快手怎么把照片变成环角视觉效果(无需人工标注清华)
机器之心专栏
清华大学黄高团队、快手Y-tech团队
这是一篇来自清华大学黄高团队和快手 Y-tech 团队合作的论文,该工作探究了如何在基于参考图像的生成任务中实现对于单张生成图像质量的评价。文中设计的 RISA 模型无需人工标注的训练数据,其评价结果能够与人的主观感受具有高度一致性。本工作已入选 AAAI 2022 Oral。
引言
现有的生成图像评价工作主要基于生成图像的分布对模型「整体」的生成效果进行评价。然而,一个性能优异的生成模型并不代表其合成的「任何一张」图像都具有高质量的效果。在基于参考图像(reference image)的生成任务中,譬如将用户上传的风景照渲染成某种指定的风格的业务场景中,能够对于「单张」生成图像的质量进行评价,对于提高用户的使用体验是至关重要的。
该研究提出了基于参考图像的单张生成图像质量评价方法 Reference-guided Image Synthesis Assessment(RISA)。
RISA 的贡献和创新点可以总结为以下几个方面:
- RISA 的训练图像来自于 GAN 训练过程的中间模型生成的图像,图像的质量标签来自于模型的迭代轮数,无需人工标注,理论上可用于训练的数据无上限。
- 由于以模型的迭代轮数作为标注不够精细,采用了 pixel-wise interpolation 和 mutiple binary classifiers 的方法来增强训练的稳定性。
- 引入了无监督的对比学习损失,学习参考图像和生成图像之间的风格相似度。

论文链接:http://arxiv.org/pdf/2112.04163.pdf
实现策略
RISA 的整体框架十分简洁,参考图像和生成图像经过参数共享的风格提取器得到相应的特征向量,接着计算两特征向量的 L1 距离并输入到 mutiple binary classifiers 中得到预测向量,最后预测向量元素取平均得到最终的质量分数。

RISA 的训练数据来自一系列 GAN 训练过程中的中间模型的生成图像,以下图中给出的一性别转换任务为例,可以看到,在 GAN 的训练早期,模型随着训练迭代轮数的增加,生成图像的质量会有显著的提升;而在训练后期,模型的生成图像的质量会趋于稳定。

本文采用一系列中间模型的生成图像作为 RISA 的训练数据,这些图像的样本标签由其对应模型的训练迭代轮数得到。但显然这样的标注形式不太适合训练后期的模型,因为训练后期生成图像质量不会有显著的变化。为了使训练数据更适合 RISA 的训练,文中采用了 pixel-wise interpolation 的技巧,即图像空间的线性插值,用于估计训练后期图像质量变化。
如下图所示,理想情况下,生成图像随着 GAN 的训练轮数的增加单调变好,但实际上对于简单的任务,训练后期生成图像的质量几乎没有变化;对于困难的任务,训练后期生成图像的质量随着训练轮数的增加呈现震荡变好的趋势。因此文中选取了 FID 曲线变化的肘点作为 GAN 的训练前期和后期的分界,对于训练前期直接采样中间模型生成图像,并用迭代轮数作为图像质量标签;对于训练后期,选取开始和最终的两个模型生成具有明显质量差异的图像,再对图像进行线性插值得到一系列中间质量的图像。

插值图像的一些 demo 如下动图所示,图中所示 epsilon 表示两幅图融合时的权重。

除图像空间的插值外,为了保证 RISA 的训练稳定,RISA 的预测使用的是个二值分类器(multiple binary classifers)输出取平均的形式,而没有采用简单的回归器输出拟合值。其中第个二值分类器用于预测当前生成图像质量大于一个特定阈值的概率。实验表明,将质量评估从回归问题转化为分类问题,能够显著地提升 RISA 的性能。
损失函数的设计上考虑了三个方面:1)弱监督损失,用于拟合输入参考图像 & 生成图像对及其对应的质量标签;2)无监督对比学习损失,用于捕捉参考图像和生成图像风格相似度;3)上界损失,用于学到来自真实图像的两个增强图像的风格一致性。
上界损失表达的是和风格信息完全一致,将其输入 RISA 预测结果应当对应于最高的质量分数 1。
在对比学习损失中,文中首先考虑对于参考图像做两次不同的且不破坏图像风格信息的数据增强图像和,即仅包括图像的放缩,裁剪以及翻转。生成图像与构成正样本对,对比学习损失拉近它们的预测输出;同一批输入样本中,与其对应的参考图像,与其不对应的参考图像构成负样本对,对比学习损失拉大它们的预测输出。

实验结果
文中基于四种生成模型,五个数据集上的生成图像分别训练多个 RISA 模型。首先从可视化的角度,下图说明 RISA 能够按照质量从低到高给出对应的质量评价分数。

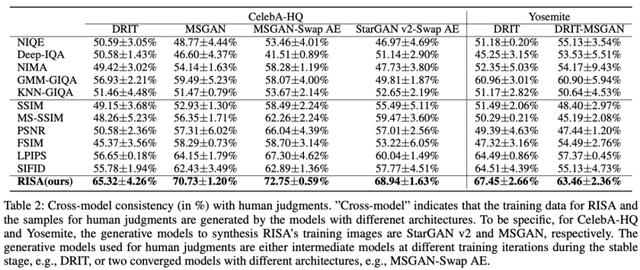
接着从量化指标的角度,文中进行了广泛的人工评价测试,以说明 RISA 评价结果和人的主观感受具有较高的一致性。具体来说,对于每个任务都选取了上千个三元组样本,包含一张参考图像和两张生成图像。两张生成图像可能来自于同一架构模型的两个不同训练阶段的中间模型,也可能来自于两个充分收敛的不同架构的模型。测试者被要求从二者中选出质量更好的一张。最终对于每个任务,保证了每组样本都有至少三个测试者参与评价,而所有评价均一致的样本被保留,用于评估 RISA 的评价与人的主观感受的一致性。
下表对应于 RISA 的训练数据和测试数据均由相同架构的模型生成的情况。可以看到 RISA 的评价结构能够与人的主观感受具有更高的一致性,且优于现有的主流的有参考和无参考单张图像质量评价方法。

下表对应于 RISA 的训练数据和测试数据均由不同架构的模型生成的情况。表中结果进一步说明 RISA 具有较好的在不同模型之间迁移的能力。
相应地,研究者提供了三元组上的 RISA 和每个数据集下最优的基线方法的可视化对比。可以看到 RISA 能够在考虑生成图像的真实程度的同时,兼具评价生成图像和参考图像的风格相似度水平的能力。

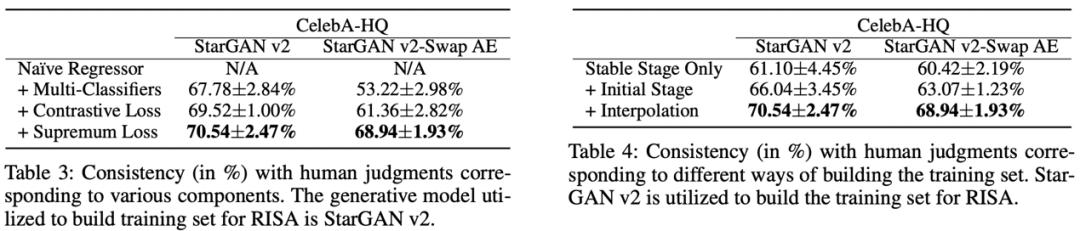
最后研究者进行了两组消融实验,说明了 RISA 引入 multiple binary classifers,pixel-wise interpolation 和其每个损失项的意义。
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






