身份证打不出来的人名(身份证上的人名)

因身份证上的地名、人名专用字无法显示而造成不便的现象已经屡次见诸新闻报道,而所有的新闻报道都像投进深潭里的石子,再也没有了回声。那么,电脑为什么无法显示这些“生僻字”?有没有办法解决?为什么问题出现这么久了仍然解决不了?我写本系列文章的目的,就是试图根据我近几年参与地名用字编码工作的经验,对这些问题进行初步探讨。
(注:严格来说,Unicode标准和ISO/IEC 10646标准是有差别的,但对于非专业人员来说,可以认为两个标准等效。为了方便,文中统一用Unicode标准指代上述两个标准。)
原理篇
首先,我们来回答第一个问题:为什么身份证上的地名、人名专用字电脑显示不了?要回答这个问题,就必须先了解电脑显示字符(比如汉字、英文、标点等)的原理:
1
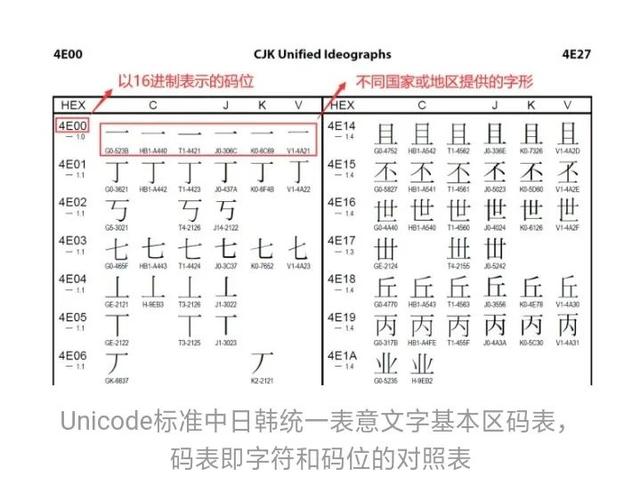
Unicode标准
其实在电子设备的最底层,处理的都是二进制的数据,对应物理电路的开和关两种状态——那么,要处理各类字符,就必须用一串0和1来表示它们。为了不致混乱,现在国际上有一个统一的标准,来规定具体哪串二进制数代表哪个字符,即Unicode标准。在这里可以打一个不很恰当的比方,为了便于理解:Unicode标准的作用大概相当于世界语之于世界各国的语言,可以让不同计算机和应用之间的数据传输畅通无阻。只不过在计算机的世界里,大家基本都用“世界语”。在Unicode标准下,代表某个字符的一串二进制数称为这个字符的“码位”,给一个字符指定一串二进制数的行为就叫做“编码”,ISO(国际标准化组织)的一个下属机构和Unicode Consortium(统一码协会)负责这个标准的制定工作。
2
电脑显示汉字的过程
电脑显示汉字的过程大概如下:
|
1 |
电脑读到一串数据,首先判断是否为文本数据; |
|
2 |
若是文本数据,则根据读到的数据调用相应字体文件中储存的字形; |
|
3 |
经一系列渲染操作,字体文件中以数据形式储存的字形被显示到屏幕上,起到传递信息的作用。 |

以Windows10系统为例,它的系统字体文件一般保存在C:/Windows/Fonts路径下,在显示字符时,系统就会调用这里不同的字体文件。这里需要说明的一点是,简单情况下,字体文件中,储存的仅是字形和调用这个字形所需的二进制数据,不必与Unicode标准发生直接关联。换句话说就是,在实际操作中,可以让字体文件中的二进制数据和对应字形不符合Unicode标准的规定,如果是这样的话,上述显示过程仍可以进行,只不过屏幕上显示的字形会和其他设备不同,很有可能造成混乱或者误解,甚至是系统错误。再做个不很恰当的比喻:假设某个语言A中同英语词“fuck”同音的词含义为“谢谢”,在一个其他所有人都只懂英语的场合,用A语言说“谢谢”就会产生误解,还很有可能被群殴。
3
输入法在显示过程中扮演的角色
从本质上来说,各类输入法软件的作用其实就是建立一个键盘输入的字母序列同显示字符之间的映射。在输入汉字时,从本质上来说,其实可以粗略理解为由键盘通过输入法软件“存入”二进制数据,再进行2中显示步骤的过程。需要强调的是,在实际操作中,输入法软件可以“存入”不符合Unicode标准的二进制数据,结果当然也是造成混乱或者错误;一般情况下,即由输入法软件在输入过程中“存入”了符合Unicode标准的二进制数据的情况下,设备具体所显示的基本字形,仍然还要由字体文件所决定。换句话说,如果字体文件中的二进制数据和对应字形不符合Unicode标准的规定,仍无法使用这个字体来“正确”显示字符;如果字体文件中根本没有和这串二进制数据对应的字形,那就只能显示为空白。
4
进一步的理解,以及对第一个问题的回答
有了以上的知识储备,就可以理解为什么身份证上的地名、人名专用字电脑显示不了了。现在出现地名、人名专用字电脑无法显示的现象的原因不外乎三点:
(1)Unicode标准没有收录这个汉字。
汉字文献浩如烟海,在文献产生、传抄、演变的漫长过程中,大量的汉字随之产生,字形也随之千变万化,势必有一部分相对通行字较罕用的汉字无法被Unicode标准的制定者所了解并被收入标准中。这就相当于一个事物在“世界语”中没有名称,无法用“世界语”来表述。
(2)使用的设备、软件或者字体文件没有跟进最新版的Unicode的标准。
一般情况下,从标准的制定、发布到标准在实际中被广泛应用一般都要经历一段并不短的普及期。因为各大厂商首先要对新标准进行初步了解,然后还可能要对系统或软件进行更新以支持新标准,以及字体文件的制作等都需要花费时间。除了时间上的限制之外,由于应用场景不同,不同的设备、系统或者软件支持的标准范围也会有不同;对大量设备进行更新所产生的经济成本也可能造成对最新版Unicode标准跟进的延迟。
这里要强调的是,制作字体文件异常耗时费力,因为要制作一款美观的字体,常常需要用大量时间来微调“控制点”:

(3)由于个人知识和技术水平的限制,造成无法输入
对于一般人来说,输入手段基本就是各类输入法,比如拼音、五笔、郑码等输入法,但是大多数的输入法对罕用字的支持都很差。造成这种现象的原因是多方面的,先不在这里赘述,后文中还会提及。总之,这就给普通人输入罕用字造成了障碍。
新闻报道以及网络求助中的情况大多都属于第二类和第三类,第一种情况比较少,但也是最难解决、解决需要时间最长的情况,必须一提的是,绝大多数Unicode标准未收字从未见诸新闻报道,解决其输入问题更是任重而道远。

读到这里,你可能会疑惑,那为什么第一类字身份证上也可以显示呢?要回答这个问题,就要引出私用区(PUA,Private Use Area)的概念。
为了能统一编码世界上所有的文字及符号以及实现一些信息处理功能,Unicode标准共“准备”了17*65536个码位,其中前面的17是指统一码标准将这些码位分为17个集合,每一个集合称为一个平面(plane)。在12.1.0版本中,共收录了137,929个字符,主要使用了第0-2平面。上文说道,汉字数量众多,世界上所有语言的文字和符号就更多,其中必然有一部分字符,是Unicode标准尚未收录的;另外,总有人会“奇思妙想”,自己创造字符。为了满足显示上述字符的需求,Unicode标准划出了一部分码位,供用户自由定义,Unicode标准永远不会为其指定特定的字符。这部分码位范围就被称为“私用区”。说白了,就是说我在制作电脑字体时,让这些码位和任何字形/图案对应都是符合标准的。如果用“世界语”作类比的话,就相当于“世界语”规定了可以用的字母组合形式有17组,每组有65536个,并且还规定了可以用其中一部分字母组合来代表“各国语言”中有,“世界语”中暂时还没有的事物。单独建立私用区的好处在于,Unicode标准更新之后新加入的字符对应的码位不会和用户自己定义的码位冲突,两者可以永远“相安无事”。

身份证上之所以能显示第一类字,就是因为身份证所使用的特殊字体“方正宋体-人口信息”使用了私用区的码位来表示Unicode标准尚未收录的汉字。但是,经过上面的介绍我们可以推论出:私用区的码位所代表的字符和所选用的字体密切相关。“方正宋体-人口信息”这一字体只在公安及民政等系统中通用,而且属于涉密文件,一般的设备甚至银行等机构的设备上都没有这个字体,所以无法显示。这里还要说明一点,“方正宋体-人口信息”这一字体其实就是所谓的“公安局字库”对应的字体文件,这个字体也没有同最新版Unicode标准保持一致,还在用私用区码位表示一部分已经编码的汉字。
下面我们就来谈谈,如果遇到了无法输入的字,怎么解决呢?
如果遇到了一个无法输入的汉字,首先,我们应该先查一查这个字是否已经被Unicode标准收录,最保险的方法当然是通过之前在第1部分提到的Unicode标准码表逐一核对,但这既费时又费力,效率不高,不建议使用。我建议可以通过字海网的两分功能查询(http://yedict.com/)
如果查询结果有unicode码,基本上就可以确定为已编码字,否则则为未编码字。这个查询方法是有可能有遗漏的,但概率很小。

如果查询结果是已编码字,那么就可以归结为第二类或第三类问题。这种情况下,可以通过安装支持更多字符的字体来解决显示问题,通过安装特殊输入法(比如字海两分输入法)、导入自制词库或内码输入的方法解决输入问题。所谓内码输入,本质上说就是实现Unicode码同字符之间的转换。比如,在Windows系统下打开Word,输入4E00,选中后,字体选择宋体,按Alt X,即可实现Unicode码和字符“一”之间的转换,其它字符同理。Unicode码可以在各种网络字典中方便地查得。d导入自制词库的具体方法也可以在网络上查得,这里不再赘述,另外,也可以通过字海网联系方式中的官方QQ群寻求专业帮助。
如果是未编码字,可以使用私用区暂时解决显示问题,比如自己制作一个字体文件或利用他人已经做好的字体。在这里推荐Andrew West(魏安)先生的Babelstone PUA,囊括了90%以上的未编码地名用字:
(http://www.babelstone.co.uk/Fonts/PUA.html)
或者也可以通过上述QQ群求助。如果需要在网络上进行实名认证或有其它需要输入此字进行信息核对的需求,可以联系我查询此字在字体“方正宋体-人口信息”中对应的码位,通过内码输入的方法输入后,粘贴至文本输入框内进行认证,有概率成功。
但这些都只是应急的办法,最彻底、最理想的解决办法还是把这个字加入到国际标准中,增加对此类问题的关注度,加速普及。
在Unicode标准字符集中,汉字部分称为中日韩统一表意文字,简称CJKUI,字形完全相同或字形差异不大且字义相通的字在其中拥有同一个码位。这里所说的“汉字”是广义的,包括韩国汉字、和制汉字、壮字等等。负责制定这部分标准的组织是IRG(Ideographic Research Group),有一个一口气念不完的全称:
“国际标准化组织和国际电工委员会下属第一联合技术委员会第二子委员会第二工作组表意文字小组(ISO/IEC JTC1/SC2/WG2/IRG)”。
一个汉字要进入统一码标准,首先要由各提交源在一个新扩展区的提交期内提交字形及证据,再经过IRG专家的多轮检查,最后定稿后还要公示至少两年。

所谓的证据,一般指含有未编码字、有上下文的1949年之前的古籍或1949年之后的印刷体文献整页图片或扫描版页面,或者居民身份证、户口本、政府开具的证明等可以确实证明未编码字有编码价值的资料。如果个人想要提交未编码字,可以把符合要求的证据交给相应的提交方,再由提交方提交至IRG;除此之外,原则上来说,每个人都可以向UTC(委员会源)提交相关的提案,再由UTC以委员会的名义提交给IRG,但是分散、水平参差不齐的提案会大大降低工作效率,所以现在能写出合格提案提交汉字的人仍然不多。
综上,可以看出,所有的问题都是有解决办法的。只不过,提交汉字并且编码的工作比较复杂,流程持续时间很长;也不得不承认,这是身份证上的字打不出来的现象长期无法解决的客观诱因之一,但并不具有决定性。我认为,出现这种情况的主要原因仍然在“人事”(没有任何贬义的感情色彩)。在下一部分《人事篇》中,我将对造成这种现象的更深层次的原因进行讨论,试图初步回答文初的最后一个问题。
人事篇
阅读指南
1. 这篇文章仅代表我的个人观点。
2. 就我个人来说,我很少会单纯地用对或者错来评判一件事,或者用好和坏来评判一个人,因为我认为大多数所谓的“对错”其实只是观念的差异和幸运与否造成的。希望各位不要带着成见阅读本部分。
3. 很多人都有一种找“责任人”的思想:出了事情之后必须要找一个人或者几个人为其负责。但我认为这种行为多半只能起到给自己找心理安慰的作用,不会触及问题的根本,也不能真正解决问题。希望读者在读本部分时也能摒弃这种想法。
读过《原理篇》,应该不难理解,解决地名和人名用字显示问题的根本途径应该是:
(1)将符合提交要求的证据提交至IRG;
(2)提交的字经一定审批流程后正式编码;
(3)国标依据最新版的国际标准更新;
(4)各厂商或制作人产出符合最新国家强制标准的产品,并在国内发行;
(5)用户无障碍地输入、显示字符。
其中第(2)步实现后到第(5)步实现前的时间可认为是《原理篇》中所提及的标准普及期。而在(5)步实现之前,最好的情况是国内有一个通用的PUA体系来满足标准化之前的显示需求。如此来看,如果上述措施做的得当,是不会出现地名和人名用字显示问题的——所以,肯定是其中的一个或者几个步骤出了问题。
首先,我想先介绍一下各领域的现状,也可以看作是此类问题得不到解决的直接原因。
1
现状
(1)提交未编码人名或者地名用字的速度太慢,国标跟进国际通用字符编码标准不及时。
先看未编码人名或地名用字的提交情况。《信息技术 信息交换用汉字编码字符集 第八辅助集(SJ/T 11239-2001)》(下称《八辅》)[1]收录的2497个单字中,现仅有1283个字被Unicode标准字符集收录[2]:其中基本区(URO)266字,基本补充区(URO )1字,扩展A区(Extention A)108字,扩展B区543字,扩展C区180字,扩展D区1字(「⿰阝显」, U 2B803),扩展E区127字,扩展F区56字,扩展G区71字,兼容区1字。即使算上在WS2017(未来的扩展H)中提交的280字,到现在为止仍有863字未提交过任何有效证据;这863字中,约有600字还未找到任何其它相关资料。假设以后每个提交期都以WS2017的速度提交[3],仍需3个提交期——从提交证据给IRG到正式编码一般需要3-5年,这就意味着至少还需要10年才能完成八辅字的编码工作,而从2001年到现在,已经过去了19年。这还是没有考虑《八辅》未收录的诸多地名用字,没有考虑人名用字得出的结论。

再来看国标对Unicode标准的跟进情况。国内唯一的现行强制中文字符集标准GB18030的版本仍是2005年发布、2006年实施的、跟进至扩展B区的GB18030-2005——就在今天(3月10日),CJKUI扩展G区已经正式发布了。GB18030-2010虽在2018年7月即已完成WTO备案,但至今未正式发布。这就是国内大多数电脑的系统字体只能支持到扩展B区汉字的原因。
(2) 国内各机构之间不愿分享成果,只限于满足自身需求,且国内通用PUA体系不完善。
如果说在正式编码之前的时间,国内的通用PUA体系比较完善,对相关人员的输入培训到位的话,仍然不会影响到大多数人的生活——这虽然不符合标准,至少实用。但令人遗憾的是,虽然在2004年左右方正公司就基本建成了所谓的公安局字库,但这一字库至今仍未能同有需求的各机构共用且同步更新。更令人大为不解的是,严格来说,这个字库还是涉密的,或者说,公开其使用的PUA码位属于泄密行为。
2
在这里还必须说明另一个问题。见于各类报道的生僻字输入问题有一部分是无法共用公安局字库导致的,还有一部分是因为相关机构培训失职或者故意不作为导致的:因为方正的这套字体是配有输入法的[4],公安部、计划生育委员会、国家税务总局、劳动和社会保障部以及国家民政部下属部门应该都配有这套字体以及输入法。除此之外,确实有公安局字库缺收的情况,属于极少数[5]。
值得注意的是,2017年两会期间,全国政协委员、中国科学院大连化学物理研究所洁净能源国家实验室主任李灿即提交了《关于解决姓名中含有生僻字人员办证难问题的提案》,对此,工业和信息化部也进行了回应(www.miit.gov.cn)
就在去年(2019年),全国人大代表、江西铜业集团有限公司德兴泗洲选矿厂主任工程师谢建辉又提交了“尽快解决姓名中含有生僻字人员办事难的问题”建议[6]。但迄今为止,公安及民政等部门还是没有将字库与其它有需求的机构同步,受影响的群众办事依旧很难。相关部门似乎有一种改变的惰性。
表面上来看,这种现象是相关机构的学者或者负责人的保守和短视所致的。拿地名用字来说,在国内,至少测绘和地理信息系统有一套很全的地名生僻字信息、民政及公安系统有一套很全的地名生僻字信息。我曾经联系过测绘系统的一位专家,希望能获得《地名库外字代码对照表》全文,联系了几次,他的大意也基本都是:这是我们项目的成果,属于保密内容,不便全部提供;当初没有提交的原因则是提交周期太长,于满足机构自身的使用需求及项目无益。这种现象在国内普遍存在。但是信息共享才能共赢,闭门造车只能双输。这种对项目成果过分保密的行为常会导致很多完全不必要的重复性建设以及更多报复性的信息封闭行为,从而形成恶性循环。不论是公安系统或是测绘系统,都完全可以公开生僻字相关的资料,但是十多年以来,没有一方这样做。
(3)推动解决人名和地名用生僻字输入问题解决的社会力量太弱,很多人仍未意识到“堵不如疏”
虽然受到此问题影响的人数可能多至百万甚至千万级,但相对于全国人来说,他们仍然是少数。鲁迅先生说过,人类的悲欢并不相通——确实,我们很难感受处于不同状况的他人的情绪。再加上大多数成人在经历过社会的磨砺后,换位思考的能力和同情心逐渐缺失,更加在意自己生活的安稳,很少有非当事人愿意为此事发声。很多当事人也因为担心发声会给自己造成不要的麻烦,或经过长期的努力也看不到任何改观而放弃,这就进一步削弱了推动解决此问题的社会力量。
另外,还有一种声音认为应该强制禁止在人名或者地名中使用生僻字,已有的也应该强制更改。且不说这种态度非常不人性化[7],已有的经验也已经证明这是不可能的:第一次地名普查的时候多地即要求“地名中不能使用《新华字典》和《现代汉语词典》中没有收录的汉字”,但从现在的结果来看,首先是很多地名改了之后已经变成了纯符号,文化意味全部消失;其次,因为中国疆域广阔、聚落众多,各地状况不一,不可能将所有小地名中的生僻字全部改掉。我们已经在一普地名志和现行名称的对比中发现过:
①没说改,改了的;
②说没改,改了的;
③说改了,没改的;
④啥都没说,假装没看见的;
⑤啥都没说,确实没看见的;
⑥正式名称改了的,民间仍然通用旧字的;
⑦一个县都给异体A改成异体B,另一个县都给异体B改成异体A的;等等。

总之千奇百怪的情况都有。可以想到,不一致情况最严重的就是自然村级别的聚落名,而现在很多仍保存生僻字地名的自然村地处偏僻,甚至根本没有文献资料记载,给资料搜集造成很大困难。无法输入地址给本来就相对远离现代科技和社会的居民们雪上加霜。他们要么被迫同意更名,要么承受着本不应有的诸多不便。要让14亿人都把名字改到符合要求,又何其难哉。所以综上,堵不如疏——我们在大禹时代就已经有了这种哲学。
(4)Unicode标准在国内知名度低,从事汉字编码工作的专家数量过少,无论是国家、社会还是机构和个人,普遍都不重视汉字编码工作。
Unicode标准在国内知名度低的原因大概可以归纳为以下三点:
a. 客观上来说,Unicode标准本身的基础性、专业性决定了它没必要,也不可能为很多人所理解。
从基础性上来说,就好比每个人都会看电视,但绝对没必要弄清每一个零件的原理;从专业性上来说,要充分理解Unicode标准体系的相关概念,需要很多知识作为基础——从事汉字编码工作更是需要海量的计算机科学、语言学、汉字学和信息检索等方面的知识。同时,越专业、越冷门的东西相对于普通人来说越枯燥,也就越曲高和寡[8][9]。
b. 介绍Unicode标准的汉语资料太少;从事标准制定的专家对标准不够了解,且对汉译工作的重要性和紧迫性认识不足。
Unicode标准体系及相关技术或标准在世界范围内也属于极冷门的研究范畴,本来参与者也不多,但现在国内的情况是:即使是从事编码工作的专家,也基本没有人对Unicode标准体系、甚至是汉字编码体系有中等程度的了解;相关的汉语资料极少,质量普遍偏低,更是出现了《计算机字符编码——Unicode 与 Windows》这种神级烂书[10]。对绝大多数汉语母语者来说,接受汉语材料包含的信息远比英语材料要快速、高效得多,所以缺少汉语资料会让充分理解Unicode标准的人大幅减少,从而通过他们的介绍、科普而了解Unicode标准的人更大幅度地减少。所以我认为,介绍Unicode标准的高水平汉语资料缺失是Unicode标准在国内知名度低的根本原因。
可以说,Unicode标准体系是计算机软件方面最基础的标准之一,充分理解Unicode标准体系及其理念是在相关领域做出突破性创新的基础;以Unicode标准为基础的各种标准和技术正不断发展,充分理解Unicode标准体系及相关标准同编程、字体技术、排版技术、输入法、语言学等的关系已变得十分必要。但令我惊讶的是,国内很多从事字符编码标准制定工作的人都认为翻译著述“没有必要”或“价值不大”。
c. 国内媒体对相关问题的宣传不够。
其实,要弄懂Unicode标准的基本原理并不难,但我们接触到的大多数媒体人貌似不了解,也不想了解:很多记者即使不顾正确性,也不愿意改变自己的宣传倾向。比如,经人介绍(十分感谢),天津大学新闻部的老师曾经找到过我,询问有关地名用字编码工作的情况。当初做八辅字情调查的时候,我们曾经用开源字体的现成部件拼凑过一款使用了PUA来显示未编码字的字体,不论我怎么解释,那位老师就是认为制作字体这件事很值得宣传,对我花费了近一年时间所做的资料总结[11]和提交至各提交源的提案丝毫不感兴趣。最后,她再也没找到过我,我也从没联系过她。这种事情不是孤例,我们甚至都已习惯。
在这里还要说明一点,宣传力度不够也不能完全“归咎”于媒体人。因为字符编码国际标准的制定是完全公益性的,所以从事标准制定工作的专家一般都对名利不太感兴趣。但换个角度来说,他们往往不能很好地应对公众舆论,不适合充当公众人物,所以一般都会拒绝出镜。由此便形成了一个尴尬的局面:汉字编码工作很需要得到宣传,而能否得到宣传很大程度上取决于记者,拒绝出镜又常会打消他们的积极性。
因为Unicode标准知名度低、推动解决人名和地名生僻字解决的社会力量又很弱,所以从事汉字编码工作的专家数量非常少;国家、社会对此普遍不重视,愿意为这些专家提供证据的人也不多。我们中的某位专家在实地调查地名生僻字的时候,甚至差点被当成骗子轰出村去。
很多人都问过我们这个问题:为什么这个字这么常见,竟然还没编码?为了回答这个问题,不妨假设有1000人每天花10小时在各类文献里找未编码字,每人每分钟浏览500字;仅一部四库全书即有10亿字,其它各类文献总字数按其千倍计,由此可算得,他们检查完全部的资料需要约9年。实际上,大陆常态化参与汉字编码工作的专家不到20人;上文也提到,汉字编码工作完全是公益性的,参与者不仅无法因此得益,还常常要付出大量钱和时间,所以不可能有人全职做编码工作;同时,未编码字的总体罕用度越来越高,寻找资料所耗费的精力也越来越大。如果没有人向我们提供资料,错过浩如烟海的文献中的任何一个非通用字都不足为奇。即使有中华字库等大型项目支持,汉字提交的速度也不可能太快。
(5)国内相关机构或积极性、专业性不足,或对困难考虑的不够全面,或是过于依赖某位特定的领导,致使对项目的支持往往不能贯穿始终,从而产生烂尾工程。
这一节,我想以两个著名项目为例谈一谈这种情况。
首先,以中华字库为例:
①其字库的字体文件占用了Unicode标准字符集扩展E区之后的部分,因为当时认为CJKUI在扩展E区之后不会再发布新的扩展集,而提出这一论断的竟然是中国大陆源的前任Editor;
②由方正公司承制的中华字库第17包(当代人名地名用字收集与整理)也不尽人意,首先,它把书写习惯引起的微小差异和不小心写错的字都收进了字库;其次,其中过时和不准确之处颇多。
③中华字库项目于2006年立项,原预计5年内完成,结果复杂程度远超想象。古琴谱、算筹符号和部分少数民族语言文字等至今为止仍未找到有效的编码方案。幸运的是,中华字库项目没有中途夭折,仍然有一群有理想的人为此工作着。项目组现已完成古籍中汉字字形的整理工作,正在清删字形、核对错误。
但中国·国家地名信息库就没有如此幸运了。看到这个字体文件,我虽然难隐笑意,但仍难以相信这个字体是花了那么多钱的一个国家项目的成果:

它的“审音定字”栏目,收字相比缺字甚至可以忽略不计[12],反映出其整体水平有多糟糕:
那么,中国·国家地名信息库何以至此呢?
首先,第二次地名普查因为工作外包等原因,从事基础工作的人不专业且缺少责任感,造成二普志书与现实脱节。很多二普地名志有海量的错误、遗漏,参考价值很低。而中国·国家地名信息库正是以第二次全国地名普查的资料为基础编制的。再加上对项目困难预料不足,原项目负责人离开岗位,最后只能草草结项,是非常典型的烂尾工程[13]。
有的学者可能听到过XX专家在XX会议上谈到过更新电脑字库的事情,而且看起来很重视相关问题。对此,我想说:任何脱离编码标准谈升级电脑字库的行为都是耍流氓、故弄玄虚。如果有学者大讲特讲升级电脑字库的必要性而丝毫不提编码标准,那只不过是为了丰富自己的议论喊喊口号而已,实际上根本不懂问题的实质。
(6) IRG部分审批流程条理不清晰、效率不高,在语言学或者汉字学问题上过于纠缠
在现在IRG的日常工作中,“文科思维”有占主流的趋向,对字义、字理、汉字归部的讨论占用时间越来越多——我当然不是说文科思维不好,作为国际标准的一部分,审核过程谨慎、严格是必须的;对于CJKUI,在编码之前对字的音、义、源进行考证更是十分必要。但总的来说,这毕竟是一个计算机科学范畴的国际标准,全用文科思维处理工程技术问题不合适,在语言学或者汉字学上过于纠缠意义不大。拿汉字归部的问题来说,有的专家认为应优先按字义进行归部,有的专家认为有争议的字应一字归两部,我认为都不可取。对于计算机处理来说,一个集合到另一个集合的映射是相对简单的,像Unicode标准这种基础性的标准更应该在各方面遵守此规则。所以对于生僻字归部问题,尤其是涉及到字理常人难以理解的壮字、喃字时,我认为有必要:采取略显“粗暴”、程式化的规则处理,规则以外的特例特审;单独定义编码意义上的“部首”,而不必拘泥于本身就存在争议的汉字学上的“部首”。如果能将这种理念应用于IRG审批流程的其他方面,应该可以在一定程度上减轻IRG的负担、提高工作效率。
读到这里,你可能已经开始归纳:上述各种状况相互作用,形成强烈的负反馈,或者说,恶性循环,所以导致此问题长期无法解决。但我认为这还不是最根本的原因。
2
地名及人名用字输入问题无法解决的根本原因
一个人要完成一件事情,至少需要以下三种动力之一:因为利益产生的动力、因为信念产生的动力、被强力逼迫产生的动力。让各类机构完成一件事情也是类似的,需要不断的利益驱动力、信念理想驱动力或者是被形势逼迫产生的驱动力。但现在无论是掌握资源的各机构,或是应该负责的政府部门、字库有升级必要的各机构仿佛都有一种无形的惰性,这反映出致其行动的三种驱动力均不足。
(1)解决问题所产生的利益不足,甚至没有利益产生
前文已经说明过,实际受影响的人只占总人口很小的一部分,他们的力量很弱,所以解决他们的问题获得的经济或名誉利益也就很少。对此,某输入法的负责人表达得非常直白:“用的人少,何必麻烦[14]。”
对于有必要同公安及民政等部门同步字库的机构来说,以银行系统为例,更新整个系统所有电脑的字库,同时可能还要升级硬件和软件、培训业务员,其所消耗的经济成本要远远大于因解决生僻字输入问题所产生的经济效益。更多的机构不会因此产生经济收入,所以从经济上来说,各机构有更新字库的惰性。另外,对于掌握相关资料的机构来说,公开资料意味着放弃一部分资料的版权,这些资料最开始也是他们用真金白银、从无到有积累的,公开其中的生僻字资料,不仅需要支付整理资料所产生的费用,还会在日后丧失一定讨价还价的资本。
除此之外,利益因素对IRG专家也不是没有影响。虽然大多数IRG专家不那么在乎个人利益得失,但是对于某些IRG专家来说,不足的物质基础会让他们更加看中自己在编码工作中的作用,甚至把这看成是他们实现人生意义的主要方式。他们为此做出的牺牲是值得尊敬的,从整体来看,起到的作用也是非常积极的,但是如果将个人实现的情绪带入日常工作中,就会与国际标准所应具有的国际性和公益性产生冲突,对纯学术氛围造成潜移默化的影响。
可以毫不夸张地说,国内很多从事汉字编码工作的专家完全可以利用他们的能力获得比现在多一倍甚至几倍的薪酬和名望,但他们仍然甘之如饴。即使是做出这样的牺牲,他们还是很难被人理解,经常被泼一身冷水。这往往是很“诛心”的,对人内心好的方面伤害很大。
(2)相关机构为人民服务意识的集体缺失
公安部门经常建议不用生僻字取名[15],很多媒体也鼓吹宣传。这体现的其实是相关机构为人民服务思想的集体缺失。这也很容易理解:当一个规则为人民的利益而改,官员为人民的利益而动,是谓为人民服务;如果制定规则,方便管理而损害人民的利益,是让人民为规则服务。如果说地名用字问题还可以通过查找资料解决,人名用字除了政府提交外几无他法。然而现在的情况是,测绘、公安及民政部之间的数据相互保密,甚至有一些属于“涉密”资料,既不公开也不积极提交编码。究其原因,不过是利益驱动力不足,又缺乏为人民服务的精神,相关机构就拿保密做挡箭牌躺下而已。在这个问题上,相关机构的负责人躺的太舒服了。
但如果再深究,他们缺失为人民服务的意识是不是只是他们自身的错,我认为也不尽然。
(3)言论表达受到了过分限制,很多项目过于依赖单个领导
中国在近代已经吃尽了保守的亏,但这种保守的执念似乎仍在当代继续。尤其是近段时间,很多国人的思想更趋保守,从而形成改变的强烈惰性。众所周知,自由是学术的生命,但国内的很多研究是没有生命、没有生气的,从而也不可能提出有创见性的观点、无法发现问题。再加上很多当事人因为担心对自己产生不利影响而不敢发声,少量敢于发声的当事人也大多因为其言论得不到有效传播、看不到改变的迹象而放弃。这就造成了问题似乎并不严重的假象——看不到问题,又何谈解决?所以还是那句话,堵不如疏。
另外一个人不可能洞察所有领域,如果某个机构的领导者不熟悉相关领域,又没有开明的态度,往往会导致正确的建议得不到及时采纳,产生长期无法逆转的影响。汉字编码属于极冷门研究范畴的子范畴,推动问题解决的声音又小,所以这个问题很难得到“上级”的重视且不能形成强烈的舆论力量以倒逼相关机构进行改进。
3
结语
我在之前的文章中提到过,汉字与拼音文字不同:对于拼音文字来说,只要编码少量字母和符号,就可以记述其所有文献;而汉字数量众多,很难统计穷尽。换句话说,相比于拼音文字语言,汉字编码的发展程度会在更大程度上影响今后汉语文本的信息化能力,这又在一定程度上决定了汉语文化圈在信息时代的文化竞争力。只要让专业人员去做,收集未编码字并不像想象中的那么难。即使花个十几年、几十年,也比让百万人甚至千万人适应几十年要好。但就目前的状况来看,由于第2节中提到的状况无法在短时间内得到改观,汉字编码工作仍会长期得不到国家和社会的重视,地名、人名用生僻字输入困难的问题在国内仍是短期,甚至是中长期内无法解决的。虽然有很多人在为解决这一问题默默努力,但是他们的力量太小,根本无法改变现状——比如,本文不会被多少人看到,也没有多少人愿意读完如此冗长乏味的一篇文章,甚至不能原封不动地发出去。
参考1.中国电子技术标准化研究所、国家测绘局地名研究所(隶属中国测绘科学研究院)和合力金桥公司(今北京合力金桥软件技术有限公司)起草的,中华人民共和国信息工业部于 2001 年 12 月 28 日发布的字集标准文件,用于满足地名信息处理的特殊需求。
2.包括其它提交方提交的字形恰好和《八辅》中字形完全一致或者可认为是同一字的情况。
3.我倾尽全力,一年不过也只找到了几百个地名用字的提交资料而已,这还是既有针对性地清理资料的结果。剩下的字分散出现于更稀见的资料中,这几乎是不可能的。
4.ab方正字库——人口信息冷僻字解决方案:http://www.foundertype.com/index.php/About/solvePersonName.html
5.《可信地名外字证据征集(未竟)》中的「⿲米田米」: https://zhuanlan.zhihu.com/p/44576181
6.http://www.myzaker.com/article/5c8760ac77ac647e524824ea
7.这是上文所说的“人类的悲欢并不相通”非常鲜明的体现,国内同性恋、亚文化群体、特殊性癖者、残疾人等边缘人群的处境更是充分体现了这一点。“正常人”们无法以相同的感情回路感受到他们的喜怒哀乐,所以高傲地视其为异端。
8.问题“有哪些来源奇特的地名?”下我的回答,32赞:https://www.zhihu.com/question/27825456/answer/276125324
9.八辅字情调查中期报告-字数统计、字形差异处理、字体情况: https://zhuanlan.zhihu.com/p/33938594
10.问题“你读过哪些不值得一读的烂书?它们分别烂在哪里?”下Kushim Jiang的回答:https://www.zhihu.com/question/60921684/answer/313001979
11.《八辅字情调查表》: https://zhuanlan.zhihu.com/p/34207648
12.未收字数量统计可以参考上文。中国·国家地名信息库“审音定字”栏目下绝大多数都是已编码字。
13.本句信息来源不一定可靠。
14.《【技术贴】快速输入生僻字》: https://zhuanlan.zhihu.com/p/43378578
15.可以以“警方 不用生僻字取名”为关键词在百度上搜索
地名词典 地名志条目的标示问题
北京地名罗马化拼写的谬误
天津胡同命名理据
地名分类与类别代码编辑规则
我国河流名称变迁的规律及成因

作者:王谢杨
编辑:华丽 黄海红 耿曈
终校:耿曈
审订:王谢杨
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






