r语言稳健性估计(R语言学习笔记七)
导语:
本期继续跟大家一起学习一份R语言资料
(https://web.stanford.edu/class/bios221/book/index.html)。上一期给大家介绍了二项式分布和泊松分布「R语言学习笔记(六)」,这里继续给大家介绍另外两种离散型分布。

1. 负二项分布
和二项分布类似,负二项分布也用于描述伯努利试验,已知一个事件在伯努利试验中每次的出现概率是p,在一连串伯努利试验中,刚好在第r k次试验出现第r次的概率。比如我们生产某个零件,合格率是p,现在抽查一批零件,直到抽到r个次品停止抽查,此时共抽查到的正品个数服从负二项分布。其分布律为:
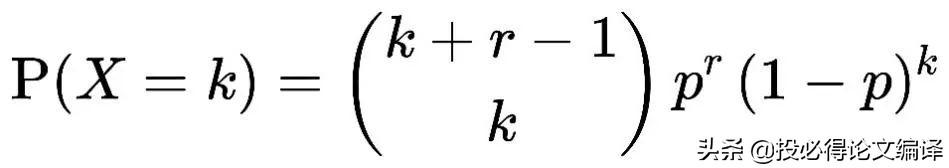
负二项分布的期望和方差分别为μ= pr/(1-p),σ2 = pr/(1-p)2,可以看出其方差大于期望。
负二项分布的一个重要应用就是模拟RNA-Seq数据中的counts数(即每个基因的reads数)。那么问题来了,为什么不用我们之前提到的二项分布和泊松分布来模拟呢?主要的原因是人们发现RNA-Seq的数据通常呈现下图特点,即期望小于方差。回顾我们之前提到的二项分布和泊松分布:
二项分布:μ = np,σ2 = np(1-p) μ < σ2
泊松分布:μ = σ2 =λ
可见这两种分布都不满足条件,因此通常用负二项分布模拟RNA-Seq数据。


2. 多项式分布
多项式分布可以看做是二项分布的推广,如果我们的试验不是伯努利试验,而是有多个结果,比如扔一个骰子得到的点数可能的取值为1到6。重复扔n次骰子,1到6出现的次数就服从一个多项式分布。再比如一段DNA序列由ATCG这4中碱基构成,每种碱基的比例是不相同的,可以认为每种碱基的个数服从多项式分布。如下图所示,可以想象n个小球随机落到4个大小不同的盒子里,落在每个盒子里球的个数也服从多项式分布。

多项式分布的分布律为:

举个例子,假如上图中4个盒子分别代表ATCG四种碱基,且比例分别为p(A)=1/8, p(T)=1/8, p(C)=3/8,p(G)=3/8。把6个小球随机装到这4个盒子里面,现计算4个盒子中分别有0、0、4、2个小球的概率:
6!/(4!*2!)*(3/8)4*(3/8)2= 0.0417
我们可以用R语言验算一下:
> dmultinom(c(0, 0, 2, 4), prob = c(1/8, 1/8, 3/8,3/8))
[1] 0.04171371

3. 检验功效
power of test statistics
3.1
定义

我们知道假设检验有两类错误,第Ⅰ类错误为H0正确拒绝H0,第Ⅱ类错误为H0错误接受H0,通常我们希望尽可能降低第Ⅰ类错误发生的概率。检验功效power与第Ⅱ类错误相反,即H0错误拒绝H0的概率,也称为false positive rate。power越大表明犯第Ⅱ类错误的可能性越小。

这张表在机器学习中又叫做混淆矩阵(Confusion Matrix),其实就是统计了各种预测结果与真实值的差异。
3.2
数据模拟

下面还是以DNA碱基为例子,假如我们要检测DNA上的一段序列中4种碱基数目是否相同,即无效假设H0:p(A) = p(T) = p(C)= p(G)=1/4。我们使用蒙特卡洛的方法来进行假设检验,首先用rmultinom函数从零假设中生成1000个模拟,每个模拟有20个碱基:
> pvec = rep(1/4, 4)
> obsunder0 = rmultinom(1000, prob = pvec, size =20)
> dim(obsunder0)
> dim(obsunder0)
[1] 4 1000
> obsunder0[, 1:11]
[,1] [,2][,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11]
[1,] 3 7 8 3 5 8 5 7 7 7 7
[2,] 4 4 6 4 4 5 3 6 5 3 5
[3,] 8 4 3 6 6 1 2 4 3 4 2
[4,] 5 5 3 7 5 6 10 3 5 6 6
矩阵obsunder0中的每一列都是一个模拟,可以看到数据的分布非常不均匀,从1到10 不等,而期望值是5。那么我们怎样检测这些数据是否服从(1/4, 1/4, 1/4, 1/4)的多项式分布呢?
3.3
假设检验

首先我们构造一个统计量stat来衡量预测值与期望值的偏差:

下面用R语言计算该统计量:
> abline(v = quantile(S0, 0.95), col ="red")
> stat = function(obsvd, exptd = 20 * pvec) { #写函数计算stat
sum((obsvd -exptd)^2 / exptd)
}
> stat(obsunder0[, 1]) #计算第一列的stat值
[1] 2.8
> S0 = apply(obsunder0, 2, stat) #计算所有列的stat值
> summary(S0)
Min. 1stQu. Median Mean 3rd Qu. Max.
0.000 1.200 2.400 3.016 4.000 17.600
> hist(S0, breaks = 25, col = "lavender",main = "")
> quantile(S0, 0.95) #95%的分位数
95%
8
> abline(v = 8, col = "red")

我们做出S0的分布直方图,其95%的分位点为8,这表明当统计量stat大于8时,我们应该拒绝原假设,比如我们obsunder0中的第一组数据,其stat值为2.8,所以应该接受H0,即认为这段DNA序列中的4种碱基个数相等。
然后我们用一个备择假设模拟出另外一组数据,并计算统计量stat。假设4种碱基的比例分别为3/8, 1/4, 1/4, 1/8,代码如下:
> pvecA = c(3/8, 1/4, 1/4, 1/8)
> observed = rmultinom(1000, prob = pvecA, size =20)
> S1 = apply(observed, 2, stat)
> power = mean(S1 > quantile(S0, 0.95))
[1] 0.193
也就是power = 0.193,这个检验功效是很低的,这是由于我们数据中的DNA序列只有20个碱基,会出现较多偶然情况。

4. 小结
R语言学习笔记系列(六)和(七)两期,给大家介绍了几种常见的离散分布,包括二项分布、泊松分布、负二项分布和多项式分布,以及用蒙特卡洛方法进行模拟计算。
抛硬币的试验是典型的伯努利试验,抛n次硬币证明向上的次数服从二项分布。可以使用函数rbinom来模拟二项分布。
泊松分布适合于p较小时的情形。它只有一个参数λ,当p较小时,λ=np的泊松分布近似于b(n, p)的二项分布。
负二项分布可用于模拟RNA-Seq数据中每个基因的reads数。
多项式分布用于描述具有两个以上可能结果或级别的离散事件,例如一段DNA序列上ATCG四种碱基的个数。
R语言学习笔记(二) R语言学习笔记(三)——实用的内置函数 R语言学习笔记(四)—pheatmap R语言学习笔记(五)——曼哈顿图 R语言学习笔记(六) -离散型数据的模型预测1 手握这些网站,分分钟搞定R语言自学 跟投必得学习R语言:第一讲 R-基本介绍及安装 有了这款高效生信分析绘图神器,还学什么R语言

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com