语音降噪测试(30分贝精准拾音90分贝超强降噪)

【新智元导读】你能想象的到,连蚊子飞过的声音也可以被录到吗?近期,某科技博主的一支关于拾音器的评测中,30分贝悄悄话的场景下,讯飞的谛听系列产品拾取的内容清晰,且音质听感较好,表现完全不输国际语音巨头森海塞尔、舒尔等。未来,谛听不仅仅停留于前端,还将成为链接各种智能图像、视频应用的纽带。
在法力即将耗尽之前,身受重伤的海姆达尔使用黑暗魔法将浩克传送回了地球。
《复仇者联盟3:无限战争》中,很多人都对这位彩虹桥的守护神印象深刻。作为雷神的好友,海姆达尔也在帮助「复联」的过程中被灭霸残忍杀害。

身为守护者,海姆达尔拥有极其敏锐的感官,他的眼睛可以看清数十亿光年外一只蝴蝶翅膀的振动。
实际上,除了拥有「千里眼」的能力外,海姆达尔的听力也非常灵敏,据说他的耳朵连草木、羊毛生长的声音也可听到,而且日夜不休息也不会疲惫。

海姆达尔这样「神级」的听力固然只存在于神话和科幻故事中。但在现实生活中,对于声音的高质量拾取需求却是真实存在的。
例如,作为万物互联的入口,已经走进千家万户的智能音箱、智能家电等智能语音产品,在使用的时候却常常因为距离远或者噪音大等因素,效果差强人意。唤醒智能语音设备的前端——拾音引擎如果能足够精细,也许会绽放更多精彩。
深耕于人工智能与智能领域多年的科大讯飞近期推出了全新的拾音品牌——谛听,据官方介绍,结合自主可控的智能语音与人工智能降噪算法,可以精准识别低至30分贝的微小声音,并且也可以做到7×24小时日夜不休。
30分贝是什么概念呢?普通人正常说话的音量是50分贝左右,一只蚊子飞过的声音大约40分贝,也就是说讯飞谛听甚至可以捕捉蚊子飞过的声音。
运动式瞄准「声源」,再小的声音也值得被倾听
谛听是如何长了顺风耳,实现「蚊过留声」的?

虽然语音识别相关的深度学习已经逐渐成熟,在实验室中也取得了不错的效果,但是现实中仍然有很多场景,语音识别、语音转写的效果差强人意。
识别的不准,转写效果自然不好,而识别准确的前提,是获得一个高质量的音频。
通常情况下,我们要么改善拾音的环境,要么改善拾音设备的性能。而拾音的环境是很难控制的,因此改善拾音设备的性能就尤为重要。
往往很多IoT产品只注重更多样化的功能,却忽视了最初的原点。讯飞谛听能着眼此处,未免让人欣慰。
针对目前拾音市场的痛点,讯飞谛听系列配备了32路麦克风,可实现7×24小时全天候、全方位、无死角拾音,精准拾取低至30分贝的超小音量。

当然,如此精准的拾音除了硬件的支持外,还得益于谛听的自动声源定位和自主研发的降噪算法。
我们知道,声音在传播过程中会发生衰减,不同方位的声源会导致所拾取语音音量和效果差异较大,而谛听采用了全自动声源定位和自适应波束形成技术,使得谛听可以轻松拾取运动的声源。
波束形成技术,如同一个枪手,可自动「瞄准」运动的声源方位,相对于那些需要预设和限制区域才能拾音的设备来说,讯飞谛听的优势十分明显。
拾音准确只是获取纯净语音的第一步。现实环境往往更复杂,各种干扰噪声不断,再加上回波和混响,使得语音信号的处理更加困难,所以后期降噪也是重要一环。
面对噪音的挑战,讯飞谛听首先通过声音定位技术精准拾取音源,进行语音增强实现初步降噪,然后通过波束形成和基于深度学习的语音增强算法,对非方向性和方向性的噪声进行抑制,最后对音量大小自动增益并根据人耳的听觉特点进行优化,使输出的声音更加饱满。
在拾音领域,德国的森海塞尔、美国的舒尔都是行业巨头,那么,讯飞谛听跟它们相比会有什么样的表现呢?
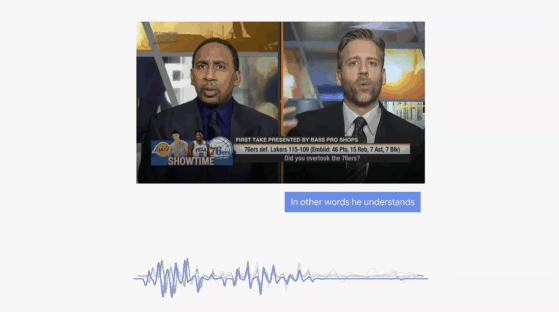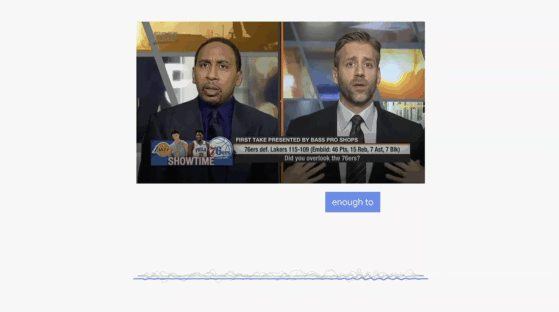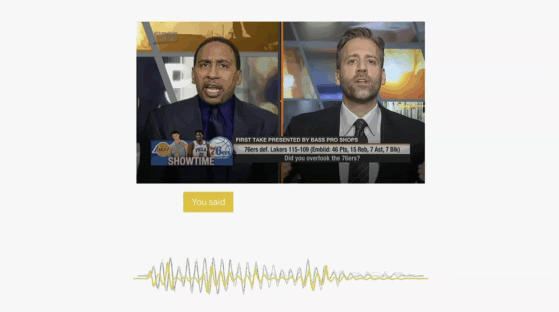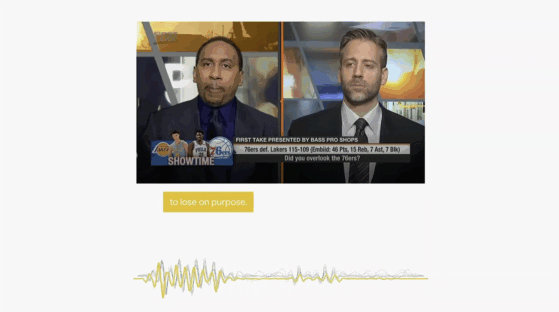
前段时间,某科技博主的一支关于拾音器的评测视频引发了大家的关注,在和德国森海塞尔、美国舒尔的较量中,谛听表现出彩,毫不逊色, 评测频显示:
在模拟30分贝悄悄话的场景下,森海塞尔拾音稳定,内容清晰,舒尔拾取的声音非常小且难以分辨说话内容,讯飞的谛听系列产品拾取的内容清晰,且音质听感较好。

接着,评测者又分别模拟了环境噪音为70分贝和90分贝的情况,结果显示即使是90分贝的极端噪音环境,谛听都能有效抑制,对话内容依旧清晰。

谛听系列产品的出色表现,离不开科大讯飞21年来始终如一地对源头核心技术的自主创新。
2018年至今,科大讯飞已获得30项人工智能国际竞赛的冠军,涵盖语音识别、语音合成、机器阅读理解、手势识别、图像识别等诸多领域。
今年7月,在DCASE 2020挑战赛的声音事件定位与检测任务中,科大讯飞A.I.研究院联合中科大语音及语言信息处理国家工程实验室摘得桂冠。

长期以来,拾音器这类专业语音设备一直被海外品牌所占据,实现源头可控意义重大。
科大讯飞作为智能语音行业的佼佼者,一直坚信「中文语音技术应由中国人做到最好」,讯飞谛听或许正是其20多年专注于源头核心技术的最佳体现。
除了语音的精准拾取和噪声抑制,讯飞拾音硬件还可以与其相关谈话系统结合,赋能于政法、交通、安防等特殊场景和关键部位,实现说话人分离。
该技术可以将自然交谈或者会议场景中的多个说话人自动区分开并转写记录,使得音频、文字的利用更便捷高效。
融合了精准拾音、深度降噪和说话人分离等先进技术的谛听,将为更多使用场景带来全新的畅想空间。
配备谛听的安防设备不光有了摄像头这个鹰眼,还长了「顺风耳」,视频无法捕捉的情景,谛听可以听到,语音和视频被有机的结合起来,再也不用对着「默片」猜唇语、对口语了。对于安防领域来说,将会是一个巨大的革新。

谛听听到的是声音,而声音最能体现人的情绪,结合视频中的图像行为判断,音视频多模态智能对群体性和违规事件可以有很好的预警,单视频采集的视野盲点也可以得到有效补位。
未来,谛听不仅仅停留于前端,还将成为链接各种智能图像、视频应用的纽带。
据了解,科大讯飞拾音产品已经广泛应用于公安、检察院、法院等政法系统以及智慧园区、智慧交通的建设中,让城市能更好的「倾听」每一个角落的声音。
根据艾瑞咨询的数据,2018年中国智能语音市场解决方案形式业务规模达到了33亿,预计2022年将超过100亿。

以谛听为代表的智能语音技术突破性的进展,为AI应用带来了新的机遇,音频、视频与文本的结合,也让智能语音成功出圈,跟图像和文本一起,走向更通用的智能。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






