opencv人脸识别详细过程(2022上人脸识别相关的论文分类整理)
人脸识别是AI研究的一个重要的方向,CVPR 2022也有很多相关的论文,本篇文章将针对不同的应用分类进行整理,希望对你有帮助

人脸识是一个热门话题,在当前的基准测试中要以相当大的提升击败 现有的SOTA模型变得越来越困难。
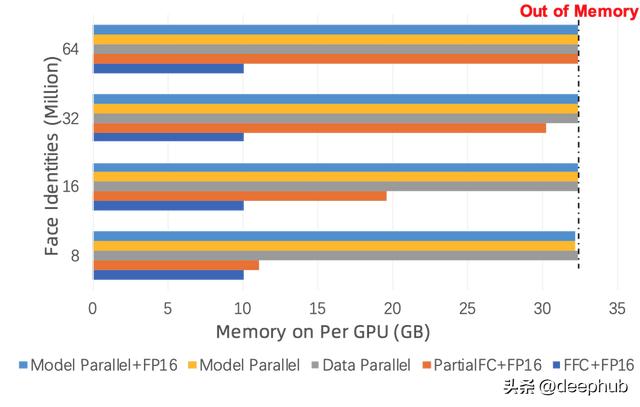
越来越多的开放数据可以用于训练,在百万级规模的数据上进行训练的一个主要问题是:最终的全连接层随着身份的数量线性扩展,会导致每次迭代时内存占用巨大并且反向传播时非常慢。一种旨在缓解这种情况的方法是 Partial FC [2](在今年CVPR上发表之前就已经非常流行了)它已经包含在insightface的repo中。该方法试图逼近现在标准的训练人脸识别方法(如CosFace、ArcFace等)的最后一层。为了达到更好的缩放人脸识别的目的,Wang等人(来自阿里巴巴)的方法[3]使用名为动态分类池(Dynamic Class Pool)的来替代最后的FC层,并通过更好的数据加载器进行了进一步的改进(见下图)。

另外两篇关于人脸识别的论文:He at al. [4]试图将深度和反照率从人脸图像中分离出来,提高使用 3D 信息的识别能力。 它通过引入带有两个辅助网络的 3D 人脸重建损失来实现这一点。现在又很多方法都在试图将面部整合成 3D 信息(NeRF的论文中也看到相同的内容)。Phan和Nguyen的[5]方法也可以在重度遮挡人脸(太阳镜、口罩等)的人脸图片上验证,而且不需要对模型进行再训练。

[4] 使用人脸的 3D 重建来改善人脸识别。

[5] 提出了一种巧妙的方法来使用未被遮挡的面部部分进行面部验证(它不会重新训练模型)。
减少偏置今年在CVPR上看到了很多减少偏置的方法,很多论文都提出了不需要大量的注释数据来显著减轻偏置。
Liu和Yu[9]首先定义了一种新的人脸识别训练的边际损失,它使用了几种偏置因素的组合,如种族、姿势、模糊和遮挡。他们的方法也使用了一些长尾方法进行训练(学习如何学习)。
Jung, Chun和Moon[10]的“Learning Fair Classifiers with Partially Annotated Group Labels”提出,当只有一小部分数据集有敏感组标签的标注时,当前的公平分类方法的性能比从头训练差。然后作者提出了一种方法:可以通过只对一小部分组数据进行标注来提高公平性——在他们的实验中,只有 10% 就足够了。。
Wang等人[11]的研究更进一步,提出了一种无需再训练就能减轻已部署模型偏差的方法。它使用了那些在十年前流行的对抗性扰动,表明只需要添加一个看起来是随机的噪声(这在视觉上不会影响人类的图像),就可以在分类器中很容易改变图像的一个类别。论文中他们试图找到这个扰动,来纠正似乎来自模型偏差的误差。

Dhar et al. [6] 提出了一种基于知识蒸馏的巧妙方法,将识别和活体检测数据集结合在单个多任务网络中,用于人眼认证和演示攻击检测。当没有标注的活体检测数据集中的人的身份时这种方法是非常好的。
Wang et al. [7] 在人脸中获取随机补丁并应用类似于 arcface 的损失,来创建簇见距离的图像特征,他们通过演示媒体和相机质量来区分PS图像。
人脸伪造识别目前在认证系统中经常出现的一种欺诈是人脸的伪造(deepfake),通过伪造人脸可以绕过检测系统。
Shiohara和Yamasaki[12]提出了一种方法,通过使用同一个人作为源图像和目标图像(他们称之为自混合图像),使deepfake变得更加困难。
Jia et al [13] 提出了一种创建对抗性攻击的方法,不仅在基于空间的检测器中有效,而且在基于频率的检测器中也有效。
人脸重建人脸重建的目的是从低质量的人脸图像中重建出高质量的人脸图像。在
Zhu et al. [14](腾讯)利用3D信息来引导形状并与生成先验整合来进行人脸重建。论文的结果表明,与SOTA相比,该方法在重建真实人脸方面表现得相当好,但从论文的图像样本中可以清楚地看出,有时人的身份特征丢失了——这意味着,重建的图像,即使是真实的人脸,它看起来也不是原始图像中的同一个人。
Zhao等人发表了一篇非常有趣的论文,题为“Rethinking Deep Face Restoration”[15],正好阐述了类似上面论文产生的身份丢失的问题。他们将人脸修复问题分为人脸生成和人脸重建两个方面。通过单独解决每个问题,并在两个阶段提出改进,可以大大改善结果。他们还提出了一个新的衡量标准来评估在重建过程中保留了多少身份特征。这是第一篇以这种方式评估重建的论文。这样看,这个领域将如何发展,以及是否有可能在人脸识别之前使用这些方法还是可以有巨大的进步的。

NeRF 仍然是本次 CVPR 中的热门话题,基本上 NeRF 是一个生成模型,它使用来自不同视点的对象图片进行训练。 经过训练模型就能够生成场景的新视点。
今年CVPR最佳学生论文荣誉奖被授予 Verbin 等人的工作 [16]。 他们的方法找到了一种改善 NeRF 镜面反射的方法(演示也很出彩)。 尽管没有用于面部生物识别,但 NeRF 被大量用于参数化面部/头部。
Athar et al. [17]的工作结合了非常常见的人脸 3D 参数化 (3DMM) 和 NeRF。 由此产生的系统能够使用显式参数来改变头部姿势和表情。 也可以使用视频作为输入,并且他们也提供了视频的演示。

最后,Rebain等人的一篇论文[18](谷歌)似乎改变了nerf的游戏规则,它被称为“LOLNeRF: Learn from One Look”。顾名思义,它们设法从大量单视图图像集合中学习形状和外观表示,有兴趣的可以看看他们提供的DEMO。

以上就是CVPR 2022上可能和人脸识别相关的论文总结,我在下面也提供了各个论文的引用,请按需查看:
1] — Kim, M., Jain, A. K., & Liu, X. (2022). AdaFace: Quality Adaptive Margin for Face Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 18750–18759).
[2] — An, X., Deng, J., Guo, J., Feng, Z., Zhu, X., Yang, J., & Liu, T. (2022). Killing Two Birds with One Stone: Efficient and Robust Training of Face Recognition CNNs by Partial FC. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4042–4051).
[3] — Wang, K., Wang, S., Zhang, P., Zhou, Z., Zhu, Z., Wang, X., … & You, Y. (2022). An efficient training approach for very large scale face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4083–4092).
[4] — He, M., Zhang, J., Shan, S., & Chen, X. (2022). Enhancing Face Recognition With Self-Supervised 3D Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4062–4071).
[5] — Phan, H., & Nguyen, A. (2022). DeepFace-EMD: Re-Ranking Using Patch-Wise Earth Mover’s Distance Improves Out-of-Distribution Face Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 20259–20269).
[6] — Dhar, P., Kumar, A., Kaplan, K., Gupta, K., Ranjan, R., & Chellappa, R. (2022). EyePAD : A Distillation-based approach for joint Eye Authentication and Presentation Attack Detection using Periocular Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 20218–20227).
[7] — Wang, C. Y., Lu, Y. D., Yang, S. T., & Lai, S. H. (2022). PatchNet: A Simple Face Anti-Spoofing Framework via Fine-Grained Patch Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 20281–20290).
[8] — Wang, Z., Wang, Z., Yu, Z., Deng, W., Li, J., Gao, T., & Wang, Z. (2022). Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4123–4133).
[9] — Liu, C., Yu, X., Tsai, Y. H., Faraki, M., Moslemi, R., Chandraker, M., & Fu, Y. (2022). Learning to Learn across Diverse Data Biases in Deep Face Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4072–4082).
[10] — Jung, S., Chun, S., & Moon, T. (2022). Learning Fair Classifiers with Partially Annotated Group Labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10348–10357).
[11] — Wang, Z., Dong, X., Xue, H., Zhang, Z., Chiu, W., Wei, T., & Ren, K. (2022). Fairness-aware Adversarial Perturbation Towards Bias Mitigation for Deployed Deep Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10379–10388).
[12] — Shiohara, K., & Yamasaki, T. (2022). Detecting Deepfakes with Self-Blended Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 18720–18729).
[13] — Jia, S., Ma, C., Yao, T., Yin, B., Ding, S., & Yang, X. (2022). Exploring Frequency Adversarial Attacks for Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4103–4112).
[14] — Zhu, F., Zhu, J., Chu, W., Zhang, X., Ji, X., Wang, C., & Tai, Y. (2022). Blind Face Restoration via Integrating Face Shape and Generative Priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7662–7671).
[15] — Zhao, Yang, Yu-Chuan Su, Chun-Te Chu, Yandong Li, Marius Renn, Yukun Zhu, Changyou Chen, and Xuhui Jia. “Rethinking Deep Face Restoration.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7652–7661. 2022.Neural Radiance Fields (NeRFs)
[16] — Verbin, D., Hedman, P., Mildenhall, B., Zickler, T., Barron, J. T., & Srinivasan, P. P. (2021). Ref-nerf: Structured view-dependent appearance for neural radiance fields. arXiv preprint arXiv:2112.03907.
[17] — Athar, S., Xu, Z., Sunkavalli, K., Shechtman, E., & Shu, Z. (2022). RigNeRF: Fully Controllable Neural 3D Portraits. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 20364–20373).
[18] — Rebain, D., Matthews, M., Yi, K. M., Lagun, D., & Tagliasacchi, A. (2022). LOLNeRF: Learn from One Look. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1558–1567).
作者:Gustavo Führ
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






