四种决策风格矩阵(做商业决策必备的经典分析思维)

众所周知,无论是一个国家还是一个企业,在制定决策策略的时候,都不会询问每一个人的意见,对于国家而言,通常会收集各行各业代表的意见;对于企业而言,则是会选择一些有代表性的人员来进行意见调研。
同理,当我们需要对大量数据进行分析时,是否一定要纳入很多变量来构建模型呢?比如逻辑回归模型可纳入的变量个数是比较少的,那么当变量个数成千上万时,还可以来构建逻辑回归模型吗?此时,就需要引入维度分析的思想。
即选取一些重要维度中有代表性的变量来进行分析。比如某电信公司想要预测客户是否流失,而影响客户流失的维度有很多,比如有服务质量(信号差、计费错误)、费用高等等。
当你遇到这些问题时,如何快速找到问题的关键,从各维度中选取有代表性变量进行分析呢?
一般来讲,收集的数据中有很多是高度相关的,这表明这些变量很可能提供同一个维度的信息,这就需要对数据进行压缩,从大量的数据中归纳出少量的、最具有代表性的变量,选取的变量应该满足同目标变量相关且各个变量之间互不相关两个基本要求。
矩阵分析法的基本思想就是大数据小分析,所谓大数据小分析就是在做决策时对数据进行降维,以便决策者更加明确的了解事务的本质。所以,在学习矩阵分析法之前先来引入维度分析的思想。
从成千上万的变量中选择这样符合条件的变量,这就是维度分析的概念。这里的维度是指表述事物的不同方面。比如从长、宽、高3个维度描述立体形状;从思维、认识、创造、适应环境和表达这5个维度表述个人的智力情况。
以下几个例子反映了维度分析的重要性例1 某企业有多个产品,如何根据不同产品的表现制订发展战略呢?分析:企业中可以获取的关于产品的信息有很多,比如利润率、费用比率、年销售增长率、市场饱和度、产品知名度、专利覆盖度和市场占有率等。这些信息初想起来对制订产品发展战略都有意义。然而波士顿咨询公司认为,只有相对市场占有率和市场成长率这两个变量在回答这个问题上最有价值,并将其固化为了“波士顿矩阵”,如图1所示。
那么,为什么会选择这两个变量呢?原因在于产品相对市场占有率和利润率、产品知名度有较强的关系,反映该产品的市场地位和产生现金流的能力,而市场成长率和市场饱和度强相关,反映产品的市场发展潜力,也就是说这两个变量是最具有代表性的两个变量,符合维度分析的基本思想。

(图1)
这两个代表性变量背后隐含的其实是在做产品分析时总会说到的所谓的产品生命周期理论,产品生命周期指的是随着时间的推移,产品总会经历初创期、成长期、成熟期和衰退期这几个阶段,如图2所示。
可以看出,在初创期,产品的收益率存在波动性,且成长率不太高;蛰伏很长时间后,产品进入成长期,销售额及盈利均呈现快速增长趋势;之后进入成熟期,该时期市场增长率开始降低,同时伴随着前期投资的变现,收益率增高;最后是衰退期,该时期如果追加投资,净资产收益率(ROE)会很低,而且很多衰退期的产品已经达到了红海的情况,竞争非常激烈,增长率也会偏低。

(图2)
进一步分析,市场成长率反映了产品生命周期的变化情况,而市场占有率反映了企业的具体产品的市场渗透情况,也就是说它们是两个独立的变量,分别反映不同维度(市场成长率反映了市场的情况,市场占有率反映了企业在市场上的情况)的信息,通过不同的维度对产品做出很好的分类。
以2005年的IBM为例,我们来看下IBM对于个人笔记本(PC)、服务器、咨询这几种不同类型的产品做出了怎样的决策,首先是PC业务,市场占有率并不高,同时市场成长率也比较低,属于瘦狗产品;其次是服务器业务,其市场占有率非常高,市场成长率处于成长期和成熟期之间,处于金牛和明星产品之间,更偏向于金牛产品;最后是咨询业务,其市场成长率很高,处于成长期,但是市场占有率偏低,属于问号产品。
根据以上分析背景,IBM公司做出了以下决策:瘦狗产品PC直接进行了出售,金牛产品服务器继续保留投资,问号产品咨询业务经过不断扶持发展成为了明星产品,之后发展成为了金牛产品,最后进入瘦狗产品的行列。
上述案例分析表明,波士顿矩阵分析可以帮助企业制定出不同的产品发展战略,包括资源分配、拟定业务战略、制定绩效目标以及平衡投资组合等。具体来讲,对于瘦狗产品,一般不会对其进行发展性资源的分配,而且制定的绩效会比较苛刻;对于问号产品,就要观察其未来市场的发展情况,如果发展良好,市场占有率不断增大,则可以考虑为其配置战略性资源,制定温和的绩效目标(比如客户粘性、客户增长率、客户好评度等等),而金牛产品更加关注收益类指标,对于客户粘性基本不做过多关注。
最后,波士顿矩阵的象限特征总结如下,根据不同类型产品的特征制定不同的发展战略。

(图3)
在矩阵分析法中,问号产品的发展轨迹如下:

(图4)
例2 某外企计划开拓中国国内市场,应该先主攻哪个省呢?分析:模拟波士顿矩阵,波士顿咨询公司也给出了示例答案,描述这个问题的两个重要变量分别是市场规模和市场增长率,如图5所示,运用这两个变量对省份进行分类,从而做出相应的选择。同时,除了上述变量外,还引入了第三个变量市场收入增长额。
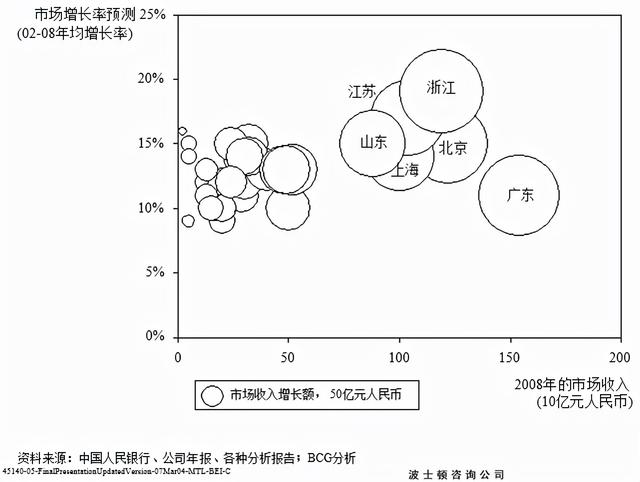
(图5)
可以看出,江苏、浙江在市场规模较大且市场增长率也较高。
例3 一个拥有技术但缺乏社会资源的大数据创业公司,选择哪个行业更容易成功?分析:在行业选择方面的判断涉及到的指标较为复杂,经分析,大数据价值潜力指数和海量数据捕捉难易程度指数这两个指标在信息、数据等方面都更具备综合性。以美国经济为例,如图6所示。

(图6)
通过分析数据获取的难易程度和数据的价值,做出行业的选择。
例4 一家信用卡公司希望知道客户按照价值贡献-活跃度分类,有哪些类型?如何进行客户维护?分析:根据波士顿矩阵分析思路,对个体客户打标签,通过聚类分析,得到客户的类别,并且投影在由循环信用次数和交易次数这两个指标组成的二维空间上,便于业务人员理解。其中,交易次数反映的是客户的粘性,循环信用次数反映的是客户的价值,总之,也是通过维度分析的方法对客户进行了分类。

(图7)
以上几个例子都使用的是维度分析的方法,即决策层根据矩阵分析的结果获得决策的依据,决定产品的投资与否;如果假设当前还没有波士顿矩阵,那么数据分析师该如何产出该矩阵呢?即如何从成千上万的指标中选择出有代表性的指标进行分析呢?
这就用到了常用的信息压缩方法—主成分分析法,主成分分析法会帮助我们将多个指标压缩到少量的几个综合指标,但是这几个综合指标没有实际的业务含义,所以就产生了因子分析,因子分析可以在主成分分析的基础上帮助我们探查相应的业务含义,最终可以直接根据因子分析的结果构建相应的分析矩阵,也可以根据因子分析的结果发现与因子相关的变量,根据代表性的变量构造分析矩阵。
在现实情况中,由于获取的数据日益丰富,建模使用的原始数据可能有成千上万个变量,这么多的变量对于建模的解释会造成一定的困难。其中的一大危险就是引入了冗余变量。针对冗余变量的问题,通常依据降维的理念对多维连续变量的数据进行处理,从而达到变量筛选和降维的目的。
降维的本质就是去除冗余变量,保留主要变量。在进行建模时,一般原始数据的变量非常多,若直接建模,计算量会随变量数量的增加呈指数增长,同时模型稳定性下降,维护成本增加。此时就需要通过各种办法降低数据的维度并筛选对模型有用的变量。若数据的维度能够被降低到符合预期的程度并且不至于损失太多对模型有用的信息,那么,这种降维就是理想的。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






