人工智能数据中心英伟达(英伟达仿真模拟方法论助力无人驾驶算法开发)

为了不断给自动驾驶汽车提供海量数据和极端场景以满足安全测试的需要,仿真技术在近年来备受关注,众多仿真平台也应运而生。
在这种大背景下,英伟达将自己在图形计算时代所积累的优势复制到自动驾驶技术上,并且于 2019 年正式向客户开放 DRIVE Constellation 自动驾驶仿真模拟器。
那么,当下无人驾驶在预期功能安全方面的进展如何?英伟达在仿真验证方面有什么独特的见解?
雷锋网新智驾邀请了英伟达无人驾驶开发架构师杨健来进行业内分享。以下为杨健的演讲内容,雷锋网新智驾进行了不改变原意的整理:
大家好!我是英伟达无人驾驶解决方案架构师杨建,感谢新智驾提供的平台,让我们可以交流关于无人驾驶仿真方面的话题。
今天分享的主题为《英伟达仿真模拟方法论助力无人驾驶算法开发》,主要分为以下三个方面:
-
无人驾驶与预期功能安全;
-
英伟达仿真验证方法论;
-
解决问题需要的规模和计算量。
一、无人驾驶和预期功能安全
首先给大家解释一下 verification(验证)和validation(确认)的区别。
Verification,主要是验证结果是否与预期设计相一致,即“把事情做对”;validation,则是结果在与预期设计相一致的同时,确认预期设计是否有问题,是否能够满足客户的其他需求,即“做对的事情”。
目前,工业界有两种验证自动驾驶车辆安全的方法论。
一种是大家比较熟悉的ISO26262功能安全(FuSa),这种方法论旨在预防由汽车电子电气系统产生故障导致的意外风险隐患。
另一种是 ISO21448 预期功能安全(SOTIF),这种方法论旨在解决自动驾驶系统本身由于算法或者传感器(摄像头、激光雷达等)本身缺陷导致致命伤害事故的问题。这也是今天分享的重点。
从开发流程上来说,无论是 FuSa 还是 SOTIF,都要经历从需求定义到软硬件开发再到系统验证的过程,但相对来说,SOTIF 需要解决的问题难度更大。
就像长尾理论一样,容易造成事故的场景基本上出现在长尾的尾部,因此,我们很难预测这些问题将会在什么时候发生,而 SOTIF 就旨在去发现这些罕见的场景。
也就是说,SOTIF 可以发挥指导性的意义,把这种潜在的风险进行量化评估,从而评估车辆抵御风险的能力。
我们可以看一下这张图:
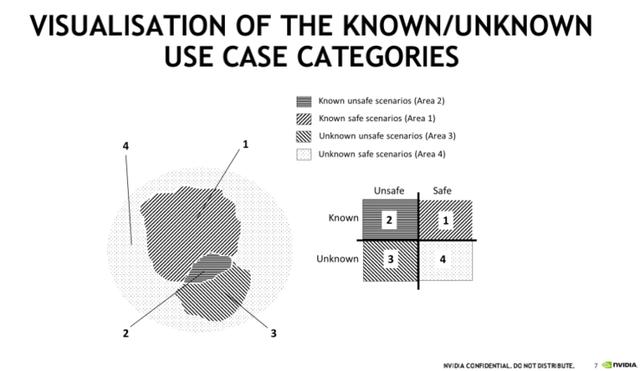
我们将所有场景分为4个区域,包括已知的安全场景、已知的不安全场景、未知的不安全场景以及未知的安全场景。
前面两个场景相对好理解,已知的不安全场景可以通过对 ODD 进行分析来解决相关的风险。由于最后一个场景的安全的场景,因此我们对它的关注度也不是很大。
最需要关注的是区域3,即未知的不安全场景,由于该场景中存在着巨大的风险,如果我们对其一直处于无法悉知的状态,我们就无法评估其中的风险会对无人驾驶带来多大的影响。
所以,在SOTIF 的开发流程中,针对已知的安全场景,我们可以通过概念定义阶段来对这些场景进行足够多的分析;针对已知的不安全场景,我们在验证阶段会去构建一些不安全的场景,然后对这些场景进行验证,确保无人驾驶算法可以安全地解决这些问题;对于为安全的未知安全场景,我们需要一些辅助的手段来帮助我们发现场景,了解场景。
也就是说,我们的最终目标就是把未知的不安全场景逐渐转化成已知的不安全场景,甚至是转化成已知的安全场景。
不过,从客观上来讲,未知的不安全场景肯定不会完全消失,但它最终会小到我们足以保证无人驾驶算法出现安全事故的概率会比真人驾驶要更小,也就是说,我们可以证明无人驾驶比真人驾驶要更安全。
二、英伟达的验证方法论
刚刚跟大家分享了英伟达对于 SOTIF 的理解,接下来给大家解释一下,我们针对上述一些问题的方法和方法论。
首先,我们把整个验证的测试过程分为几个步骤:
-
构建一个模拟器来运行可控的环境和场景;
-
软件在环仿真,对软件算法模块进行单元测试;
-
硬件在环仿真,把若干模块和模组整合进行系统测试;
-
之后在可控的封闭道路上做整体测试。
所以,我们可以把上述步骤分为两大类,即真实世界的测试里程,以及仿真环境里加速测试里程。这里的“加速”不仅是指时间上的加速,还包括了场景构建,或是其他变化的加速,从而获得更高质量的验证里程数。
从另一个维度来划分就是软件在环和硬件在环。一般来看,软件在环方面,无人驾驶算法开发都在 X86 平台上运行,因此模拟器也在相同的平台运行。硬件在环方面,英伟达与传统的主机厂有些不同。
传统上的硬件在环一般指的是 ECU -in-the-loop,相当于只有计算单元是真实的硬件。事实上,我们所说的硬件在环还包括了其他模拟出来的传感器和车辆控制器。
由于,测试对象运行在目标平台上,计算单元的算法需要验证的里程数巨大。所以,一套硬件并不能够满足需求,而是需要利用到 IT 行业已经非常成熟的并行化计算和集群化计算来提高仿真训练效率。
因此,这种仿真的硬件在环平台要能够部署到数据中心,然后构建成集群,然后使用集群调度管理工具来进行集群化并行化运行,这种测试的场景才有可能在有效的时间内完成海量的验证里程。
如此一来,硬件在环就可以做到比特级的准确,但它有一个缺点就是实时属性太强。
对此,英伟达推出了 drive constellation解决方案,这是一个虚拟的 AV 仿真硬件在环模拟器。
从整个仿真的结构来看,英伟达会把更多精力放在软件在环仿真上,通过单个软件模块或者多个模块进行验证;软件在环仿真验证之后就是硬件在环仿真,然后这一部分的仿真工作量相对减少;通过了硬件在环仿真验证,最后才会进入到路测阶段。
就工作量而言,我们认为 SIL一般占到60-70%,HIL在20% 左右,剩下的为路测。
关于“加速”,我还想进一步解释一下。

如图,在场景 A 当中,假设绿车是我们无人驾驶算法控制的车,然后有一辆汽车想要变道超车,一次性只变一个车道,这样的场景发生的概率很高,基本上每10公里就会发生一次;场景 B 中,这辆汽车在超车时跨越了两个车道,这种场景发生的概率相比前者低,大概每30公里发生一次。
将上述两个常见的场景参数进行一定的随机调整,就能衍生出变种的场景。比如场景 Ax和场景 Bx,这两种场景都十分罕见, 1 万公里可能才会发生一次,这也意味着这些场景更加危险,因为无人驾驶开发公司在路测时,不一定能收集到这样的场景。
通过这种随机参数化的方式来衍生出常规场景的变种场景,扩大测试的场景范围,才有可能进一步覆盖我们从未遇到过的风险。同时,我们可以在多个机器上一起并行测试,大大提升验证的效率。
那么,我们怎么样去应对诸如此类的场景变化?
正如上述提到的增加随机参数的方式,我们推出了一种类似 Python 脚本的高级场景定义语言 HSDL。通过这种语言我们可以定义一些简单的行为,然后通过组合方式,将它们结合成复杂的场景。目前,这种语言也在积极地为 ASAM OpenScenario 2.0 做贡献。
下图是我们基于一个场景,通过 HSDL 语言对该场景进行多次随机化变化生成的多个场景。在多次执行中,汽车的位置、所处的地形、面临的天气情况都不相同,许多的变化是我们在最开始编写场景时没有预料过的。

通过这种方式来不断地改进算法,提升无人驾驶算法的可靠性,最终形成开发流程的闭环。
三、计算规模的问题
涉及到随机的参数变化,我们就需要思考计算规模的问题。
从我们的经验来看,每个场景都需要经历多次随机变化才能保证覆盖,衍生出来的场景数量基本上是在10的二次方级别,当然也有可能更高。
那假如我们有 100 个基本测试场景,那么,总的需要测试的场景(加上衍生场景)大概有 100 万个。假如每个场景每次测试 15 秒,那么,总的测试时间大概在 40 万个小时左右。如果有 400 套像 Constellation 这样的设备,那么,就可以在 1000 个小时之内完成所有的验证任务。
如此大的计算规模需要在产品中加入数据中心的工作流程,帮助用户来解决大规模集群的调度工作,以及仿真验证任务的分发工作。
目前,英伟达已经研发了 drive constellation cloud集群化管理工具,用户首先可以提交任务,随后,系统会自动将这些任务切分,分发到集群中数百台机器上,同时进行运行。任务运行完以后,所有数据自动收集起来,然后存放到分布式存储中进行统一汇总,方便开发工程师取用。
最后我们来讨论一个问题。
目前,我们认为有两种主要的办法来对感知进行验证,一种是 Replay,即在路面采集的数据记录下来,然后在最终验证时进行回放;另一种是 Simulation。
前一种办法的优势就在于,这些收集到的数据都是来自真实世界里传感器的数据,时间准确度也比较好。但同样是因为这一点,我们没有办法控制输出的信号。也就是说,这种办法只能进行开环验证,基本上不能做闭环验证,而且成本也很高。
尽管 Simulation 在对真实世界的感知上不如 Replay,但它在很大程度上弥补了 Replay 的上述短板。为了让 Simulation 变得真实,英伟达已经开发了效果更佳的渲染引擎。
好,我今天给大家分享的内容就是这些,感谢大家。
接下来是 Q&A 环节:
1.激光雷达的反射值是怎么模拟的?
我们在构建静态场景的时候就会赋予物体一些材质属性,使得光线追踪算法可以模拟激光的物理反射。经过对物体材质属性的计算,最终我们可以得到一个相对准确的反射值,甚至可以模拟出同一个激光雷达的多次反射和接收。
2.传感器仿真的真实度如何评估?
我们会进行对比测试。通过神经网络模型直接来评估仿真图像的真实度,基本上是难以量化的。但我们可以通过神经网络模型或是其他算法,来间接评判我们仿真的真实度。如果仿真模型的特性与真实采集到的数据基本一致,那么传感器仿真的真实度就比较高。
3. 仿真的数据库场景从哪里来?
英伟达内部使用的数据场景库,一方面是基于我们对ODD的解析,比如在做无人驾驶的时候,针对定义的需求来构建场景;另一方面是来自一些公开的场景库,使用HSDL 语言将不同的场景随机组合起来,生成更多的场景。
4.如何保证交通流模拟,车辆轨迹和行为的仿真性?
简单来说也是通过 HSDL 语言来实现。但是由于每辆车的行为都是随机发生的,如果要确保这些行为的合理性,我们就要对随机变量的范围进行控制和调整。在一开始的时候,这个范围可能会过大或者过小,从而影响仿真的场景的真实性,所以,我们需要逐步优化这个过程,对随机参数进行手动的推理和调整。
5. 仿真场景中,哪些在 SIL中测,哪些在HIL中测?
我们的基本逻辑是,尽量在 SIL 中测,因为 SIL 跑得比较快,剩下一小部分有代表性的在 HIL 中测。所以,刚刚提到的通过 HSDL 语言合成的场景主要也是以 SIL 测试为主。 HSDL 的发布时间在很大程度上取决于今年下半年 ASAM OpenScenario 2.0 的推进情况。
6. 高精地图导入时怎么解决偏转的问题?
其实我们在推进项目的过程中确实遇到了偏转的问题,但由于英伟达是外资公司,很难拿到中国的无偏高清地图。所以,我们干脆不假设自己可以拿到无偏高精地图,我们会将中国特有的场景,以及一些影响驾驶的交通元素合成一个地图。尽管这个地图在真实世界不存在,但与驾驶相关的元素,比如说红绿灯,交通信号牌或车道线,都符合真实世界的法律法规,所以我们的项目得以正常推进。
雷锋网
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






