raft算法协议(基于Raft协议的分布式键值存储服务)
该项目参考《In Search of an Understandable Consensus Algorithm》论文实现Raft协议中三个子问题中的前两个,领导人选举(Leader election)和日志复制(Log replication)。使用网络编程框架Netty处理核心节点之间的RPC(RequestVote RPC和AppendEntries Rpc)请求交互,核心节点同时也开启对外服务端口等待客户端连接发送命令。接收到来自客户端的Get、Set命令后Leader节点通过AppendEntries RPC保证集群内节点将命令中的数据以Lsm-tree的存储策略持久化落盘。
1.分布式共识算法那么多,为什么使用Raft ?
答:在学术理论界,最闪耀的当属的Paxos,但将其工程落地相当复杂,绝大多数人认为其难以理解,晦涩难懂(这一点在上述提到的论文中也有阐述),本人同样也是对其一知半解且资料也相对较少,故放弃Paxos。相比 ZAB,Raft 的设计更为简洁。以可理解性和易于实现为目标的Raft算法极大的帮助了我们对分布式共识算法的理解,也正是易于实现让我选择了Raft。
2.什么是分布式系统,分布式与集群的区别?
答:由于普通的单机服务器面对业务量巨大的场景下无法满足要求,垂直扩展升级机器硬件和水平扩展堆廉价服务器是两种最常见的解决方案,目前互联网领域绝大多数选择了后者水平扩展,也就是加机器。分布式(distributed): 在多台不同的服务器中部署不同的服务模块,通过远程调用协同工作,对外提供服务。集群(cluster): 在多台不同的服务器中部署相同的应用和服务模块,通过负载均衡设备对外提供服务
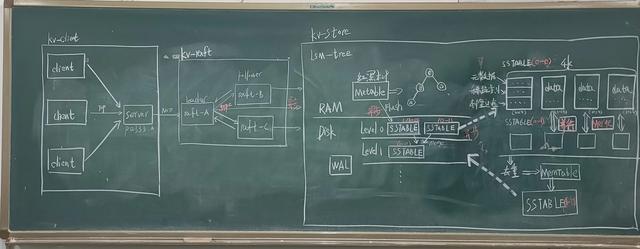
二、整体架构该项目的整体架构分为raft-kvservice对外服务模块、raft-core核心模块、raft-store存储模块三部分。
简单介绍
三、详细设计(一)对外服务模块(raft-kvservice)
- 对外服务模块(raft-kvservice):负责将client的读写请求通过Server中自定义的Decode解析后转发给核心模块进行处理,再由核心模块将处理结果转发给Server,Server通过自定义的Encoder封装响应最终回复client。
- 核心模块(raft-core):以集群的方式启动(默认3节点),在短时间通过选举产生一个Leader节点和多个Follower节点,由Leader节点负责接收来自对外服务模块的处理请求,同时将该命令已广播的形式复制到集群内的所有节点。在所有节点回复复制成功后,由Leader发送持久化请求给所有节点将数据持久化。至此,核心模块回复对外服务模块处理后的结果。
- 存储模块(raft-store):接收到来自核心模块的数据后,将数据写入基于磁盘的WAL(write ahead log)中以防还未持久化就宕机导致数据丢失,先写入WAL可以在恢复后回滚数据。然后写入MemTable(基于内存的有序集合)中,在MemTable中的数据达到阈值后,将其异步交的给SSTable(一个SSTable对应一个文件)。SSTable中包括了自定义的文件头信息、稀疏索引、布隆过滤器、以及真正的数据。
- 接下来将介绍以上三个模块的详细设计。
对外服务模块的设计主要分为Client和Server两部分,Client以Tcp的方式与Server连接,发送封装请求命令给Server,Server会根据请求类型调用不同的API转发给核心模块。
1.Server在Raft中,每个核心节点(Node)都会有可能成为Leader,而Leader既需要管理整个集群内的日志复制工作还需要接收来自客户端的命令,所以在核心节点启动时也需要同时启动对外服务端口(Server)来接收来自客户端的请求(如果非Leader节点收到了读写请求会自动重定向到集群内的Leader节点来处理该请求)。
2.Client
//启动Server服务器 public void start() throws Exception { //同时启动核心节点服务 this.node.start(); //启动对外服务器监听服务端口 ServerBootstrap serverBootstrap = new ServerBootstrap() .group(bossGroup, workerGroup) .channel(NioServerSocketChannel.class) .childHandler(new ChannelInitializer<SocketChannel>() { @Override protected void initChannel(SocketChannel ch) throws Exception { ChannelPipeline pipeline = ch.pipeline(); pipeline.addLast(new Decoder());//解析请求 pipeline.addLast(new Encoder());//封装响应 pipeline.addLast(new ServiceHandler(service)); } }); logger.info("对外服务端口为: {}", this.port); serverBootstrap.bind(this.port); } 复制代码Client在启动时需要获得集群内活跃Server的Endpoint(NodeId,Host,Port)信息,通过这些Endpoint构建一个连接客户端的通道SocketChannel保存到核心模块中的ServerRouter路由表中。目的是在发送命令时,Client无需关注接收端是谁,路由表会根据Endpoint所对应的核心节点的所处状态来选择合适的进行发送(一般情况下由Leader节点接收)。以下是ServerRouter的结构。
// 构建服务路由表 private ServerRouter buildServerRouter(Map<NodeId, Address> serverMap) { ServerRouter router = new ServerRouter(); for (NodeId nodeId : serverMap.keySet()) { Address address = serverMap.get(nodeId); //构建服务器路由表,路由表实际上是根据Host和port创建了一个连接管道 //A,localhost,3333 B,localhost,3334 C,localhost,3335 router.add(nodeId, new SocketChannel(address.getHost(), address.getPort())); } return router; } 复制代码3.解决半包粘包
//发送消息 public Object send(Object payload){ //遍历服务路由表内所有节点(在某个节点返回未响应时,发送到其他节点) for (NodeId nodeId : getCandidateNodeIds()) { try { Object result = doSend(nodeId, payload); this.leaderId = nodeId; return result; }catch (Exception e) { logger.debug("failed to process with server " nodeId ); // 连接失败,尝试下一个节点 } } } 复制代码由于是使用Tcp进行通信,消息可能会出现半包/粘包的问题,所以在对消息序列化和反序列化时需要特别处理,而不是仅仅转换数据。我这里给出的解决办法是在消息前加上4字节表示消息类型,4字节表示消息长度,其余字节表示消息内容。
4.大概运行流程
private void write(Outputstream output, int messageType, MessageLite message) throws IOException { DataOutputStream dataOutput = new DataOutputStream(output); byte[] messageBytes = message.toByteArray(); dataOutput.writeInt(messageType); //4字节 数据类型 dataOutput.writeInt(messageBytes.length); //4字节 数据长度 dataOutput.write(messageBytes); //不定长 数据内容 dataOutput.flush(); }//反序列化代码太长就不在这里展示~ 复制代码(二)核心模块(raft-core)
核心模块是该项目中的大脑,负责处理对外服务模块的请求和同步数据保证整个集群的强一致性。该模块主要分为领导人选举,日志复制两部分。
1.领导人选举参考Raft论文中Leader Election部分的表述,每个节点会有三种身份,分别为Follower(追随者),Candidate(候选者)以及Leader(领导者)。在集群刚启动时(默认3节点),每个节点都是以Follower的身份启动,并且会在自己的线程执行器中提交一个异步的定时任务,这个定时任务就是超时选举。当时间到期后,当前节点会立即将自己的身份变为Candidate(Term也同时要加1),并且向集群中除自己以外的节点发送RequestVote Rpc投票请求。其他节点收到该请求后会进行判断逻辑,选择是否投票给目标节点(一节点一票制),并且在决定是否投票后会封装一个RequestVoteReuslt Rpc返回给目标节点。当前节点将收到的其他节点回复中的投票数累加,如果超过集群中的绝大多数则会将自己变成Leader来管理整个集群。
1.其他节点收到投票请求时的投票的逻辑是什么?
答:首先判断对方的term决定是否投票 (1)比自己小:不投票且返回自己的term(说明当前自己就是leader); (2)比自己大:投票且切换自己为Follower更新自己的term; (3)与自己等: ①当前自己是Follower:比较日志进度,比自己的日志进度新且自己还未投票,则投票更新自己的term; 若自己以投票给该节点,则投票更新自己的term; 比自己日志进度旧无论投没投票,不投票且返回自己的term; ②当前自己是Candidate:不投票,因为切换角色时以给自己投过票; ③当前自己是Leader:不投票且返回自己的term
如何避免Split vote(投票平分)现象的发生?
答:在选举的过程中可能会发生两个Follower节点同时选举超时,此时就会同时发出RequestVote Rpc投票请求,最终导致获得的投票数相同。由于两个节点都没有获得集群中的绝大多数投票数,所以会继续进行领导人选举,恶性循环。为了尽量避免这样的情况发生,我们可以在设置一个随机的选举超时时间,这样就可以尽量避免同时发生投票请求的情况发生。
2.日志复制
public ElectionTimeout scheduleElectionTimeout(Runnable task) { //随机选举超时时间 int timeout = electionTimeoutRandom.nextInt(maxElectionTimeout - minElectionTimeout) minElectionTimeout; ScheduledFuture<?> scheduledFuture = scheduledExecutorService.schedule(task, timeout, Time.MILLISECONDS); return new ElectionTimeout(scheduledFuture); } 复制代码按照复制状态机的理论:相同的初识状态 相同的输入 = 相同的结果,raft中的做法是,将这些请求以及执行顺序告知集群内所有的Follower。Leader和Follower以相同的顺序来执行这些请求,保证状态一致。
参考Raft论文中Log replication部分的表述,在经过领导人选举后集群内会产生一个Leader和多个Follower节点,Leader节点此时会取消超时选举的定时任务并重新提交一个异步的循环定时任务,这个任务就是日志复制。日志复制任务会每隔一定的时间由Leader发起,向集群内的Follower发送AppendEntries Rpc复制请求。Follower节点收到消息后会与自己当前最新的日志进行比较,选择是否要复制。如果自己日志比消息中日志的Index小很多,则会在回复Leader节点的AppendEntriesResult Rpc消息中带上自己当前的日志Index。Leader收到回复后会找到该日志Index对应的数据然后不停的异步发送AppendEntries Rpc直到Follower节点追上自己的进度。 如果Leader收到的消息中确认复制成功数占集群节点的绝大多数则会发送提交请求(持久化),Follower节点收到后提交数据并返回Success。同样Leader收到的Success占集群节点的绝大多少,就会立即返回客户端提交成功。
这里提到的Index是线性增长的,用来保证Follower节点中日志的顺序始终与Leader保持相同。
(三)存储模块(raft-store)
public LogReplicationTask scheduleLogReplicationTask(Runnable task) { //scheduleWithFixedDelay循环间隔执行 logReplicationDelay表示延迟时间 logReplicationInterval表示间隔时间 ScheduledFuture<?> scheduledFuture = this.scheduledExecutorService.scheduleWithFixedDelay( task, logReplicationDelay, logReplicationInterval, TimeUnit.MILLISECONDS); return new LogReplicationTask(scheduledFuture); } 复制代码存储模块是客户端的命令到达的最后一个模块,该模块主要由自己独立设计的Lsm-Tree构成。关于Lsm-Tree,推荐一本书《Designing Data-Intensive Applications》(DDIA),这本书的第三章节由浅入深详细的阐述了Lsm-Tree,值得一看!
Lsm-Tree的核心特点是利用顺序写来提高写性能,但因为分层(此处分层是指的分为内存和文件两部分)的设计会稍微降低读性能。围绕这一特点进行设计和优化,以此让写性能达到最优,正如我们普通的Log的写入方式,这种结构的写入,全部都是以Append的模式追加,不存在删除和修改。当然有得就有舍,这种结构虽然大大提升了数据的写入能力,却是以牺牲部分读取性能为代价,故此这种结构通常适合于写多读少的场景。
为什么选择Lsm-Tree而不是B Tree?
答:在数据的更新和删除方面,B Tree可以做到原地更新和删除,这种方式对数据库事务支持更加友好,因为一个key只会出现一个Page页里面,但由于LSM-Tree只能追加写,并且在L0层key可能重叠,所以对事务支持较弱,只能在合并的的时候进行真正地更新和删除。因此LSM-Tree的优点是支持高吞吐的写(可认为是O(1)),这个特点在分布式系统上更为看重,当然针对读取普通的LSM-Tree结构,读取是O(N)的复杂度,在使用索引或者缓存优化后的也可以达到O(logN)的复杂度。而B tree的优点是支持高效的读(稳定的OlogN),但是在大规模的写请求下(复杂度O(LogN)),效率会变得比较低,因为随着insert的操作,为了维护B 树结构,节点会不断的分裂和合并。操作磁盘的随机读写概率会变大,故导致性能降低。
1.WAL(write ahead log)
数据到达存储模块的第一站便是WAL预写日志中,由于预写日志是直接写入磁盘的,因为数据持久化的过程可能比较费时,所以有可能会在持久化的过程中突然发送宕机或者断电,从而导致数据丢失,而预先写入WAL中便可以在系统修复后重新加载到内存持久化。该项目中的WAL设计较为简单(拿到数据就往文件里怼)。
public void set(String key, String value) throws IOException, InterruptedException { Command command = new Command(1, key, value); wal.write(command);//接到数据就写WAL if (!memTable.puts(command)) { this.memTable = new MemTable(eventBus); memTable.puts(command); } } 复制代码
public void write(Command command) throws IOException { byte[] commandBytes = JSON.toJSONBytes(command); writer.writeInt(commandBytes.length); //4字节 写入数据长度 writer.write(commandBytes); //不定长 写入二进制数据 } 复制代码2.MemTable
数据写完WAL后会立即写入到MemTable中,MemTable是基于内存实现的有序集合,可以有多种实现方式。该项目直接使用java.util包下原生的TreeMap来实现MemTable这一组件。TreeMap的底层是红黑树,可以按照自然顺序进行排序或者根据创建映射时提供的Comparator接口进行排序。从存储角度而言,这比HashMap的O(1)时间复杂度要差些;但是在统计性能上,TreeMap同样可以保证log(N)的时间开销,这又比HashMap的O(N)时间复杂度好不少。
public class MemTable { TreeMap<String, Command> memTable; private int levelNumb;//层号 private int numb;//页号 private int memTableLength;//当前MemTable大小(用来判断是否达到阈值) private volatile boolean isImmTable = false;//判断当前MemTable是否正在持久化 } 复制代码为什么必须要是有序集合?
答:是为了保证持久化到SSTable中时仍能保持顺序性。我们通常会给SSTable中加上稀疏索引,这样便可以快速通过索引来定位到数据所在的范围,再通过二分查找快速锁定数据。
当MemTable中的数据达到一定的阈值时会异步的进行Flush操作,同时再创建一个新的MemTable用来接收数据。通过上面Lsm-Tree的架构图可以得知第一次Flush操作称为Minor Compaction,而之后对SSTable的操作称为Major Compactionm。这是因为首次Flush并不会对MemTable中的数据进行去重操作(体现Lsm-tree的快),也就是说存入磁盘里的数据有可能是重复的。而之后对SSTable操作是需要去重的,一是为了节省空间,二是为了加速查询。
3.SSTable数据的最后一站就是SSTable,也是存储模块中最复杂的一部分(当然离工程化还差很远)。该项目所设计的SSTable分为四部分,分别为元数据、稀疏索引、布隆过滤器以及数据区,一个SSTable对应一个实实在在16K大小的文件。元数据、稀疏索引和布隆过滤器是被放置在0~4K中,而后面空间存放真正的数据。
由于数据积累的越来越多,SSTable个数量会不断增加并且第一层的SSTable里的数据是有可能重复的,此时就需要进行合并(Merge)来节省空间,加快查询的速度。合并后的SSTable会放在第二层中,当第二层中的SSTable过多时就需要继续进行合并。合并后继续放在下一层,层数越大对应的数据就越旧。
为什么要这样设计?
答:由于磁盘的存取单位是一个一个4K大小的块,所以当以4的整倍数存取数据时对于磁盘来说是最高效的。同时也为下面优化时可以并行的进行合并(Merge)。
(1)首先是元数据的设计,其包括了当前SSTable是第几层的第几个的(这在Merge时有重要作用),也包括了数据的基本信息。固定其大小为20字节方便找到稀疏索引快速查询。
public class SSTableMetaData { private int numb;//当前层的第几个文件(numb越大数据越新) private int level;//第几层的文件(level越大数据越旧) private long dataOffset;//数据偏移量 private int dataLen;//数据总长度 } 复制代码(2)其次是稀疏索引的设计,稀疏索引记录了每1K数据的第一条数据的内容、页号、偏移量、长度。以便在查询直接判断Key值快速锁定数据范围,通过偏移量直接读取数据。
public class SparseIndexItem { private String key;//键 private String value;//值 private int pageNumb;//页号 private long offset;//数据偏移量 private int len;//长度 } 复制代码(3)最后是数据的设计,一条数据包括了操作类型,Key值,Value值,以及系统生成的页号。
四、整体流程(一)写入流程
public class Command{ private int op;//操作类型 支持GET SET DEL private String key;//键 private String value;//值 private int numb;//页号 } 复制代码(二)查询流程
- Client在命令行中输入kvstore-set key value以Tcp的方式发送给Server(事实上Server就是核心节点启动时一同启动的对外服务器)
- Server解析完命令根据命令类型封装成对应类型的请求发送核心模块中的Leader节点
- Leader接收到请求后以广播的形式发送AppendEntries RPC给Follower节点
- Follower接收到RPC,解析RPC中的命令数据,确认没问题后确认回复Leader
- Leader收到大多数节点成功的RPC后发送以广播的形式发送提交请求给Follower节点(并且自己持久化),同时回复Server操作成功,Server回复Client OK。
- Follower接收到提交请求后开启异步持久化任务
- 数据首先写入基于磁盘实现的WAL中以防断电丢失,紧接着写入基于内存实现有序集合MemTable中
- 当MemTale中的数据达到一定阈值后立即变为不可用状态,同时创建一个新的MemTable继续服务。
- 变为不可用状态的MemTable开始持久化到SSTable中,首先seek到4K字节的位置开始写数据,每写一页记录一条数据到稀疏索引中
- 等到MemTable中的数据都写完时,seek到0位置写入元数据信息和稀疏索引,构成SSTable文件
- 清空WAL,至此整个写入流程结束(删除流程和写入流程差不多,只是给这个Key加了一条墓碑记录)
(三)合并流程
- Client在命令行中输入kvstore-get key以Tcp的方式发送给Server(事实上Server就是核心节点启动时一同启动的对外服务器)
- Server解析完命令根据命令类型封装成对应类型的请求发送核心模块中的Leader节点
- Leader节点将请求解析出来后交给存储模块
- 首先会在内存中的MemTable中查找,若通过Key找到对应的Value,则直接返回。若未找到,则加载第一层最新的SSTable文件到内存中
- 将稀疏索引解析出来,若Key在稀疏索引中记录的Key的范围内,则直接seek到稀疏索引中记录的offset,将这页数据解析出来通过二分法进行查找,若通过Key可以找到对应的Value,则直接返回。
- 若未找到,则加载这一层的下一个SSTable文件重复第5步操作
- 直到这一层的SSTable文件都访问过,若还未找到,则进入下一层重复上述操作
- Leader收到来自存储模块的处理结果,返回给Server,Server最终回复Client
当一层的SSTable过多时为了加快查询的速度以及节省空间,此时需要对SSTable进行合并。基于LSM-Tree分层存储能够做到写的高吞吐,但同时带来的副作用是整个系统会频繁Merge,写入量越大,Merge越频繁。而Merge非常消耗CPU和存储IO,在高吞吐的写入情形下,大量的Merge操作占用大量系统资源,必然带来整个系统性能断崖式下跌,对应用系统产生巨大影响。
这里介绍的是本人在思考过程中给出的优化的解决方案,接下来举例说明。
假设现在需要将这两个SSTable合并,这里有几点要说明一下。第一,这里只展示了SSTable中存放数据的部分,因为第0块的信息是根据我们合并之后的SSTable进行构造生成的。第二,因为合并只关乎到Key的值,和value并没有产生直接联系,所以我们这里不关乎Value的值。第三,我们可以看到Key的值是按照顺序排列的,这是因为数据在MemTable中就是有序的,我们会借助这个特性来优化合并流程。第四,这里的命名规则,第一个0表示这是第0层,后面的1和2表示是这一层的第几个文件(数越大数据越新)。
1.加载由于我们在一开始就是根据磁盘的存取单元是4K这一特性来存放数据的,所以我们可以同时开启三个线程,每个线程seek到块号*4K的位置开始加载文件。
2.去重排序
这时发现线程1中SSTable0-1和SSTable0-2有重复的Key值(同理线程3),由于SSTable0-2在是SSTable0-1之后生成的,所以SSTable0-2的数据比SSTable0-1新。接下来我们就需要根据这一规则去重。
3.合并再去重
经过第2步去重排序后我们发现单个线程中去重后排序的不会存在重复的数据,线程1里留下的9是SSTable0-2中的9而不是SSTable0-1里的(因为它较新,同理线程2中的28)。但这时又发现一个问题,线程1与线程2中出现了同样的Key(11),线程2与线程3也存在同样的Key(17,26,27),这时我们只需要合并再进行一次第2步就可以解决。
4.创建下层的SSTable
完成第3步后我们就得到了真正的去重后并且排好序的数据了,这时我们就需要将这些内存里的数据构建稀疏索引、元数据信息以及写数据到文件这一系列操作后持久化到磁盘,才算完成合并操作(新生成的文件命名为SSTable1-1表示是第一层的第一个SSTable)。
到这里SSTable就不只是16K那么大了,因为随着层级的变多,每次合并后的结果都会比原来的SSTable大。这里举的例子数据量比较小,本人认为如果数据量大的情况下,这种根据文件偏移量并行的进行合并操作是可行的。
五、总结这是我第一次写博客,也是第一次将自己的项目进行总结,不得不说总结的过程是很难受的。因为有很多地方知道是如何实现的但不能表述的很清楚,也有很多知识点记得有些模糊了,需要重新翻阅资料巩固知识点。我也体验到了写文章的痛苦(写的这么差,很感谢你能读到这里~)。通过这个项目让我感受到了Raft算法,Netty和Lsm-Tree的强大,目前越来越多中间件的底层总能看到它们的身影,Lsm-tree的实现有Tidb,Leveldb,Rocksdb,Hbase这些NoSql数据数据库,Raft有Etcd这个用Go语言实现的共享配置和服务发现组件。看着这些优秀的开源中间件,我也常常会想我几时也可以为这些优秀的开源中间件贡献自己的代码。我也深切的知道自己还不够格。目前这个项目待优化的地方还有很多,例如在合并过程中可以加入一些压缩算法,将数据进一步压缩,节省更多的磁盘空间。也可以在每个SSTable的头信息中构建出布隆过滤器来加快查询的速度,布隆过滤器的工作原理就是将文件中的Key通过Hash算法映射到一个bitmap中,当查询来临时先通过布隆过滤器来判断Key是否在这个SSTable中(它能保证不存在,但不能保证存在)。未来我将继续完善这个项目,学习新的技术并融入其中,最后附上一张图片。
作者:Wyy522链接:https://juejin.cn/post/7192992994286960698
,


















免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






