out all ports, including the patch cable linked to br-tun. br-tun receives the frame from the patch cable port and sees that the destination MAC address is the broadcast address. Because of that it will send the message out all GRE tunnels (Essentially flooding the message). But before that, it will encapsulate the message in a GRE header and an IP packet. In fact, two new packets are created: One from 192.168.1.100 to 192.168.1.101, and the other from 192.168.1.100 to 192.168.1.102. The encapsulation over the GRE tunnels looks like this:

To summarize, we can conclude that the flow logic on br-tun implements a learning switch but with a GRE twist. If the message is to a multicast, broadcast, or unknown unicast address it is forwarded out all GRE tunnels. Otherwise if it learned the destination MAC address via earlier messages (By observing the source MAC address, tunnel ID and incoming GRE port) then it forwards it to the correct GRE tunnel.
- br-tun流表:
[root@NextGen1 ~]# ovs-ofctl dump-flows br-tun NXST_FLOW reply (xid=0x4): cookie=0x0, duration=182369.287s, table=0, n_packets=5996, n_bytes=1481720, idle_age=52, hard_age=65534, priority=1,in_port=3 actions=resubmit(,2) cookie=0x0, duration=182374.574s, table=0, n_packets=14172, n_bytes=3908726, idle_age=5, hard_age=65534, priority=1,in_port=1 actions=resubmit(,1) cookie=0x0, duration=182370.094s, table=0, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=1,in_port=2 actions=resubmit(,2) cookie=0x0, duration=182374.078s, table=0, n_packets=3, n_bytes=230, idle_age=65534, hard_age=65534, priority=0 actions=drop cookie=0x0, duration=182373.435s, table=1, n_packets=3917, n_bytes=797884, idle_age=52, hard_age=65534, priority=0,dl_dst=00:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,20) cookie=0x0, duration=182372.888s, table=1, n_packets=10255, n_bytes=3110842, idle_age=5, hard_age=65534, priority=0,dl_dst=01:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,21) cookie=0x0, duration=182103.664s, table=2, n_packets=5982, n_bytes=1479916, idle_age=52, hard_age=65534, priority=1,tun_id=0x1388 actions=mod_vlan_vid:1,resubmit(,10) cookie=0x0, duration=182372.476s, table=2, n_packets=14, n_bytes=1804, idle_age=65534, hard_age=65534, priority=0 actions=drop cookie=0x0, duration=182372.099s, table=3, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=0 actions=drop cookie=0x0, duration=182371.777s, table=10, n_packets=5982, n_bytes=1479916, idle_age=52, hard_age=65534, priority=1 actions=learn(table=20,hard_timeout=300,priority=1,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:0->NXM_OF_VLAN_TCI[],load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],output:NXM_OF_IN_PORT[]),output:1 cookie=0x0, duration=116255.067s, table=20, n_packets=3917, n_bytes=797884, hard_timeout=300, idle_age=52, hard_age=52, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:1f:19:55 actions=load:0->NXM_OF_VLAN_TCI[],load:0x1388->NXM_NX_TUN_ID[],output:3 cookie=0x0, duration=182371.623s, table=20, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=0 actions=resubmit(,21) cookie=0x0, duration=182103.777s, table=21, n_packets=10235, n_bytes=3109310, idle_age=5, hard_age=65534, priority=1,dl_vlan=1 actions=strip_vlan,set_tunnel:0x1388,output:3,output:2 cookie=0x0, duration=182371.507s, table=21, n_packets=20, n_bytes=1532, idle_age=65534, hard_age=65534, priority=0 actions=drop
- table表流程

- 在openstack中主要是通过ovs,ovs支持GRE。通过GRE,VM之间的ARP、IP报文都能在GRE的封装下通过IP网络进行传递。不同的网络通过GRE header中的tunnel id号区别。由于ovs支持openflow协议,为了效率和性能,mac和GRE的路由关系会存放在ovs的流表中。从链接中的文章可以看出,GRE有一个缺点,那就是每新增一个计算节点,都需要其和所有其他计算节点以及network控制器建立GRE链接。在计算节点很多的时候会有性能问题。
GRE 技术本身还是存在一些不足之处:
(1)Tunnel 的数量问题
GRE 是一种点对点(point to point)标准。Neutron 中,所有计算和网络节点之间都会建立 GRE Tunnel。当节点不多的时候,这种组网方法没什么问题。但是,当你在你的很大的数据中心中有 40000 个节点的时候,又会是怎样一种情形呢?使用标准 GRE的话,将会有 780 millions 个 tunnels。
(2)扩大的广播域
GRE 不支持组播,因此一个网络(同一个 GRE Tunnel ID)中的一个虚机发出一个广播帧后,GRE 会将其广播到所有与该节点有隧道连接的节点。
(3)GRE 封装的IP包的过滤和负载均衡问题
目前还是有很多的防火墙和三层网络设备无法解析 GRE Header,因此它们无法对 GRE 封装包做合适的过滤和负载均衡。
二 vxlan2.1 概念
相比于GRE的通用性,VXLAN主要用于封装、转发2层报文。VXLAN全称Virtual eXtensible Local Area Network,简单的说就是扩充了的VLAN,其使得多个通过三层连接的网络可以表现的和直接通过一台一台物理交换机连接配置而成的网络一样处在一个LAN中。其将二层报文加上个vxlan header,封装在一个UDP包中进行传输。vxlan header会包括一个24位的ID(称为VNI),含义类似于VLAN id或者上面提到的GRE的tunnel id。 在上面GRE的例子中,是通过路由器来进行GRE协议的封装和解封的,在VXLAN中这类封装和解封的组件有个专有的名字叫做VTEP。相比起VLAN来说,好处在于其突破了VLAN只有4094子网的限制,同时架设在UDP协议上后其扩展性提高了不少(因为UDP是高层协议,屏蔽了底层的差异,换句话说屏蔽了二层的差异)。
表面上看VXLAN和GRE区别不大,只是对delivery协议做了限定,使用UDP。但是实际上在协议的交互动作上面还是有区别的。和上面的例子一样,假如主机A和主机B想通信,那么A的报文会的被VTEP封装,然后发往连接B的VTEP。在上面的例子中类似于VTEP的角色是由路由器来充当的,而且路由器的两端的地址是配置好的,所以RA知道RB的地址,直接将报文发给RB即可。但是在VXLAN中,A的VTEP并不知道B的VTEP在哪,所以需要一个发现的过程。如何发现呢?VXLAN要求每个VNI都关联一个组播地址。所以对于一次ARP请求,A的VTEP会的发送一个组播IGMP报文给所有同在这个网络组中的其他VTEP。所有的订阅了这个组播地址的VTEP会的收到这个报文,学习发送端的A的MAC和VTEP地址用于以后使用,同时VTEP会将报文解析后比较VNI,发送给同VNI的主机。当某个主机B的IP和ARP中的一样时,其会的发送ARP应答报文,应答报文通过B的VTEP按照类似的流程发送给A,但是由于B的VTEP已经学习到了A的MAC地址,因此B的VTEP直接就可以发送给A的VTEP,而不需要再走一遍通过IGMP的组播过程了。
从这个例子可以看出,VXLAN屏蔽了UDP的存在,上层基本上不感知这层封装。同时VXLAN避免了GRE的点对点必须有连接的缺点。由于需要IGMP,对于物理交换机和路由器需要做一些配置,这点在GRE是不需要的。
vxlan报文格式:
(http://www.borgcube.com/blogs/2011/11/vxlan-primer-part-1/)
(http://www.borgcube.com/blogs/2012/03/vxlan-primer-part-2-lets-get-physical/)

含义:
- Outer MAC destination address (MAC address of the tunnel endpoint VTEP)
- Outer MAC source address (MAC address of the tunnel source VTEP)
- Outer IP destination address (IP address of the tunnel endpoint VTEP)
- Outer IP source address (IP address of the tunnel source VTEP)
- Outer UDP header:Src port 往往用于 load balancing,下文有提到;Dst port 即 VXLAN Port,默认值为 4789.
- VNID:表示该帧的来源虚机所在的 VXLAN 网段的 ID
特点:
- VNID: 24-bits,最大 16777216。每个不同的 24-bits VNI 代表一个 VXLAN 网段。只有同一个网段中的虚机才能互相通信。
- VXLAN Port:目的 UDP 端口,默认使用 4789 端口。用户可以自己配置。
- 两个 VTEP 之间的 VXLAN tunnels 是无状态的。
- VTEP 可以在虚拟交换机上,物理交换机或者物理服务器上通过软件或者硬件实现。
- 使用多播来传送未知目的的、广播或者多播帧。
- VTEP 不可以对 VXLAN 包分段。
2.2 VTEP 寻址
一个 VTEP 可以管理多个 VXLAN 隧道,每个隧道通向不同的目标。那 VTEP 接收到一个二层帧后,它怎么根据二层帧中的目的 MAC 地址找到对应的 VXLAN 隧道呢?VXLAN 利用了多播和 MAC 地址学习技术。如果它收到的帧是个广播帧比如 ARP 帧,也会经过同样的过程。
以下图为例,每个 VTEP 包含两个 VXLAN 隧道。VTEP-1 收到二层 ARP 帧1(A 要查找 B 的 MAC) 后,发出一个 Dst IP 地址为VTEP多播组 239.1.1.1 的 VXLAN 封装 UDP 包。该包会达到 VTEP-2 和 VTEP-3。VTEP-3 收到后,因为目的 IP 地址不在它的范围内,丢弃该包,但是学习到了一条路径:MAC-A,VNI 10,VTEP-1-IP,它知道要到达 A 需要经过 VTEP-1 了。VTEP-2 收到后,发现目的 IP 地址是机器 B,交给 B,同时添加学习到的规则 MAC-A,VNI 10,VTEP-1-IP。B 发回响应帧后,VTEP-2 直接使用 VTEP-1 的 IP 直接将它封装成三层包,通过物理网络直接到达 VTEP-1,再由它交给 A。VTEP-1 也学习到了一条规则 MAC-B,VNI 10,VTEP-2-IP。

2.3 数据流向

发送端:
- 计算目的地址:Linux 内核在发送之前会检查数据帧的目的MAC地址,需要选择目的 VTEP。
- 如果是广播或者多播地址,则使用其 VNI 对应的 VXLAN group 组播地址,该多播组内所有的 VTEP 将收到该多播包;
- 如果是单播地址,如果 Linux 的 MAC 表中包含该 MAC 地址对应的目的 VTEP 地址,则使用它;
- 如果是单播地址,但是 LInux 的 MAC 表中不包含该 MAC 地址对应的目的 VTEP IP,那么使用该 VNI 对应的组播地址。
- 添加Headers:依次添加 VXLAN header,UDP header,IP header。
接收端:
- UDP监听:因为 VXLAN 利用了 UDP,所以它在接收的时候势必须要有一个 UDP server 在监听某个端口,这个是在 VXLAN 初始化的时候完成的。
- IP包剥离:一层一层剥离出原始的数据帧,交给 TCP/IP 栈,由它交给虚机。
2.2 Neutron中的vxlan
(http://www.opencloudblog.com/?p=300)
vxlan的br-tun流表与上面GRE类似。
三 GRE与VXLAN对比FeatureVXLANGRESegmentation24-bit VNI (VXLAN Network Identifier)Uses different Tunnel IDsTheoretical scale limit16 million unique IDs16 million unique IDsTransportUDP (default port 4789)IP Protocol 47FilteringVXLAN uses UDP with a well-known destination port; firewalls and switch/router ACLs can be tailored to block only VXLAN traffic.Firewalls and layer 3 switches and routers with ACLs will typically not parse deeply enough into the GRE header to distinguish tunnel traffic types; all GRE would need to be blocked indiscriminately.Protocol overhead50 bytes over IPv4 (8 bytes VXLAN header, 20 bytes IPv4 header, 8 bytes UDP header, 14 bytes Ethernet).42 bytes over IPv4 (8 bytes GRE header, 20 bytes IPv4 header, 14 bytes Ethernet).Handling unknown destination packets, broadcasts, and multicastVXLAN uses IP multicast to manage flooding from these traffic types. Ideally, one logical Layer 2 network (VNI) is associated with one multicast group address on the physical network. This requires end-to-end IP multicast support on the physical data center network.GRE has no built-in protocol mechanism to address these. This type of traffic is simply replicated to all nodes.IETF specificationhttp://tools.ietf.org/html/draft-mahalingam-dutt-dcops-vxlan-01http://tools.ietf.org/html/rfc2784.html
对于GRE和VXLAN网络模式而言,可以抽象地将每个br-tun看成隧道端点,有状态的隧道点对点连接即为GRE;无状态的隧道使用UDP协议连接则为VXLAN。
四 :Neutron使用OVS支持GRE与VXLAN因为 OVS 对两种协议的实现机制,Neutron 对两个协议的支持的代码和配置几乎是完全一致的,除了一些细小差别,比如名称,以及个别配置比如VXLAN的UDP端口等。OVS 在计算或者网络节点上的 br-tun 上建立多个 tunnel port,和别的节点上的 tunnel port 之间建立点对点的 GRE/VXLAN Tunnel。Neutron GRE/VXLAN network 使用 segmentation_id (VNI 或者 GRE tunnel id) 作为其网络标识,类似于 VLAN ID,来实现不同网络内网络流量之间的隔离。
4.1 open vswitch实现的VXLAN VTEP
从上面的基础知识部分,我们知道 VTEP 不只是实现包的封装和解包,还包括:
(1)ARP 解析:需要尽量高效的方式响应本地虚机的 ARP 请求
(2)目的 VTEP 地址搜索:根据目的虚机的 MAC 地址,找到它所在机器的 VTEP 的 IP 地址
通常的实现方式包括:
(1)使用 L3 多播

(2)使用 SDN 控制器(controller)来提供集中式的 MAC/IP 对照表


(一个基于 Linuxbrige VxLAN Service Node 的集中式 Controller node 解决 VNI-VTEP_IPs 映射的提议,替代L3多播和广播,来源: 20140520-dlapsley-openstack-summit-vancouver-vxlan-v0-150520174345-lva1-app6891.pptx)
(3)在VTEP本地运行一个代理(agent),接收(MAC, IP, VTEP IP)数据,并提供给 VTEP
那 Open vSwitch 是如何实现这些功能需求的呢?
(1)在没有启用 l2population 的情况下,配置了多播就使用多播,没的话就使用广播
(2)在启用 l2population 的情况下,在虚机 boot 以后,通过 MQ 向用于同网络虚机的节点上的 l2population driver 发送两种数据,再将数据加入到 OVS 流表
(2.1)FDB (forwarding database): 目的地址-所在 VTEP IP 地址的对照表,用于查找目的虚机所在的 VTEP 的 IP 地址
(2.2)虚机 IP 地址 - MAC 地址的对照表,用于响应本地虚机的 ARP 请求

4.2 在不使用l2population时的隧道建立过程
https://wiki.openstack.org/wiki/L2population_blueprint
要使用 GRE 和 VXLAN,管理员需要在 ml2 配置文件中配置 local_ip(比如该物理服务器的公网 IP),并使用配置项 tunnel_types 指定要使用的隧道类型,即 GRE 或者 VXLAN。当 enable_tunneling = true 时,Neutorn ML2 Agent 在启动时会建立 tunnel bridge,默认为 br-tun。接着,ML2 Agent 会在 br-tun 上建立 tunnel ports,作为 GRE/VXLAN tunnel 的一端。具体过程如图所示:

OVS 默认使用 4789 作为 VXLAN port。下表中可以看出 Neutron 节点在该端口上监听来自所有源的UDP包:
root@compute1:/home/s1# netstat -lnup Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name udp 3840 0 0.0.0.0:4789 0.0.0.0:*
l2pop 的原理也不复杂。Neutron 中保存每一个端口的状态,而端口保存了网络相关的数据。虚机启动过程中,其端口状态会从 down 到build 到 active。因此,在每次端口发生状态变化时,函数 update_port_postcommit 都将会被调用,保证每个节点上的如下数据得到了实时更新,从而避免了不必要的隧道连接和广播。
有和没有 l2pop 的效果:

4.3 mtu 问题
VXLAN 模式下虚拟机中的 mtu 最大值为1450,也就是只能小于1450,大于这个值会导致 openvswitch 传输分片,进而导致虚拟机中数据包数据重传,从而导致网络性能下降。GRE 模式下虚拟机 mtu 最大为1462。
计算方法如下:
- vxlan mtu = 1450 = 1500 – 20(ip头) – 8(udp头) – 8(vxlan头) – 14(以太网头)
- gre mtu = 1458 = 1500 – 20(ip头) – 8(gre头) – 14(以太网头)
可以配置 Neutron DHCP 组件,让虚拟机自动配置 mtu,官方文档链接 http://docs.openstack.org/juno/install-guide/install/yum/content/neutron-network-node.html
#/etc/neutron/dhcp_agent.ini [DEFAULT] dnsmasq_config_file = /etc/neutron/dnsmasq-neutron.conf #/etc/neutron/dnsmasq-neutron.conf dhcp-option-force=26,1450或1458 #26代表要设置的是mtu值
重启 DHCP Agent,让虚拟机重新获取 IP,然后使用 ifconfig 查看是否正确配置 mtu。
五 总结- vxlan网络指定的segment id 就是vxlan的tunnel id,local vlan号则由neutron代码按序生成,tunnel id 与 local vlan 由br-tun流表来保证一一对应。
而由于br-tun的port与trunk0的tunnel-bearing子接口相连,tunnel-bearing子接口也带vlan id,该vlan id放在Delivery Header的vlan id中,是为了与管理网络隔离。
- local vlan 与 外部 vlan 区别
两个VM所属segment id 一样,位于不同server上时,local vlan id 不一定一样。local vlan只是作用于当前server上,用于隔离该server上的其他VM。
- br-tun中有关GRE/Vxlan的port是如何生成的?
ovs-agent启动时,会上报自己的tunnel local ip 给neutron server ,然后neutron server 会发rpc消息给其他所有 ovs-agent ,在br-tun上建立相关联的port。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






