什么事反向传播算法(反向传播算法过程)
自从机器学习被引入到递归的非线性函数中(例如人工神经网络)以来,对相关内容的应用得到了充足的发展。在这种情况下,训练正确的神经网络是建立可靠模型最重要的方面。这种训练通常与”反向传播”一词联系在一起,这个术语对大多数新手来说是非常模糊的。这也是本文所存在的意义。
反向传播是神经网络训练的本质。它实际上是基于在前一历元(即迭代)中获得的误差率(即损失)对神经网络的权重进行微调的实践。适当的调整权重可确保较低的错误率,增加模型的适用性使模型更可靠。
那么这个过程如何运作的呢?让我们通过例子学习!
为了使这个例子尽可能便于大家理解,我们只涉及相关概念(例如损失函数、优化函数等)而不解释它们,因为这些主题值得我们另起一篇文章进行细说。
首先,让我们设置模型组件
想象一下,我们需要训练一个深层神经网络。训练的目的是构建一个模型,该模型使用两个输入和三个隐藏单元执行XOR(异或)函数,这样训练集看起来如下所示:

此外,我们需要一个激活函数来确定神经网络中每个节点的激活值。为简单起见,让我们选择一个激活函数:

我们还需要一个假设函数来确定激活函数的输入是什么。这个函数是:

让我们选择损失函数作为逻辑回归的一般成本函数,看起来有点复杂,但实际上相当简单:

此外,我们将使用批处理梯度下降优化函数,用于确定我们应该调整权重的方向,以获得比我们现有的更低的损失。最后,学习率为0.1,所有权重将初始化为1。
我们的神经网络
让我们最后画一张我们期待已久的神经网络图。它应该看起来像这样:
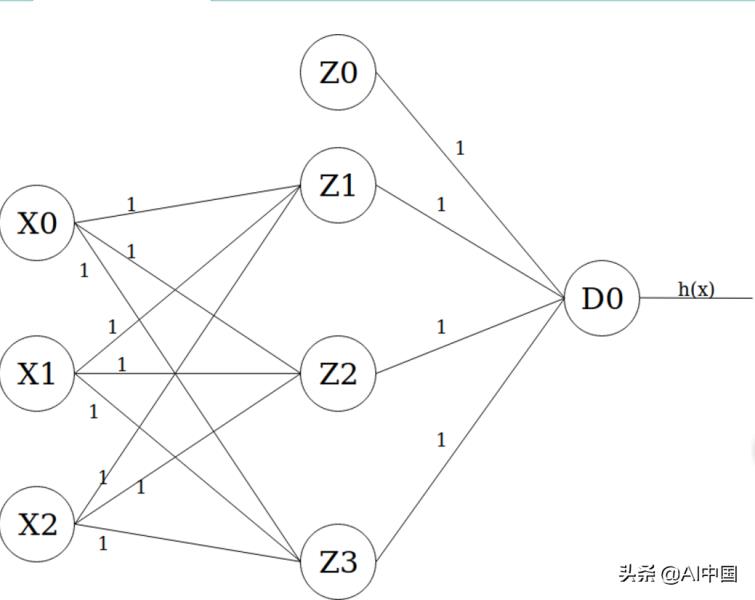
最左边的层是输入层,它将X0作为值1的偏置项,将X1和X2作为输入特征。中间的层是第一个隐藏层,它的偏置项Z0也取值为1。最后,输出层只有一个输出单元D0,其激活值是模型的实际输出(即h(x)) 。
现在我们向前传播
现在是将信息从一个层前馈到另一个层的时候了。这需要经过两个步骤,通过网络中的每个节点/单元:
1. 使用我们之前定义的h(x)函数获取特定单位输入的加权和。
2.将我们从步骤1得到的值插入我们的激活函数(本例中为f(a)= a)并使用我们得到的激活值(即激活函数的输出)作为连接输入特征的下一层中的节点。
请注意,单位X0,X1,X2和Z0没有任何连接到它们并任提供输入的单位。因此,上述步骤不会出现在这些节点中。但是,对于其余的节点/单元,训练集中第一个输入样本的整个神经网络都是这样的:

其他单位也是如此:


如前所述,最终单位(D0)的激活值(z)是整个模型的激活值(z)。因此,我们的模型预测输入集{0,0}的输出为1。计算当前迭代的损失/成本如下:

actual_y值来自训练集,而predict_y值是我们模型产生的值。所以这次迭代的成本是-4。
那么反向传播在哪里呢?
根据我们的例子,我们现在有一个模型没有给出准确的预测(它给我们的值是4而不是1),这归因于它的权重尚未调整(它们都等于1)。我们也有损失,即-4。反向传播就是以这样一种方式向后传递这种损失,我们可以根据这种方式微调权重。优化函数(在我们的例子中为梯度下降)将帮助我们找到权重。那就让我们开始吧!
使用以下功能进行前馈:


然后通过这些函数的偏导数发生反向反馈。不需要经过经过推导这些函数的过程。我们需要知道的是,上面的函数将遵循:

其中Z是我们从前馈步骤中的激活函数计算中获得的z值,而delta是图层中单位的损失。
我知道有很多信息一次性就能吸收,但我建议你花点时间,真正了解每一步发生了什么,然后再继续前进。
计算增量
现在我们需要找到神经网络中每个单元/节点的损耗。这是为什么呢?我们这样想,深度学习模型到达的每一次损失实际上是由所有节点累积到一个数字引起的。因此,我们需要找出哪个节点对每层中的大部分损失负责,这样我们就可以通过赋予它更小的权重值来惩罚它,从而减少模型的总损失。
计算每个单元的增量可能会有问题。但是,感谢吴恩达先生,他给了我们整个事情的捷径公式:

其中delta_0,w和f’(z)的值是相同单位的值,而delta_1是加权链接另一侧的单位损失。例如:

你可以这样想,为了获得节点的损失(例如Z0),我们将其对应的f’(z)的值乘以它在下一层(delta_1)连接的节点的损失,再乘以连接两个节点的链路的权重。
这正是反向传播的工作原理。我们在每个单元进行delta计算步骤,将损失反向传播到神经网络中,并找出每个节点/单元的损失。
让我们计算一下这些增量!

这里有一些注意事项:
- 最终单位的损失(即D0)等于整个模型的损失。这是因为它是输出单位,它的损失是所有单位的累计损失,就像我们之前说的那样。
- 无论输入(即z)等于什么,函数f’(z)总是给出值1。这是因为如前所述,偏导数如下:f’(a)= 1
- 输入节点/单位(X0,X1和X2)没有delta值,因为这些节点在神经网络中无法控制。它们仅作为数据集和神经网络之间的一个链接。
更新权重
现在剩下的就是更新我们在神经网络中的所有权重。这遵循批量梯度下降公式:

其中W是手头的权重,alpha是学习率(在我们的例子中是0.1),J’(W)是成本函数J(W)相对于W的偏导数。再次强调,我们不需要进行数学运算。因此,让我们使用吴恩达先生的函数的偏导数:

其中Z是通过前向传播获得的Z值,delta是加权链接另一端的单位损失:

现在用我们在每一步获得的偏导数值,和批量梯度下降权重更新所有权重。值得强调的是,输入节点(X0,X1和X2)的Z值分别等于1,0,0。1是偏置单元的值,而0实际上是来自数据集的特征输入值。最后要注意的是,没有特定的顺序来更新权重。你可以按照你想要的任何顺序更新它们,只要你不会在同一次迭代中错误地更新任何权重两次。
为了计算新的权重,让我们给出神经网络名称中的链接:

新的权重计算方法如下:


需要注意的是,模型还没有正确训练,因为我们只通过训练集中的一个样本进行反向传播。我们为样本做了所有我们能做的一切,这可以产生一个具有更高精度的模型,试图接近每一步的最小损失/成本。
如果没有正确的方法,机器学习背后的理论真的很难掌握。其中一个例子就是反向传播,其效果在大多数现实世界的深度学习应用程序中都是可以预见的。反向传播只是将总损耗传回神经网络的一种方式,以方便人们了解每个节点的损失量,并随后通过为节点提供更高误差,进而使用损失最小化的方式来更新权重,反之亦然。
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com