吴恩达深度学习书(吴恩达深度学习笔记)
你已经了解了基础的RNN模型的运行机制,在本节中你将会学习门控循环单元,它改变了RNN的隐藏层,使其可以更好地捕捉深层连接,并改善了梯度消失问题,让我们看一看。

你已经见过了这个公式,
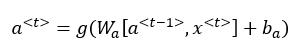
a^(<t>)=g(W_a [a^(<t-1>),x^(<t>) ] b_a),在RNN的时间t处,计算激活值。
我把这个画个图,把RNN的单元画个图,画一个方框,输入a^(<t-1>)(上图编号1所示),即上一个时间步的激活值,再输入x^(<t>)(上图编号2所示),再把这两个并起来,然后乘上权重项,在这个线性计算之后(上图编号3所示),如果g是一个tanh激活函数,再经过tanh计算之后,它会计算出激活值a^(<t>)。
然后激活值a^(<t>)将会传softmax单元(上图编号4所示),或者其他用于产生输出y^(<t>)的东西。就这张图而言,这就是RNN隐藏层的单元的可视化呈现。我向展示这张图,因为我们将使用相似的图来讲解门控循环单元。


许多GRU的想法都来分别自于Yu Young Chang, Kagawa,Gaza Hera, Chang Hung Chu和 Jose Banjo的两篇论文。
我再引用上个笔记中你已经见过的这个句子,“The cat, which already ate……, was full.”,你需要记得猫是单数的,为了确保你已经理解了为什么这里是was而不是were,“The cat was full.”或者是“The cats were full”。
当我们从左到右读这个句子,GRU单元将会有个新的变量称为c,代表细胞(cell),即记忆细胞(下图编号1所示)。记忆细胞的作用是提供了记忆的能力,比如说一只猫是单数还是复数,所以当它看到之后的句子的时候,它仍能够判断句子的主语是单数还是复数。于是在时间t处,有记忆细胞c^(<t>),然后我们看的是,GRU实际上输出了激活值a^(<t>),c^(<t>)=a^(<t>)(下图编号2所示)。
于是我们想要使用不同的符号c和a来表示记忆细胞的值和输出的激活值,即使它们是一样的。我现在使用这个标记是因为当我们等会说到LSTMs的时候,这两个会是不同的值,但是现在对于GRU,c^(<t>)的值等于a^(<t>)的激活值。
所以这些等式表示了GRU单元的计算,在每个时间步,我们将用一个候选值重写记忆细胞,即̃c^(<t>)的值,所以它就是个候选值,替代了c^(<t>)的值。然后我们用tanh激活函数来计算,̃c^(<t>)=tanh(W_c [c^(<t-1>),x^(<t>) ] b_c),所以̃c^(<t>)的值就是个替代值,代替表示c^(<t>)的值(下图编号3所示)。

重点来了,在GRU中真正重要的思想是我们有一个门,我先把这个门叫做Γ_u(上图编号4所示),这是个下标为u的大写希腊字母Γ,u代表更新门,这是一个0到1之间的值。
为了让你直观思考GRU的工作机制,先思考Γ_u,这个一直在0到1之间的门值,实际上这个值是把这个式子带入sigmoid函数得到的,Γ_u=σ(W_u [c^(<t-1>),x^(<t>) ] b_u)。
我们还记得sigmoid函数是上图编号5所示这样的,它的输出值总是在0到1之间,对于大多数可能的输入,sigmoid函数的输出总是非常接近0或者非常接近1。
在这样的直觉下,可以想到Γ_u在大多数的情况下非常接近0或1。然后这个字母u表示“update”,我选了字母Γ是因为它看起来像门。还有希腊字母G,G是门的首字母,所以G表示门。
然后GRU的关键部分就是上图编号3所示的等式,我们刚才写出来的用̃c更新c的等式。然后门决定是否要真的更新它。于是我们这么看待它,记忆细胞c^(<t>)将被设定为0或者1,这取决于你考虑的单词在句子中是单数还是复数,因为这里是单数情况,所以我们先假定它被设为了1,或者如果是复数的情况我们就把它设为0。然后GRU单元将会一直记住c^(<t>)的值,直到上图编号7所示的位置,c^(<t>)的值还是1,这就告诉它,噢,这是单数,所以我们用was。于是门Γ_u的作用就是决定什么时候你会更新这个值,特别是当你看到词组the cat,即句子的主语猫,这就是一个好时机去更新这个值。然后当你使用完它的时候,“The cat, which already ate……, was full.”,然后你就知道,我不需要记住它了,我可以忘记它了。

所以我们接下来要给GRU用的式子就是c^(<t>)=Γ_u*̃c^(<t>) (1-Γ_u )*c^(<t-1>)(上图编号1所示)。你应该注意到了,如果这个更新值Γ_u=1,也就是说把这个新值,即c^(<t>)设为候选值(Γ_u=1时简化上式,c^(<t>)=̃c^(<t>))。将门值设为1(上图编号2所示),然后往前再更新这个值。
对于所有在这中间的值,你应该把门的值设为0,即Γ_u=0,意思就是说不更新它,就用旧的值。因为如果Γ_u=0,则c^(<t>)=c^(<t-1>),c^(<t>)等于旧的值。甚至你从左到右扫描这个句子,当门值为0的时候(上图编号3所示,中间Γ_u=0一直为0,表示一直不更新),就是说不更新它的时候,不要更新它,就用旧的值,也不要忘记这个值是什么,这样即使你一直处理句子到上图编号4所示,c^(<t>)应该会一直等c^(<t-1>),于是它仍然记得猫是单数的。
让我再画个图来(下图所示)解释一下GRU单元,顺便说一下,当你在看网络上的博客或者教科书或者教程之类的,这些图对于解释GRU和我们稍后会讲的LSTM是相当流行的,我个人感觉式子在图片中比较容易理解,那么即使看不懂图片也没关系,我就画画,万一能帮得上忙就最好了。
GRU单元输入c^(<t-1>)(下图编号1所示),对于上一个时间步,先假设它正好等于a^(<t-1>),所以把这个作为输入。然后x^(<t>)也作为输入(下图编号2所示),然后把这两个用合适权重结合在一起,再用tanh计算,算出̃c^(<t>),̃c^(<t>)=tanh(W_c [c^(<t-1>),x^(<t>) ] b_c),即c^(<t>)的替代值。
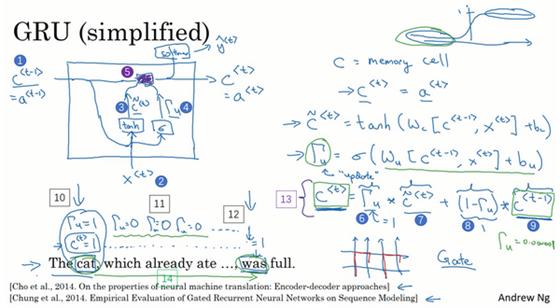
再用一个不同的参数集,通过sigmoid激活函数算出Γ_u,Γ_u=σ(W_u [c^(<t-1>),x^(<t>) ] b_u),即更新门。最后所有的值通过另一个运算符结合,我并不会写出公式,但是我用紫色阴影标注的这个方框(下图编号5所示,其所代表的运算过程即下图编号13所示的等式),代表了这个式子。所以这就是紫色运算符所表示的是,它输入一个门值(下图编号6所示),新的候选值(下图编号7所示),这再有一个门值(下图编号8所示)和c^(<t>)的旧值(下图编号9所示),所以它把这个(下图编号1所示)、这个(下图编号3所示)和这个(下图编号4所示)作为输入一起产生记忆细胞的新值c^(<t>),所以c^(<t>)等于a^(<t>)。如果你想,你也可以也把这个带入softmax或者其他预测y^(<t>)的东西。
这就是GRU单元或者说是一个简化过的GRU单元,它的优点就是通过门决定,当你从左(上图编号10所示)到右扫描一个句子的时候,这个时机是要更新某个记忆细胞,还是不更新,不更新(上图编号11所示,中间Γ_u=0一直为0,表示一直不更新)直到你到你真的需要使用记忆细胞的时候(上图编号12所示),这可能在句子之前就决定了。
因为sigmoid的值,现在因为门很容易取到0值,只要这个值是一个很大的负数,再由于数值上的四舍五入,上面这些门大体上就是0,或者说非常非常非常接近0。
所以在这样的情况下,这个更新式子(上图编号13所示的等式)就会变成c^(<t>)=c^(<t-1>),这非常有利于维持细胞的值。因为Γ_u很接近0,可能是0.000001或者更小,这就不会有梯度消失的问题了。因为Γ_u很接近0,这就是说c^(<t>)几乎就等于c^(<t-1>),而且c^(<t>)的值也很好地被维持了,即使经过很多很多的时间步(上图编号14所示)。这就是缓解梯度消失问题的关键,因此允许神经网络运行在非常庞大的依赖词上,比如说cat和was单词即使被中间的很多单词分割开。

现在我想说下一些实现的细节,在这个我写下的式子中c^(<t>)可以是一个向量(上图编号1所示),如果你有100维的隐藏的激活值,那么c^(<t>)也是100维的,̃c^(<t>)也是相同的维度(̃c^(<t>)=tanh(W_c [c^(<t-1>),x^(<t>) ] b_c)),Γ_u也是相同的维度(Γ_u=σ(W_u [c^(<t-1>),x^(<t>) ] b_u)),还有画在框中的其他值。这样的话“*”实际上就是元素对应的乘积(c^(<t>)=Γ_u*̃c^(<t>) (1-Γ_u )*c^(<t-1>)),所以这里的Γ_u:(Γ_u=σ(W_u [c^(<t-1>),x^(<t>) ] b_u)),即如果门是一个100维的向量,Γ_u也就100维的向量,里面的值几乎都是0或者1,就是说这100维的记忆细胞c^(<t>)(c^(<t>)=a^(<t>)上图编号1所示)就是你要更新的比特。
当然在实际应用中Γ_u不会真的等于0或者1,有时候它是0到1的一个中间值(上图编号5所示),但是这对于直观思考是很方便的,就把它当成确切的0,完全确切的0或者就是确切的1。元素对应的乘积做的就是告诉GRU单元哪个记忆细胞的向量维度在每个时间步要做更新,所以你可以选择保存一些比特不变,而去更新其他的比特。比如说你可能需要一个比特来记忆猫是单数还是复数,其他比特来理解你正在谈论食物,因为你在谈论吃饭或者食物,然后你稍后可能就会谈论“The cat was full.”,你可以每个时间点只改变一些比特。
你现在已经理解GRU最重要的思想了,幻灯片中展示的实际上只是简化过的GRU单元,现在来描述一下完整的GRU单元。
对于完整的GRU单元我要做的一个改变就是在我们计算的第一个式子中给记忆细胞的新候选值加上一个新的项,我要添加一个门Γ_r(下图编号1所示),你可以认为r代表相关性(relevance)。这个Γ_r门告诉你计算出的下一个c^(<t>)的候选值̃c^(<t>)跟c^(<t-1>)有多大的相关性。计算这个门Γ_r需要参数,正如你看到的这个,一个新的参数矩阵W_r,Γ_r=σ(W_r [c^(<t-1>),x^(<t>) ] b_r)。

正如你所见,有很多方法可以来设计这些类型的神经网络,然后我们为什么有Γ_r?为什么不用上一张幻灯片里的简单的版本?这是因为多年来研究者们试验过很多很多不同可能的方法来设计这些单元,去尝试让神经网络有更深层的连接,去尝试产生更大范围的影响,还有解决梯度消失的问题,GRU就是其中一个研究者们最常使用的版本,也被发现在很多不同的问题上也是非常健壮和实用的。你可以尝试发明新版本的单元,只要你愿意。但是GRU是一个标准版本,也就是最常使用的。你可以想象到研究者们也尝试了很多其他版本,类似这样的但不完全是,比如我这里写的这个。然后另一个常用的版本被称为LSTM,表示长短时记忆网络,这个我们会在下节中讲到,但是GRU和LSTM是在神经网络结构中最常用的两个具体实例。
还有在符号上的一点,我尝试去定义固定的符号让这些概念容易理解,如果你看学术文章的话,你有的时候会看到有些人使用另一种符号̃x,u,r和h表示这些量。但我试着在GRU和LSTM之间用一种更固定的符号,比如使用更固定的符号Γ来表示门,所以希望这能让这些概念更好理解。
所以这就是GRU,即门控循环单元,这是RNN的其中之一。
这个结构可以更好捕捉非常长范围的依赖,让RNN更加有效。然后我简单提一下其他常用的神经网络,比较经典的是这个叫做LSTM,即长短时记忆网络,我们在下节中讲解。
(Chung J, Gulcehre C, Cho K H, et al. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling[J]. Eprint Arxiv, 2014. Cho K, Merrienboer B V, Bahdanau D, et al. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches[J]. Computer Science, 2014.)
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com