sql入门基础知识100例(一文带你了解不一样的SQL)
推荐阅读:太厉害了!腾讯T4大牛熬夜把Docker实战整理成了PDF文档
SQL 由 IBM 于上世纪 70 年代创建,如今已经成为了使用最广泛的数据库查询语言。不过,相信很多人对于 SQL 的理解就是关系数据库,就是增删改查;实际上,SQL 在经历了四十而不惑之后就像“姐姐们”一样成熟而有魅力,同时它又敢于在不断变化的产业需求和各种非关系模型的冲击之下实现自我突破。因此,本文就给大家介绍一下最近几年 SQL 如何在各个领域乘风破浪!

如果你认为 SQL 就是简单的增删改查(INSERT、SELECT、UPDATE、DELETE),那么你了解的仅仅是 1992 年的SQL。
如果你了解通用表表达式(CTE)和递归查询、用户定义类型或者 OLAP 功能,那么你使用的是 1999 年的 SQL。
如果你接触过窗口函数(分析函数)、MERGE(UPSERT)语句或者 XML 数据类型,应该知道这些不过是 2003 年的 SQL。
2006 年的 SQL 已经定义了 SQL 操作 XML 的规范,支持使用 XQuery 同时访问 SQL 数据和 XML 文档。2008 年又增加了 TRUNCATE TABLE 语句、INSTEAD OF 触发器以及 FETCH 子句等功能。
2011 年 SQL 最主要的新功能之一就是增强了对时态数据库(Temporal database)的支持,可以用于记录那些随着时间而变化的历史数据值,应用领域包括金融、保险、预订系统、医疗信息管理系统等。目前,MariaDB、Oracle、PostgreSQL、Microsoft SQL Server 在一定程度上实现了某些时态表功能,国内的腾讯 TDSQL 是一个全时态数据库系统。
时间来到了 2016 年,SQL 标准又增加了几个重要的功能,首先就是对 JSON 文档的支持。
一.SQL 与文档数据库
文档数据库属于 NoSQL 的一种,具有模式自由的存储特性,通常采用 JSON 格式进程数据的存储。常用的文档数据库包括 MongoDB、CouchDB 等。
实际上,2016 年 SQL 标准就已经增加了 JSON 功能的支持,包括:
- JSON 对象的存储与检索;
- 将 JSON 对象表示成 SQL 数据;
- 将 SQL 数据表示成 JSON 对象。
这些功能可以表示为以下示意图:
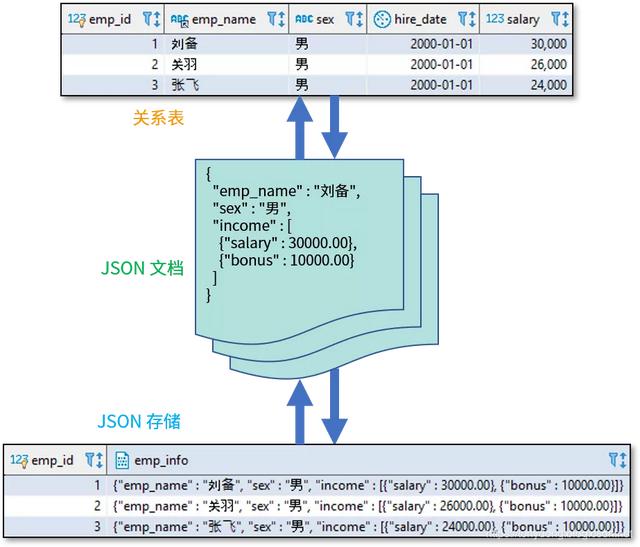
如今,主流的关系数据库也都增加了原生 JSON 数据类型和相关函数的支持,包括 Oracle、MySQL、SQL Server、PostgreSQL 等。

我们以 MySQL 为例,演示一下如何使用 SQL 查询 JSON 数据。
selectemp_id,
emp_info,
emp_info->'$.emp_name'emp_name,
emp_info->'$.sex'sex,
emp_info->>'$.income[0].salary'salary
fromemployee_json
limit3;
emp_id|emp_info|emp_name|sex|salary|
------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------|---|-------|
1|{"sex":"男","email":"liubei@shuguo.com","income":[{"salary":33000.0},{"bonus":10000}],"job_id":1,"dept_id":1,"manager":null,"emp_name":"刘备","hire_date":"2000-01-01"}|"刘备"|"男"|33000.0|
2|{"sex":"男","email":"guanyu@shuguo.com","income":[{"salary":26000},{"bonus":10000}],"job_id":2,"dept_id":1,"manager":1,"emp_name":"关羽","hire_date":"2000-01-01"}|"关羽"|"男"|26000|
3|{"sex":"男","email":"zhangfei@shuguo.com","income":[{"salary":24000},{"bonus":10000}],"job_id":2,"dept_id":1,"manager":1,"emp_name":"张飞","hire_date":"2000-01-01"}|"张飞"|"男"|24000|
其中,emp_info 字段类型为 JSON;-> 操作符返回的类型是 JSON,->> 返回的类型是字符串,使用 SQL/JSON 路径表达式获取数据中的元素值;$ 代表整个文档;$.emp_name 表示获取 JSON 对象的 emp_name 元素;$.income[0].salary 表示获取 income 数组中的第一个对象的 salary 元素,数组的下标从 0 开始。
除此之外,我们也可以将 JSON 数据转换为关系型数据。例如:
selectemp_id,jt.*
fromemployee_json,
json_table(emp_info,'$'
columns(emp_namevarchar(50)path'$.emp_name',
sexvarchar(10)path'$.sex',
dept_idintegerpath'$.dept_id',
managerintegerpath'$.manager',
hire_datedatepath'$.hire_date',
job_idintegerpath'$.job_id',
salaryintegerpath'$.income[0].salary',
bonusintegerpath'$.income[1].bonus',
emailvarchar(100)path'$.email')
)jt
limit3;
emp_id|emp_name|sex|dept_id|manager|hire_date|job_id|salary|bonus|email|
------|----------|---|-------|-------|----------|------|------|-----|-------------------|
1|刘备|男|1||2000-01-01|1|33000|10000|liubei@shuguo.com|
2|关羽|男|1|1|2000-01-01|2|26000|10000|guanyu@shuguo.com|
3|张飞|男|1|1|2000-01-01|2|24000|10000|zhangfei@shuguo.com|
其中,$ 表示将整个 emp_info 作为数据行的来源;COLUMNS 定义了字段类型及其数据的来源,PATH 同样使用 SQL/JSON 路径表达式。
反之,我们也可以通过 SQL 函数将关系型数据转换为 JSON 数据。例如:
selectjson_object('emp_name',emp_name,
'sex',sex,
'income',json_array(json_object('salary',salary),json_object('bonus',bonus))
)ASjo
fromemployee
limit3;
jo|
-------------------------------------------------------------------------------------|
{"sex":"男","income":[{"salary":30000.00},{"bonus":10000.00}],"emp_name":"刘备"}
{"sex":"男","income":[{"salary":26000.00},{"bonus":10000.00}],"emp_name":"关羽"}
{"sex":"男","income":[{"salary":24000.00},{"bonus":10000.00}],"emp_name":"张飞"}|
其中, JSON_OBJECT 和 JSON_ARRAY 函数可以将表中的数据构造成 JSON 对象和数组。
不仅如此,使用 SQL 语句也可以对 JSON 节点数据进行 DML 操作,不再介绍具体案例。关于 MySQL 文档存储的详细介绍可以参考这篇文章。
总之,关系数据库对于 JSON 数据类型的支持可以方便我们将 SQL 的强大功能与 NoSQL 的灵活性相结合;当我们需要为应用增加文档数据支持的时候,除了使用专门的 NoSQL 数据库之外,也可以考虑直接在现有的数据库中使用 JSON 数据类型。
2016 年 SQL 标准增加的另一个重要的功能就是行模式识别(Row Pattern Recognition)。
二.SQL 与复杂事件处理
SQL 行模式识别使用 MATCH_RECOGNIZE 子句表示,通过指定一个模式(正则表达式)查找多行数据之间的规律,并且可以对这些匹配的数据进行过滤、分组和聚合操作。行模式识别可以用于分析各种时间序列数据,例如股票行情数据分析、金融欺诈检测或者系统事件日志分析等。

目前只有 Oracle 12c 实现了该功能,我们可以使用以下语句找出股票曲线中的所有 V 型曲线:
--Oracle12c实现
SELECT*
FROMstockMATCH_RECOGNIZE(
PARTITIONBYscode
ORDERBYtradedate
MEASURESSTRT.tradedateASstart_date,
LAST(DOWN.tradedate)ASbottom_date,
LAST(UP.tradedate)ASend_date
ONEROWPERMATCH
AFTERMATCHSKIPTOLASTUP
PATTERN(STRTDOWN UP )
DEFINE
DOWNASDOWN.price<PREV(DOWN.price),
UPASUP.price>PREV(UP.price)
)MR
ORDERBYMR.scode,MR.start_date;
其中,MATCH_RECOGNIZE 子句比较复杂,它的执行过程如下:
- PARTITION BY scode 按照股票代码进行分区,可以同时分析多只股票的数据;如果省略,所有的数据作为一个整体进行分析,这一点与窗口函数类似;
- ORDER BY tradedate 按照交易日期进行排序,用于分析股票价格随着时间变化的规律;
- MEASURES 定义了三个输出值,分别代表 V 型曲线的起始日期、最低点日期以及结束日期;其中的 STRT、DOWN 和 UP 都是 DEFINE 选项中定义的变量;LAST(DOWN.tradedate) 表示下降曲线中的最后一个日期,也就是最低点日期;LAST(UP.tradedate) 表示上升曲线中的最后一个日期,也就是结束日期;
- ONE ROW PER MATCH 表示每次匹配只输出一个汇总结果;每个 V 型曲线输出一条记录;如果使用 ALL ROWS PER MATCH 选项,每个 V 型曲线都会输出构成曲线的所有节点,下文给出了相应的示例;
- AFTER MATCH SKIP TO LAST UP 表示找到匹配的数据后,从当前 V 型曲线的最后一个上升点(UP)重新开始下一次查找;
- PATTERN (STRT DOWN UP ) 定义了需要查找的模式,使用正则表达式语法表示。从起点(STRT)开始,先下降一次或多次(DOWN ),再上升一次或多次(UP ),也就是 V 型曲线;
- DEFINE 用于定义模式变量需要满足的条件。STRT 变量没有指定任何条件,意味着所有行都可以作为 V 型曲线的开始;DOWN 变量要求它的价格比上一行的价格更小,PREV 函数表示上一行;UP 变量要求它的价格比上一行的价格更大。
该语句返回的结果如下:
SCODE|START_DATE|BOTTOM_DATE|END_DATE|
-----|-------------------|-------------------|-------------------|
S001|2019-01-0100:00:00|2019-01-0500:00:00|2019-01-0600:00:00|
S001|2019-01-0600:00:00|2019-01-0700:00:00|2019-01-0800:00:00|
S001|2019-01-0800:00:00|2019-01-1200:00:00|2019-01-1300:00:00|
S001|2019-01-1800:00:00|2019-01-2000:00:00|2019-01-2100:00:00|
S001|2019-01-2100:00:00|2019-01-2200:00:00|2019-01-2700:00:00|
S001|2019-01-2700:00:00|2019-01-2800:00:00|2019-01-3000:00:00|
查询返回了 6 条记录,分别对应了上图中的 6 个 V 型曲线。MATCH_RECOGNIZE 支持许多选项,尤其是通过 DEFINE 变量定义和 PATTERN 正则表达式模式可以实现各种复杂的趋势分析。
SQL 行模式识别(MATCH_RECOGNIZE)能够用于检测数据流中的复杂模式,具有处理复杂事件(CEP)的强大功能。常见的应用包括侦测异常的安全行为、发现金融交易行为模式、欺诈检测和传感器数据分析等。
2019 年 SQL 标准增加了第 15 部分:ISO/IEC 9075-15:2019 多维数组(SQL/MDA)。
三.SQL 与多维数组
多维数组(Multi-Dimensional Arrays)是各种科学和工程数据的核心基础结构,包括一维传感器数据、二维卫星和显微镜扫描图像、三维图像时间序列和地球物理数据、以及四维气候和海洋数据等。
大部分的编程语言,例如 C/C 、Java、Python、R 等,都提供了数组类型和相关操作的支持。早在 1999 年,SQL 就已经对数组提供了一些非常基本的支持;最新的 SQL/MDA 允许存储、访问和处理大规模的多维数组,例如 N 通道的卫星图像。这意味着 SQL 现在可以解码图像,并且通过像素坐标直接访问和处理图像区域。

其中,MDA 表示在数据库之外的数组数据,支持格式包括 TIFF、netCDF、HDF5、JSON 等;SQL/MDA 表示数据库中存储的数组数据,支持的操作包括:
- 数组数据的摄取和存储;
- 更新存储的数组数据;
- 导出数组;
- 数组和关系数据的集成查询。
以 PostgreSQL 为例,它允许将字段定义为多维数组类型,数组的元素可以是任何内置类型、自定义类型、枚举类型、复合类型等。例如:
CREATETABLEsal_emp(
nametext,
pay_by_quarterinteger[],
scheduletext[][]
);
INSERTINTOsal_emp
VALUES('Bill',
'{10000,10000,10000,10000}',
'{{"meeting","lunch"},{"training","presentation"}}');
INSERTINTOsal_emp
VALUES('Carol',
ARRAY[20000,25000,25000,25000],
ARRAY[['breakfast','consulting'],['meeting','lunch']]);
sal_emp 表中包含两个数组字段,pay_by_quarter 是一个一维数组,schedule 是一个二维数组。
以下查询返回了 Bill 一周中的前两天计划里的第一项内容:
selectschedule[1:2][1:1]fromsal_empwherename='bill';
name|
-----|
Carol|
使用下标可以访问数组的元素,PostgreSQL 中的数组元素从 1 开始编号。以下语句用于修改数组中的数据切片:
updatesal_emp
setpay_by_quarter[1:2]='{27000,27000}'
wherename='carol';
PostgreSQL 为数组数据提供许多函数和运算符,例如以下查询使用 && 运算符查找曾经拿过 10000 报酬的员工:
selectnamefromsal_empwherepay_by_quarter&&array[10000];
name|
----|
Bill|
unnest 函数可以将数组转换为关系表,例如:
selectname,unnest(pay_by_quarter),unnest(schedule)fromsal_emp;
name|unnest|unnest|
-----|------|------------|
Bill|10000|meeting|
Bill|10000|lunch|
Bill|10000|training|
Bill|10000|presentation|
Carol|20000|breakfast|
Carol|25000|consulting|
Carol|25000|meeting|
Carol|25000|lunch|
PostgreSQL 还为数组提供了 GiST 和 GIN 类型的索引,可以优化数组数据的查询。
除此之外,基于 PostgreSQL 的 PostGIS Raster、Oracle GeoRaster 以及 rasdaman 数组数据库则提供了更加完善的多维数组应用场景支持。
四.SQL 与图形数据库
图形数据库(graph database)属于 NoSQL 的一种,使用节点、边和属性来表示和存储数据,使用图结构进行语义查询。图形数据库非常适合社交网络、人工智能、欺诈检测、推荐系统等领域中的复杂关系处理。Neo4j 是目前最著名的图形数据库。

2019 年 9 月 17 图形查询语言(GQL)成为了继 SQL 之后另一种新的 ISO 标准数据库查询语言。与此同时,SQL 标准将会出现一个新的第 16 部分(SQL/PGQ)(Property Graph Query),在 SQL 中直接提供一些 GQL 功能。
目前,MariaDB(OQGRAPH)、Oracle、Microsoft SQL Server 等关系型数据库都提供了图结构存储支持。上图是 Oracle 中一个金融交易系统的图形数据库示例,其中 Account、Person 和 Company 是顶点,ownerOf、worksFor 和 transaction 是边;另外,name 和 number 是顶点的属性,amount 是边的属性。它们可以使用以下数据表进行存储:

基于这些表可以创建以下属性图形:
CREATEPROPERTYGRAPHfinancial_transactions
VERTEXTABLES(
AccountsLABELAccount,
PersonsLABELPersonPROPERTIES(name),
CompaniesLABELCompanyPROPERTIES(name)
)
EDGETABLES(
Transactions
SOURCEKEY(from_account)REFERENCESAccounts
DESTINATIONKEY(to_account)REFERENCESAccounts
LABEL(transaction)PROPERTIES(amount),
PersonOwnerOfAccount
SOURCEPersons
DESTINATIONAccounts
LABELownerOfNOPROPERTIES,
CompanyOwnerOfAccount
SOURCECompanies
DESTINATIONAccounts
LABELownerOfNOPROPERTIES,
PersonWorksForCompany
SOURCEPersons
DESTINATIONCompanies
LABELworksForNOPROPERTIES
);
接下来我们就可以直接使用 SQL 语句查询图结构,例如以下语句查找所有和名叫 Nikita 的人有过交易的人员和信息:
SELECTowner.nameASaccount_holder,SUM(t.amount)AStotal_transacted_with_Nikita
FROMMATCH(p:Person)-[:ownerOf]->(account1:Account)
,MATCH(account1)-[t:transaction]-(account2)/*matchbothincomingandoutgoingtransactions*/
,MATCH(account2:Account)<-[:ownerOf]-(owner:Person|Company)
WHEREp.name='Nikita'
GROUPBYowner
其中,MATCH 子句用于遍历图形结构并返回匹配的模式,语法和 Neo4j 的 Cypher 查询语言中的 MATCH 子句非常类似。以上查询返回的结果如下:
---------------- ------------------------------
|account_holder|total_transacted_with_Nikita|
---------------- ------------------------------|
|Camille|1000.00|
|Oracle|4501.00|
---------------- ------------------------------
随着 SQL 标准第 16 部分(SQL/PGQ)即将出现,我们可以在关系数据库中直接存储属性图结构数据,并且在 SQL 中进行属性图模式匹配,例如最短路径查找和最佳路径查找;SQL/PGQ 的另一个优势就是可以支持分组(GROUP BY)、聚合(AVG、SUM、COUNT 等)、排序(ORDER BY)以及许多其他的 SQL 功能。
五.SQL 与流数据处理
流数据是一组顺序、大量、快速、连续到达的数据序列,一般情况下可被视为一个随时间延续而无限增长的动态数据集合。常见的流数据包括应用程序日志文件、网购数据、游戏玩家互动数据、社交网站信息、金融交易实时数据或地理空间服务,以及来自数据中心内所连接设备或仪器的遥测数据等。
目前,常用的大数据流处理平台 Spark Streaming、Storm、Flink、ksqlDB 等都提供了 SQL 流数据处理功能;同时,一个关于流数据处理的 SQL 标准部分正在准备中。
其中,ksqlDB 是一个基于 Apache Kafka 的事件流数据库,提供了轻量级的 SQL 语句,大大降低了构建流处理应用程序所需的操作复杂性。

客户端应用程序可以采用拉取查询(pull query)和推送查询(push query)两种方式查看和订阅数据流变化。
在 ksqlDB 中创建一个数据流并运行连续查询的简单示例如下:
CREATESTREAMriderLocations(profileIdVARCHAR,latitudeDOUBLE,longitudeDOUBLE)
WITH(kafka_topic='locations',value_format='json',partitions=1);
--MountainViewlat,long:37.4133,-122.1162
SELECT*FROMriderLocations
WHEREGEO_DISTANCE(latitude,longitude,37.4133,-122.1162)<=5EMITCHANGES;
首先,通过一个 Kafka 主题创建一个数据流 riderLocations(骑手位置);消息内容采用 json 格式存储,例如 {“profileId”: “c2309eec”, “latitude”: 37.7877, “longitude”: -122.4205}。
然后,针对 riderLocations 数据流运行一个连续查询,返回距离 Mountain View(加州山景城)5 英里之内的骑手。该查询会一直运行,直到被终止;并且随着事件被写入 riderLocations,它会将结果推送到客户端。
此时,如果我们打开另一个会话连接到 ksqlDB,生成一些数据流:
INSERTINTOriderLocations(profileId,latitude,longitude)VALUES('c2309eec',37.7877,-122.4205);
INSERTINTOriderLocations(profileId,latitude,longitude)VALUES('18f4ea86',37.3903,-122.0643);
INSERTINTOriderLocations(profileId,latitude,longitude)VALUES('4ab5cbad',37.3952,-122.0813);
INSERTINTOriderLocations(profileId,latitude,longitude)VALUES('8b6eae59',37.3944,-122.0813);
INSERTINTOriderLocations(profileId,latitude,longitude)VALUES('4a7c7b41',37.4049,-122.0822);
INSERTINTOriderLocations(profileId,latitude,longitude)VALUES('4ddad000',37.7857,-122.4011);
随着每次事件的生成,流查询语句将会在第一个会话中实时输出匹配的数据行。
六.总结
随着互联网和大数据等新技术的发展,SQL 早已不仅仅是当年的关系数据库查询语言了;无论是面向对象特性(例如自定义类型)、文档数据(XML、JSON)的存储和处理、时态数据的存储和处理、复杂事件和流数据处理、数据科学中的多维数组以及图形数据库等各种 NoSQL 功能已经或者即将成为 SQL 标准中的一部分,One SQL to Rule Them All!
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






