实时语义分割最流行(一文带你读懂SegNet语义分割)
本文为 AI 研习社编译的技术博客,原标题 :
Review: SegNet (Semantic Segmentation)
作者 | SH Tsang
翻译 | 斯蒂芬•二狗子
校对 | 酱番梨 审核 | 约翰逊 · 李加薪 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/review-segnet-semantic-segmentation-e66f2e30fb96
这个图是SegNet演示效果,来源是作者上传到YouTube的一个视频 (https://www.youtube.com/watch?v=CxanE_W46ts)
在本文中,我将简要回顾剑桥大学的SegNet。最初它被提交到2015年CVPR,但最后它没有在CVPR上发布(但它的2015年arXiv技术报告版本仍然有超过100次引用)。相反,它发布于2017年TPAMI,引用次数超过1800次。现在,第一作者成为Magic Leap Inc.的深度学习和人工智能总监(SH Tsang @ Medium)
以下是作者的演示链接:
(https://www.youtube.com/watch?v=CxanE_W46ts)
还有一个有趣的演示,我们可以选择随机图像,甚至上传我们自己的图像来试用SegNet。我试过如下例子:
http://mi.eng.cam.ac.uk/projects/segnet/demo.php
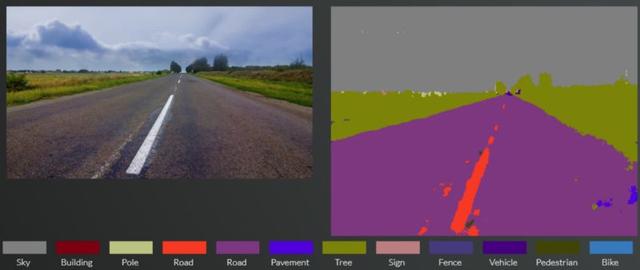
我从这个链接得到的道路场景图像的分割结果
文章大纲
编码-解码器架构
DeconvNet 和 U-Net与的不同之处
结论
1.编码-解码器架构
SegNet: 编码-解码结构
SegNet具有编码器网络和相应的解码器网络,接着是按最终像素的分类层。
1.1. Encoder编码器
在编码器处,执行卷积和最大池化。
VGG-16有13个卷积层。 (不用全连接的层)
在进行2×2最大池化时,存储相应的最大池化索引(位置)。
1.2. Decoder解码器
使用最大池化的索引进行上采样
在解码器处,执行上采样和卷积。最后,每个像素送到softmax分类器。
在上采样期间,如上所示,调用相应编码器层处的最大池化索引以进行上采样。
最后,使用K类softmax分类器来预测每个像素的类别。
2. DeconvNet 和U-Net的不同
DeconvNet和U-Net具有与SegNet类似的结构。
2.1. DeconvNet 与 SegNet不同之处
Similar upsampling approach called unpooling is used.使用了类似的上采样方法,称为unpooling 反池化。
不同,有完全连接的层,这使模型规模更大。
2.2. U-Net 与 SegNet不同之处
用于生物医学图像分割。
整个特征映射不是使用池化索引,而是从编码器传输到解码器,然后使用concatenation串联来执行卷积。
这使模型更大,需要更多内存
3.结论
尝试了两个数据集。一个是用于道路场景分割的CamVid数据集。一个是用于室内场景分割的SUN RGB-D数据集。
3.1. 用于道路场景分割的CamVid数据集
道路场景分割的CamVid数据集上,与传统方法相互比较
如上所示,SegNet在多类分割问题上获得了非常好的结果。它也获得了最高级别的类平均值和全局平均值。
道路场景分割的CamVid数据集上,与深度学习方法相比较
获得最高的全局平均准确度(G),类别平均准确度(C),mIOU和边界F1测量(BF)。它的结果优于FCN,DeepLabv1和DeconvNet。
定性结果
3.2. 用于室内场景分割的SUN RGB-D数据集
仅使用RGB,不使用深度(D)信息。
在室内场景分割的SUN RGB-D数据集,与深度学习方法比较
同样,SegNet优于FCN,DeconvNet和DeepLabv1。
对于mIOU指标,SegNet只比DeepLabv1略差一些。
不同类的类平均准确度
大尺寸目标的准确度更高。
小尺寸目标的准确度较低。
定性分析结果
3.3. 内存和推断时间
内存和推断时间
SegNet比FCN和DeepLabv1慢,因为SegNet包含解码器架构。它比DeconvNet更快,因为它没有全连接层。
SegNet在训练和测试期间的内存要求都很低。并且模型尺寸比FCN和DeconvNet小得多。
参考文献
[2015 arXiv] [SegNet]SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling
[2017 TPAMI] [SegNet]SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
想要继续查看该篇文章相关链接和参考文献?
点击【一文带你读懂SegNet(语义分割)】或长按下方地址:
https://ai.yanxishe.com/page/TextTranslation/1532
AI研习社今日推荐:雷锋网雷锋网雷锋网
李飞飞主讲王牌课程,计算机视觉的深化课程,神经网络在计算机视觉领域的应用,涵盖图像分类、定位、检测等视觉识别任务,以及其在搜索、图像理解、应用、地图绘制、医学、无人驾驶飞机和自动驾驶汽车领域的前沿应用。
加入小组免费观看视频:https://ai.yanxishe.com/page/groupDetail/19
,








免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






