蝙蝠侠的排序(怎么计算蝙蝠侠)
对于大多数人来说,贝叶斯统计可能只是听说过的概念。作为其标志性方法之一的马尔科夫链蒙特卡洛方法更是有几分神秘色彩。虽然这种方法包含巨大的运算量,但是其背后的基本原理却可以直观地表达出来。这便是本文想呈现给大家的。
所以,什么是马尔科夫链蒙特卡洛(Markov Chain Monte Carlo,MCMC)方法?简单来说是:
MCMC方法是一种在概率空间中通过随机取样的方法来逼近所感兴趣的参数的后验分布的方法。
看不懂?别怕,我将在这篇文章中解释这个简单的表述,但不用任何数学推演!
首先介绍一些术语。我们感兴趣的参数就是一些数字,即我们对什么量感兴趣。通常我们使用统计方法来评估参数。例如,如果我们想了解成年人的身高,我们感兴趣的参数可能就是平均高度(英寸)。分布是对于参数可能取值以及取值几率的数学呈现。最知名的例子是钟形曲线:
来源于M. W. Toews
如果采用贝叶斯统计的方法,我们对于分布会有更多的理解。除了将分布单纯理解为一个参数的值以及这些值取真实值的可能性大小,贝叶斯统计还认为分布描述了我们对于一个参数的期许,即在看到真实测量的数据前预计数据怎么样以及相应的可能性。因此,上面的钟形线显示出我们非常确信参数的值是接近0的,但是我们在一定程度上认为真实的值大于或小于0的几率是相同的。
这样来看,人类的身高确实遵循一个正态曲线,假如我们相信人类真实的平均身高遵循如下的钟形曲线:
显然,怀有如图所示认知的人们可能生活在巨人国,因为他们认为成年人最可能的平均身高是6英尺2英寸(约188cm)。
让我们想象这个人前去搜集一些数据,他发现了一些身高在5到6英尺的人。我们可以按如下方法呈现这些数据,另外一条正态曲线为这些数据提供了最好的解释。
在贝叶斯统计中,代表我们对于一个参数的预期的分布被称为先验分布(prior distribution),因为这种认识是在我们在看到一组真实数据之前就有的。而似然分布(likelihood distribution)则通过呈现参数取值范围以及取值几率来总结我们所观察到的数据呈现给我们的信息。评估使似然分布最大化的参数值就是在回答下面的问题:什么参数取值是我们观察到的数据中出现几率最高的?如果没有先验的认知,我们可能就止步于此。
然而贝叶斯统计的关键在于综合先验以及似然分布从而给出后验分布(posterior distribution)。这告诉我们如果考虑了先验认知,什么参数取值是最可能被观察到的。在我们所举的例子中,后验分布看起来像这样:
上图中,红线代表了后验分布。大家可以将它视作对于先验和似然分布的某种平均。由于先验分布是更矮且展宽更大的,它代表我们预计真实人类身高平均值具有更大的“不确定性”。然而,似然分布则总结了分布在一个较窄的范围内的数据,因此它代表了对于真实参数值应当具有更强的“确定性”。
当先验和似然分布被综合考虑,得到的后验分布很接近似然分布,即那个我们假想的在巨人中成长起来的人脆弱的先验信念看上去被数据左右了。尽管这个人仍然相信人类身高的平均值比数据告诉我们的要更高一点,但是他已经在很大程度上被数据说服了。
对于两个钟形曲线的情况,求解后验概率很容易。用一个简单的方程就可以将两者结合。但是如果我们的先验和似然分布长得不是这样完美呢?有时候,使用一个不是很规则的形状的分布去描述我们的数据反而是更准确的。如果我们需要用双峰分布去描述我们的数据,而且我们的先验分布的形状较为古怪该怎么做呢?比如下图的例子,其中的先验分布被故意画得很丑:
在Matplotlib中渲染的可视化,使用MS Paint增强
和前面一样,后验分布是存在的,它给出了每个参数取值的可能性。但是比较难看出它像什么,也很难给出解析解。于是MCMC方法就登场了。
MCMC方法允许我们在无法直接计算的情况下估计后验分布的形状。为了理解其工作原理,我将首先介绍蒙特卡洛模拟,接下来再讨论马尔科夫链。
蒙特卡洛模拟是一种通过反复生成随机数来估计特定参数的方法。通过使用生成的随机数并对其进行一些计算,我们可以得到对参数的估计值,而直接计算这个值是不可能的或者代价非常昂贵。
假设我们要估计下面这个圆的面积:
因为圆是边长十英寸的正方形的内接圆,所以很容易计算得到它的面积是78.5平方英寸。换个思路,我们可以随机在方形空间里撒点。接着,我们数落在圆形内的点所占的比例,然后乘上方形的面积。得到的数字非常接近圆的面积。
因为20个点中,有15个落在了圆内,看上去圆的大概面积是75平方英寸。看来即使只用了20个点,蒙特卡洛方法也能得到不错的答案。
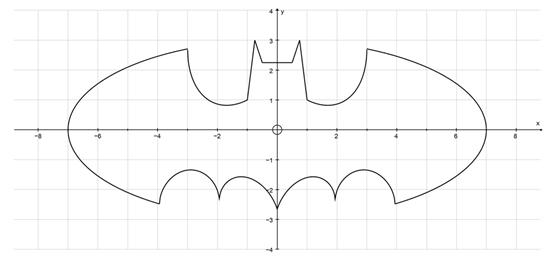
现在,想象一个场景,我们需要计算下面这个“蝙蝠侠”方程对应的图形面积:
这个形状的面积怎么求?我们从没有学过!因此这看起来是个很困难的任务。然而,通过随机在包含这个图形的矩形空间撒点,蒙特卡洛模拟可以很轻松地给我们一个近似的答案!
蒙特卡洛模拟不仅可以用来估计一个复杂形状的面积。通过生成很多随机的数字,它们可以被用于对一个复杂过程建模。事实上,它们被用于预报天气,或者评估赢得选举的可能性。
为了理解MCMC方法,我们要了解的第二个元素是马尔科夫链。这是一系列在几率上相互关联的事件。每一个事件都是一系列结果导致的,而且每一个结果根据一组固定的几率决定接下来将要发生什么。
马尔科夫链的一个重要特征就是无记忆性:在当前时刻,任何预测下一时刻事件所需要的信息都是已知的,追溯历史并不会带来新的信息。像《Chutes and Ladders》等游戏便呈现出了这种无记忆性或马尔可夫属性。现实世界中很少有事件是这样运作的,然而马尔科夫链依然是我们理解世界的有力武器。
在19世纪,人们观察到钟形曲线是自然界中的一种常见模式。(比如我们已经注意到,人类的身高遵循一个钟形曲线。)在使用高尔顿(Galton)板时,人们通过在装有钉子的板子上投掷弹珠来模拟重复随机事件的平均值,而在弹珠的分布中再现了正态曲线:
俄罗斯数学家和神学家帕维尔-涅克拉索夫(Pavel Nekrasov)认为,钟形曲线和更普遍的大数定律只是儿童游戏和琐碎谜题的产物,其中每个事件是完全独立的。他认为,现实世界中相互依赖的事件,如人类的行为,并不符合漂亮的数学模式或分布。
安德烈-马尔科夫(Andrey Markov)试图证明非独立的事件也可能符合某种模式,而马尔科夫链正是以他的名字命名的。他的代表工作之一是需要计算一部俄罗斯诗歌作品中成千上万的两字符对。利用这种字对,他计算了每个字的条件概率。也就是说,给定前面的某个字母或空白,下一个字母有一定的机会是A、T、空白或其他字符。利用这些概率,马尔科夫有能力模拟一个任意长的字符序列。这就是一个马尔科夫链。尽管前几个字符在很大程度上是由起始字符的选择决定的,但马尔科夫表明字符的分布经过足够长的时间会形成一种模式。因此只要受到固定概率的影响,即使是相互依赖的事件也符合一个平均值。
举一个更实用的例子,想象你住在一个有五个房间的房子里。你分别有一间卧室、浴室、客厅、餐厅和厨房。让我们收集一些数据:假设你在任何给定的时间点处在哪个房间,我们需要了解你接下来可能会进入哪个房间。例如,如果你在厨房,接下来你有30%的机会呆在厨房,30%的机会进入餐厅,20%的机会进入客厅,10%的机会进入浴室,10%的机会进入卧室。利用每个房间的一组概率,我们可以构建一个预测链,预测你接下来可能会处于哪些房间。
如果我们想预测房子里的某个人在进入厨房后的一段时间内会在哪里,那么对随后的几个状态进行预测可能是有用的。但是,由于我们的预测只是基于对一个人在房子里的位置的观察,我们有理由认为这种预测不是很完善。例如,如果有人从卧室到浴室,他们更有可能直接回到卧室,而不是从厨房出来。所以马尔科夫属性通常不适用于现实世界。
然而,利用马尔可夫链进行数千次的迭代,确实可以得出你可能在哪个房间的长期预测。更重要的是,这个预测完全不受这个人开始在哪个房间的影响! 从直觉上讲,这是有道理的:为了模拟和描述一个人在长期或一般情况下可能在哪里,他在房子里某个时间点的行为并不重要。因此,马尔科夫链用于预测一个随机变量在几个时间步内的行为并不完全合理,但只要我们了解支配其行为的概率,就可以用来计算该变量的长期趋势。
了解了一些关于蒙特卡洛模拟和马尔科夫链的知识后,我希望不加数学推演而直观地展现MCMC方法示如何工作的。
回顾一下,我们正试图估计我们感兴趣的参数的后验分布,即人类平均身高。
我不是可视化专家,显然我也不擅长将我的例子保持在常识范围内:我的后验分布的例子严重高估了人类的平均身高。
我们知道后验分布的信息包含在我们的先验分布和似然分布范围内,但无论出于什么原因,我们都不能直接计算它。使用MCMC方法,我们将有效地从后验分布中抽取样本,然后计算所抽取样本的平均值等统计数据。
首先,采用MCMC方法会选择一个随机参数值。模拟将继续产生随机值(这是蒙特卡洛部分),但要遵守一些规则来确定什么是好的参数值。诀窍在于我们拥有对于数据先验的认知,因此对于一对参数值,可以通过计算哪个参数值更好地解释数据来评估哪个是更好的参数值。如果一个随机产生的参数值比上一个更好,它就会被添加到参数值链中,其概率由其“好”的程度决定(这是马尔科夫链部分)。
为了直观地解释这一点,让我们回忆一下,分布在某一数值上的高度代表观察到该数值的概率。因此,可以认为我们的参数值(X轴)表现出高和低的概率区域,显示在Y轴上。对于单个参数,MCMC方法首先沿x轴随机采样:
红色点为随机参数样本
由于随机样本服从于固定的概率,它们倾向于在一段时间后向我们感兴趣参数概率最高的区域内收敛:
蓝点只是代表任意时间点后的随机样本,此时预计会出现收敛。注意:我纯粹是为了说明问题而将点垂直堆放。
收敛发生后,MCMC抽样产生了一组点,这些点是后验分布的样本。在这些点周围画一个直方图,并可以计算任何想做的统计。
在MCMC模拟产生的样本集上计算的任何统计量都是我们对该统计量在真实后验分布上的最佳猜测。
MCMC方法也可以用来估计一个以上参数的后验分布(比如说人的身高和体重)。对于n个参数来说,在n维空间中存在着概率高的区域,其中某些参数值集能更好地解释观测数据。因此,我认为MCMC方法是在一个概率空间内随机抽样以接近后验分布的过程。
回顾一下对 "什么是马尔科夫链蒙特卡洛方法?"这个问题的简短回答:
MCMC方法就是在概率空间中通过随机抽样逼近感兴趣参数的后验分布的方法。
我希望我已经解释清楚了这句话,即为什么你会使用MCMC方法,以及它们如何工作。这篇文章的灵感来自于我在美国华盛顿所作的关于数据科学的演讲。那次演讲的目的是向非专业听众解释马尔科夫链蒙特卡洛方法,我在文中也是这样尝试去做的。
翻译内容仅代表作者观点
不代表中科院物理所立场
作者:b
翻译:云开叶落
审校:Nothing
编辑:扫地僧
,













免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






