人工智能预测分析学(大白话5分钟带你走进人工智能第23节-决策树系列之数学表达式)
第二十三节决策树系列之特点和数学表达形式(2)
上节我们讲解了决策树的概念,本节的话我们讲解决策树的特点以及其数学表达形式。
目录
1-决策树的特点
2-决策树的数学表达形式
1-决策树的特点
决策树的特点大致有以下几种:
1、可以处理非线性问题。逻辑回归处理非线性问题有一些捉襟见肘,没有特别完善的方法能解决,我们有若干种妥协的方法来让它凑合能用,而决策树天生就可以处理非线性问题。假设在一个二维的平面上,有若干数据如图:

每一个数据有两个维度,x1和x2。总共9个数据点。如果我们想用逻辑回归来分类,无论怎么分,都找不到一条很好地直线将图中点分开。假设我们用决策树分裂的话,第一次分裂选择条件是x<3,相当于画一条竖线,所有x<3的都分到左边,x>3分到右边。
分到左边的都是O点,分到右边的有一半是O点一半是X点,给它落成一个叶子节点不太合适,就需要再次分裂,再选择分裂条件是x<6,就将数据完美的分开了。我们的决策树的分裂图如图所示:

原来逻辑回归处理不了的非线性问题,决策树轻而易举的就把它们分开了。
再比如下图:

数据点如图,想把蓝色,红色的数据点分开,同样的线性不可分,而决策树却可以会画出一个波浪线,把数据分开,相当于每一个折点部分就多出分裂一个条件。所以说通过决策树不断分裂的方式,可以处理各种各样的非线性问题。
2、可解释性强。从数据集上抓到一个算法,生成出来一个模型,逻辑回归模型的本质,记在计算机里面的是一组w,训练出来这个模型是个一组数,它没有具体的物理含义。比如0.8和 0.7,怎么解释这两个w到底差别在哪?说不太清,可解释性差一些,机器到底学少什么你不知道。而决策树算法,记录下来的是一组分类条件,相比一组w来说,它的可解释性是要强不少。
3、 决策树的模型非常简单。它不需要借助函数最优化工具,在原生的决策树里面是没有损失函数这个概念的。决策树其实特别像森林球,某一条数据顺根节点、分支节点下来,最后落到某一个叶子节点上。它这个模型相对于梯度下降的训练过程中是比较简单的,预测就更简单了,直接跑一遍if…else,最后该是谁就是谁。
4、缺点 不容易显示地使用函数表达,不可微。可能带来一个问题是不好给它加正则项,正则项是用来评估模型简单程度的。原来的损失函数,给它加一个L1正则,组成了一个新的形式函数叫obj,原本是让L损失函数最小,现在要变成让它们俩合obj最小。为什么加上它效果就能好?在算法模型里边是通过这L1和L2两个指标来评估模型到底是简单还是复杂的。如果有更简单的方式能得到更好的模型,当然要优先简单的,因为复杂模型容易过拟合,这也就是正则存在的意义。但是决策树很难加这种正则表达式。
2-决策树的数学表达形式
决策树虽然不容易显示地使用函数表达,非得要表达的话,我们有两种方式表达。
第一种是从路径的角度(Path View),将每个从根到叶子的路径作为一个假设 g,通过不同的条件组合得到最后的 G (X)。
第二种是从递归的角度(Recursive View),父树是由子树递归定义的 tree=(root,sub-trees)。
1、我们先说第一种从路径的角度:表达如下:

上面G(x)是一个函数,对于函数我们永远就把它理解成一个机器,你给我一个原材料,我给你生产一个东西。所以这里面的G(x)也不例外,对于决策树来说一般是做分类的,所以我们可以想到这个函数G(x)其实就代表着你给我一个X,我给你一个分类结果。所以G代表着这棵已经生成好的决策树,X代表着扔进去的一个原数据。而函数后面的表达式代表我这个机器如何工作的,如何从已知得到结果的,是表达式记录的信息。我们看到后面是个连加符号,给它拆解出来就是
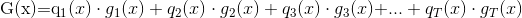
这是什么意思呢?比如下图的决策树,我把叶子节点编号如图:

这里面q代表所有决策树的路径,比如我们的X是qutitingtime<17:00 并且没有约会,那么在上述决策树存在的情况下,这个数据会落到2号节点,能够通往几号节点的路径就叫几号路径,所以X扔进来的情况下,会通往2号路径,所以我们定义此时的X只有q(2)x=1,其他路径都为0,即q(1)x=0,q(3)x=0...。所以我们qt是定义出来的,代表着x是不是在第t号路径上,is x on path t。gt(x)代表某一号叶子节点的表达,比如这里的X,落在2号节点上,所以表达为Y,也就是说以后甭管X是什么样,只要落在2号节点上,就写成Y,因此qt(x).gt(x)就是代表来一条数据,先是通过qt(x)看看落在哪个叶子节点上,然后再通过gt(x)看看这个叶子结点的表达是什么,我们就返回什么(Y 或者N),简直就是一个很无聊的表达,并且表达的很简单。
上面公式表达的前提就是树已经存在了,它的判别函数怎么表达。所以还是针对上述落在2号节点的X,我们针对上面的决策树把连加符号拆解出来就是:
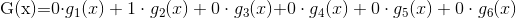
因为只有2号节点的q2(x)=1,其他都为0。这里面的点乘代表着对应关系,并不是真正的乘。T代表第几号叶子结点即叶子节点的序号。gt(x)是一个base hyponthesis 基础的假设,这里就是假设我所有的叶子结点的表达的形式是Y还是N,是一个常数。因为这里面gt(x)的值只有Y或者N。不是取决于X的输入,而是取决于我当前落在第几号节点,g(1)(x)就是N,g(2)X就是Y。所以总结如下:

2、第二种表达决策树的方式:递归的角度(Recursive View)

我们通过下面举例解释下上面公式:

实际上上面是个递归的表达形式。比如对于根节点(qutting time )来说,有3个子节点,如图所示。对于1号子节点的根(has a date)来说有两个子节点 N或者Y。还是拿上面X是qutitingtime<17:00 并且没有约会的例子来说,从根节点下来会落到1号子节点,这里面的b(x)是分支的条件,这个例子中b(x)=1 ,C代表几个子节点,而对于qutting time的根节点来说,有3个子节点,所以C=3。落在几号节点上,只有当前子节点为1,其他都为0,所以对于这里只有G1(x)=1。当落到1号节点之后,继续往下走,同理接着遍历,会落到1号子节点中的Y子节点上,同理对于 has a date 作为根节点来说,C=2,因为落在Y子节点上,此时是叶子结点,不在遍历,所以向上依次返回最终结果Y。
总结如下:

下一节我们讲解决策树的分裂流程以及分裂条件的评估。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






