推荐一款设计用cpu(一款新型的CPUnanoPU)
来源:内容由半导体行业观察(ID:icbank)转载自公众号「网络交换FPGA」,谢谢。
远程过程调用(RPC)可能是现代计算史上最重要的一项发明。从正在运行的程序中伸出手并激活另一组代码来做某事的能力(获取数据或以某种方式操作它)是一个强大而普遍的概念,并催生了模块化编程和微服务的出现。随着SmartNIC、DPU、IPU等各种与网络相关的新一代融合计算、存储及网络资源的定制化ASIC芯片的出现,越来越多的人逐渐把目光聚集在如何进一步优化CPU与网络之间绝对时延的确定性问题上,尤其是远程过程调用(RPC)的尾部延迟问题,人们迫切希望有一种能够给出确定性时延的远程过程调用机制。这其实跟时间触发以太网或TSN比较类似,如TTE能够通过实现网络中所有节点同步后建立时刻表的方式解决掉数据从驱动进入FPGA或ASIC的NIC芯片后在网络中传播时延的确定性问题,但在有CPU的TTE端系统上却无法保障从应用程序产生数据再交给驱动后给到NIC芯片上这段时间过程的时延确定性,因为这其中不只是操作系统调度或响应中断引起的不确定性(是否是实时操作系统),单就是CPU芯片内部就有cache机制引入的不确定性、虚拟地址向物理地址转换时可能页缺失引入的不确定性以及内部各种总线冲突带来的不确定性等等。
除了时延的确定性问题外,另一方面,在缩小CPU与网络时延的研究方面,目前主要的两种解决方案是DPDK和RDMA,一种是偏软件的解决思路,另外一种是偏硬件的解决思路,但无论是哪一种方案,其目的都是为了绕过传统的协议栈把数据直接交给CPU从而减少时延。那么我们能否从CPU本身考虑,建立新的CPU与网络数据的接口,从而实现上述具有低的且确定性的时延呢?
答案是肯定的。Stephen Ibanez 是斯坦福大学的博士后,师从 Nick McKeown(P4 网络编程语言的联合开发者和 Barefoot Networks 的联合创始人,他现在是英特尔网络和边缘集团的总经理)在 OSDI '21 会议上提出了 nanoPU 概念。他解释了为什么nanoPU很重要,并可能为未来各种工作负载的其他类型的网络加速开辟道路。
在一个与过去的单体代码截然不同的世界中,代码块和跨集群运行的系统元素之间的延迟意味着一切,但减少这种延迟正在变得越来越困难。但是斯坦福大学和普渡大学的一些创新研究人员如Stephen Ibanez提出了一种协同设计的网络接口卡和 RISC-V 处理器,它提供了一条进入 CPU 的快速路径,可以显着降低 RPC 的延迟并同时使它们更具确定性时间。这项研究在最近的 USENIX 操作系统设计和实现研讨会 (OSDI '21) 上发表,相关的工作已开源,源代码已经在Github上发布https://github.com/l-nic/chipyard/tree/nanoPU-artifact-v1.0。OSDI'21全部会议论文下载链接:https://www.usenix.org/conference/osdi21/technical-sessions。
以下文中部分内容翻译自OSDI'21 nanoPU论文,还有部分内容翻译自THE NEXT PLATFORM平台文章《FORGET MICROSERVICES: A NIC-CPU CO-DESIGN FOR THE NANOSERVICES ERA》,作者Timothy Prickett Morgan。
nanoPU是经过网络优化的新型CPU,旨在最大程度地减少RPC的尾部延迟。通过绕过高速缓存和内存层次结构,nanoPU直接将到达的消息放入CPU寄存器文件中。通过应用程序的线对线延迟仅为65ns,比当前的最新技术快13倍。nanoPU将关键功能从软件转移到硬件:可靠的网络传输,拥塞控制,核心选择和线程调度。它还支持独特的功能来限制高优先级应用程序遇到的尾部延迟。
我们的原型nanoPU基于改进的RISC-V CPU。我们使用AWS FPGA上324个核心的精确周期仿真(包括实际应用程序(MICA和链复制))评估其性能。
引言
随着使用微服务架构部署更多应用程序,云服务提供商(CSP)试图降低RPC尾部延迟[4]。通过将计算划分为细粒度的任务,新的分布式应用程序正在展示在云数据中心的商用服务器上运行的出色性能(例如,视频编码[19],视频压缩[2]和人脸识别[10])。同时执行这些应用程序通常将根上的远程过程调用(RPC)请求散布到多层的大量叶子中。大多数情况下,服务级别的性能受到单个叶子的RPC尾部等待时间的限制[17]。因此,如果我们可以减少(甚至限制)RPC尾部延迟,则分布式应用程序将运行得更快。
现代CSP试图通过引入具有快速RDMA和运行低延迟微服务的NIC驻留CPU内核的专用NIC硬件[6,38]来解决此问题。根据经验,微服务需要5-10µs的调用时间,因此只有在我们发送它超过10µs的计算时才值得调用[27,41,28]。相比之下,我们的工作目标是实现有效的亚微秒RPC,该RPC可以在服务器上以不到1µs的通信开销被调用。我们在本文中使用的一个关键指标是线到线的延迟,定义为从RPC请求消息的第一个比特到达NIC,到已处理的RPC响应的第一个比特离开NIC的时间。报告的最佳线对线延迟中值约为850ns[28]。我们的目标是将中位数和尾数都减少到100ns以下,因此值得运行“ nanoServices”。短的RPC需要少于1µs的工作时间。
减少RPC开销的许多先前尝试包括低延迟和无损交换机[30、35、8],减少的网络层数和专用库[28]。当前最快的方法是部署专用的NIC和交换器硬件,但是很难编程[25、24、26、50]。
我们的工作提出了一个问题:我们可以设计一个易于编程的未来CPU内核,但可以以绝对最小的开销和尾部延迟来服务RPC请求吗?我们的设计被称为nanoPU,除了常规处理之外,还可以看作是针对亚微秒RPC服务优化的未来CPU内核的模型。另外,nanoPU可以被认为是一类新型的特定域的nanoService处理器,设计用于安装在smartNIC上,或者是一个独立的集群,可以服务于亚微秒RPC。例如,今天要构建具有100个100GE接口的类似于Celerity [15]的单芯片512核nanoPU,以每秒10Tb/s的速度服务于每秒超过5亿个RPC。这种设备可以从根本上改善大型分布式应用程序的性能。
我们的方法基于四个主要观察结果:首先,我们需要最小化从RPC请求数据包通过以太网到达到开始在运行线程中进行处理的时间。nanoPU通过用硬件替换软件线程调度程序和核心选择器(即负载均衡器)来完成此任务。通过完全绕过PCIe,主内存和缓存层次结构;通过将RPC数据直接放入CPU寄存器文件中;通过用硬件中可靠的传输层替换主机网络软件堆栈,将完整的RPC消息传递到CPU。其次,我们需要最小化网络拥塞。nanoPU通过硬件(使用可编程的P4管道[23])实现NDP [20],从而减少了拥塞并提高了播报性能。第三,我们需要通过流水线化报头和传输层处理,线程调度和硬件中的内核选择来最大化RPC吞吐量。nanoPU在NIC中包括P4 PISA管道[9],可并行处理多个数据包并重新组合RPC消息。最后,大型分布式应用的性能往往受到RPC尾部延迟的限制;因此,在处理RPC时,我们需要控制和最小化尾延迟。nanoPU提供了我们认为是第一个有界尾延迟RPC服务,从而确保符合要求的RPC请求将在例如到达NIC的1µs内完成服务。
我们的贡献:总之,我们做出以下研究贡献:
nanoPU:NIC和CPU的新颖共同设计,可最大程度地减少RPC尾部延迟。我们的设计包括:(1)NIC中的专用内存层次结构,直接连接到CPU寄存器文件,(2)低延迟硬件传输逻辑,内核选择和线程调度,以及(3)通过限制消息来限制尾部延迟处理时间。
nanoPU的开源原型扩展了具有200Gb/s网络接口的RISC-V火箭核心[46],通过在AWS F1 FPGA实例上可重复的精确循环模拟进行了评估。
演示(1)的线对线延迟仅为65ns(没有以太网MAC和串行I / 0时为13ns),比报告的最佳结果快13倍;(2)每个核的吞吐量为200 Gb/s,比内核报告的速度快2.5倍最先进的技术,(3)NIC中的处理速度为350 Mpkts/s(包括传输和核心选择逻辑),比Shinjuku [27],Shenango [41]和eRPC [28]软件解决方案快50倍,4)硬件抢先式线程调度,可在高负载下在2.1µs以下实现99%的尾部等待时间;(5)第一个确定最终RPC尾部等待时间的系统;以及(6)硬件中的高效内核选择算法。
可靠,低延迟的NDP [20]传输层和拥塞控制的硬件实现。据我们所知,这是对学术机构实施的硬件传输协议的首次端到端评估。
我们演示了一个键值存储(MICA [34]),它在1.1µs(不包括切换延迟)中存储3次复制写操作,比现有技术[26]快8倍。
架构设计
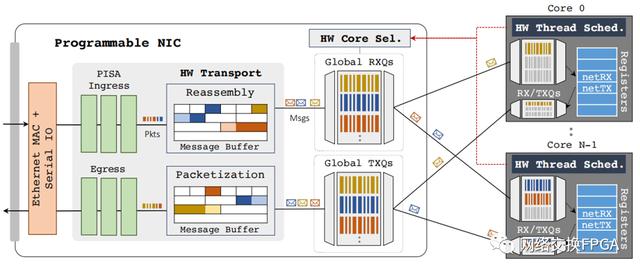
图1:nanoPU设计。NIC包括入口和出口PISA管道以及硬件终止的传输和具有全局RX队列的核心选择器。每个CPU内核都增加了硬件线程调度程序和直接连接到寄存器文件的本地RX / TX队列。
图1是nanoPU的框图。在这里,我们依次描述每个架构块。
2.1 硬件端接的传输逻辑传输逻辑在硬件中执行三个主要的流水线任务:(1)处理数据包头,例如VXLAN,覆盖隧道,加密和解封装;(2)在以太网帧和应用程序消息(例如RPC请求和响应)之间转换;以及(3)执行拥塞控制以减少网络内延迟。
与TCP提供的可靠的双向字节流相反,nanoPU传输逻辑为应用程序提供了可靠的单向消息传递的抽象。可靠的单向消息传递可以在硬件中有效地实现:它只需要维护每个消息的状态,而不是每个连接的状态,因此一旦成功将消息传递到目标,就可以释放该状态(远程主机或本地核心)。每个消息的状态要求很小;除了存储实际的消息,我们还保留了每个消息的接收包的位图,以及一些用于拥塞控制的字节。同步RPC通信的数量与未处理消息的数量呈线性比例关系,而不是与数据中心中的主机数量成线性比例关系,从而允许涉及数千个nanoPU的大规模,高度分布式应用程序。我们并不是第一个在传输层上建议可靠的消息抽象的人[37,20],但是我们相信我们是第一个将其放在可编程硬件中的人,可以比较多种传输算法。
硬件传输层可以被大量流水线化,允许它同时处理几个包,并释放CPU来关注它应该运行的应用程序代码。作为第二个好处,通过在固定延迟的硬件管道中实施传输逻辑,处理每个数据包的尾部延迟显着低于软件中运行的相同算法。此外,硬件传输层的响应速度比软件快,导致端点之间的拥塞控制环路更紧密,因此网络使用效率更高。
在硬件中实现可编程传输逻辑需要支持NIC中的以下功能:
打包/重发缓冲区,用于将消息分解为数据包,并存储传出的数据包,直到接收方确认它们为止。
重组缓冲区以处理乱序数据包。
计时器和基于计时器的事件处理逻辑,用于状态转换,例如重传和后台维护任务。
调度程序决定传出数据包的顺序。
状态机保持每个消息的状态,包括当前的速率或拥塞窗口大小,序列和确认号以及消息状态;并保持计数器。
数据包生成器支持传输协议,这些传输协议响应数据平面事件(例如数据包的到达或数据包丢失的检测)生成控制数据包。
可以借助P4可编程的,事件驱动的PISA管道来实现传输逻辑[22]。专业可移植性使我们能够比较不同的传输层,并允许网络所有者创建新的解决方案,并可能动态部署特定于工作负载的传输层。可编程管道意味着新的行速率包处理很容易添加而不会减慢CPU核心中的应用程序处理,例如网络遥测[32]或新的协议头。
2.2 专为网络打造的无竞争IO
最近的工作表明,长尾延迟可能是由主内存的带宽争用引起的。到达和离开的网络数据包数据通过应用程序的内存访问来争夺内存带宽[47,48]。应用程序通常按顺序处理网络数据。因此,首先,随机存取存储器不是用于联网的正确资源类型。相反,nanoPU维护专用于网络数据的两个级别的FIFO队列,从而允许独立,顺序,无竞争的读写,如图1所示。在接收路径上,两个级别的FIFO包括本地内核之间共享的核心RX队列和全局RX队列。3在传输路径上,有一组对应的本地和全局TX队列,用于存储应用程序编写的各个消息字。
当运行在内核上的应用程序线程希望执行网络IO时,它将绑定到第4层端口号。然后,nanoPU为端口分配本地和全局RX / TX队列。在同一核心上运行的线程必须绑定到不同的端口号,但是在不同核心上运行的线程被允许绑定到相同的端口号,从而允许多个核心处理来自同一全局RX队列的消息。
每核FIFO直接连接到CPU寄存器文件中的两个通用寄存器(GPR);网络RX和TX队列的头(netRX)和尾(netTX)。为了接收消息,应用程序仅从GPR netRX读取,从网络RX队列的头部提取数据。类似地,为了发送消息,应用程序将GPR netTX写入与网络TX队列尾部相对应的位置。硬件确保为当前线程读取和写入正确的队列,以防止在单独的线程之间泄漏数据。
尽管可以通过多种不同方式对通用体系结构进行分区和打包,但在此我们假设nanoPU芯片包含NIC和内核,并且所有缓冲区和FIFO存储器都集成在同一芯片上。因此,到达的数据会遍历到每个核心的专用点对点链接,而无需等待共享的PCIe总线。
2.3 硬件核心选择
必须将到达的消息调度到内核,以由应用程序线程进行处理。如果将线程固定到单个内核,则选择是明确的。但是更常见的是,应用程序在许多内核上运行线程,我们希望将到达的消息调度到空闲的内核。理想情况下,NIC将维护单个工作保存的全局RX队列,空闲核心可以从该队列中提取其下一条消息以进行处理,从而使预期的等待时间最短。但是这种设计是不切实际的,要求所有内核同时从单个全局RX队列中读取。在另一种极端情况下,NIC为每个核心维护一个RX队列,某些消息将卡在繁忙的核心的RX队列中,而其他核心则处于空闲状态。
已经证明,Join-Bounded-Shortest-Queue或JBSQ(n)是理想的单队列系统的很好的近似值[33,47],并且在硬件中很实用。JBSQ(n)使用集中式队列以及每个核心的最大深度为n的短边界队列的组合。当每个核心队列有可用空间时,集中式队列将首先补充最短队列。JBSQ(1)等效于单队列模型。
nanoPU在硬件中实施JBSQ(n)策略,该策略非常自然地映射到图1中的两层RX队列,每个第4层端口号(即应用程序)有一个中央RX队列。默认情况下,我们使用JBSQ(2),尽管可以将设计配置为使用不同的n值。我们将实现细节推迟到3.2节。
2.4 硬件线程调度
nanoPU线程调度程序有几个要求。首先,它必须频繁且迅速地做出决策。最好的最新操作系统每5µs做出一次调度决定[27,41],这使得它们的粒度太粗,无法以亚微秒的处理时间来调度RPC。因此,nanoPU线程调度程序在硬件中运行。这使得调度决策可以与应用程序处理连续且并行地进行,而无需等待计时器中断来启动到软件调度程序的上下文切换。
其次,线程调度程序必须跟踪当前哪些线程可以进行调度。如果线程已注册(这意味着已分配端口号和RX / TX队列),并且该线程的本地RX队列中正在等待消息,则该线程被标记为活动线程,因此可以进行调度。线程保持活动状态,直到线程显式地指示它是空闲的或者它的本地RX队列是空的。
第三,线程调度程序必须选择下一个要运行的线程。每个线程都有严格的优先级。优先级较高的活动线程将抢占优先级较低的活动线程,而优先级相同的线程则按FIFO顺序处理消息。如下所述,线程的优先级是动态的:运行时可以将其从优先级0降级为优先级1。
第四,线程调度程序是nanoPU所独有的,它支持有保证的服务时限,以使应用程序一致。该保证只能提供给优先级为0的线程,它通过限制其消息处理时间来起作用。如果优先级为0的线程花费的时间超过x µs来处理消息,则调度程序将立即将其优先级从0降级为1,从而允许其被具有待处理消息的其他优先级0线程抢占。(默认情况下,x = 1µs。)如果将一个内核配置为最多运行k个优先级为0的应用程序线程,并且设计这些应用程序时,每个应用程序在给定时刻只有一条消息未处理,则消息处理的尾部等待时间为应用程序的边界为:max(latency)≤N kx (kk 1)c,其中N是NIC延迟,而c是上下文切换延迟。即使内核上的某些应用程序行为不正常且处理消息所需的时间超过xµs,此限制仍然适用于其他应用程序。
最后,线程调度程序会告诉操作系统何时更改线程。它通过在以下情况下触发中断来做到这一点:
当前在内核上运行的线程不再是优先级最高的活动线程。发生这种情况的原因可能有几个:(1)消息到达的优先级比当前运行的线程高;(2)优先级高的线程完成其消息的处理并变为空闲状态;或者(3)优先级0的线程超出了该线程的优先级。最大允许处理时间,其优先级降低为1。
所有线程都处于空闲状态,并且当前线程超过了空闲超时。在这种情况下,调度程序将轮流遍历所有运行中的线程,以确保它们都能取得进展。
为了完成其工作,线程调度程序将三条信息作为输入:(1)每个线程的状态(活动或空闲;(2)每个线程的优先级;以及(3)消息在头部的时间戳每个队列。
其它评价
以网络为中心的计算可将计算和数据处理从CPU卸载到并分解到CPU,以支持不断增长的吞吐量,大数据量和数据中心的信息复杂性。一个新兴的范例是采用SmartNIC进行以网络为中心的计算,它在主机的网络接口上引入了特定于用户的处理。那么是否可以对CPU芯片本身进行改进,使其更加适用于大量网络数据的收发处理呢?nanoPU就是从这个角度来展开研究的。
托管在超大规模者和云构建者的大型应用程序——搜索引擎、推荐引擎和在线事务处理应用程序只是三个很好的例子——使用远程过程调用或 RPC 进行通信。现代应用程序中的 RPC 散布在这些大规模分布式系统中,完成一些工作通常意味着等待最后一位数据被操纵或检索。正如我们之前多次解释的那样,大规模分布式应用程序的尾部延迟通常是应用程序整体延迟的决定因素。这就是为什么超大规模者总是试图在跨系统网络的所有通信中获得可预测的、一致的延迟,而不是试图驱动尽可能低的平均延迟并让尾部延迟到处游荡。
Ibanez 说,nanoPU 研究开始着手回答这个问题:要绝对最小化 RPC 中值和尾延迟以及软件处理开销需要什么?
“在管理尾部延迟和小消息吞吐量方面,传统的 Linux 堆栈效率非常低,”Ibanez 在他的演示文稿中解释道,您可以在这里看到。(OSDI'21会议论文下载链接:https://www.usenix.org/conference/osdi21/technical-sessions。)“网络社区已经意识到这一点,并一直在探索许多提高性能的方法。”
下表概述了这些努力:
nanoPU 论文中使用的线对线延迟的定义非常清楚,对于上述任何一种方法,都是从以太网线到用户空间应用程序再返回到线的时间。有使用内核绕过技术的自定义数据平面操作系统。但是,尝试将特定 IPC 放到特定可用 CPU 线程上的软件开销是繁重的,并且最终会变得非常粗粒度。您可以获得介于 2 微秒和 5 微秒之间的中值延迟,但尾部延迟可能介于 10 微秒到 100 微秒之间。因此,这不适用于细粒度任务,例如在现代应用程序中使用 RPC 变得越来越普遍的任务。
还有专门的 RPC 库可以减少延迟并提高吞吐量——卡内基梅隆大学和英特尔实验室的 eRPC就是一个很好的例子——但 Ibanez 说他们没有足够地控制尾部延迟,这对整体性能来说是一个问题。所以还有其他方法可以将传输协议卸载到硬件,但保持 RPC 软件在 CPU 上运行(例如普林斯顿大学的 Tonic),这可以提高吞吐量,但只能解决部分问题。虽然许多商用网络接口卡 (NIC) 支持 RDMA 协议很棒,而且 RDMA 的中位线对线延迟可以低至 700 纳秒也很棒,但问题是无数的小围绕分布式计算集群的 RPC 需要远程访问计算,而不是内存。因此,我们需要远程直接计算访问。
要做到这一点,正如 nanoPU 项目所示,答案是创建一条进入 CPU 寄存器文件本身的快速路径,并绕过所有可能会阻碍的硬件和软件协议栈。为了测试这个想法,斯坦福大学和普渡大学的研究人员创建了一个定制的多核 RISC-V 处理器和一个支持 RPC 的 NIC,并运行了一些测试来证明这个概念有一定的有效性。
这不是一个新概念,而是该想法的新实现。该Nebula NIC项目(论文链接:https://www.cc.gatech.edu/~adaglis3/files/papers/nebula_isca20.pdf),如上表所示,这样做是由NIC与CPU整合,并将中值延迟降低到100纳秒的范围内,这是非常好的,但尾部延迟仍然在2微秒到5微秒之间(数据平面操作系统对中值延迟所做的)。然而斯坦福大学和普渡大学的技术人员表示,还有更多空间来改进驱动延迟和吞吐量。(Nebula NIC 是瑞士 EPFL、美国佐治亚理工学院和雅典国立技术大学与 Oracle 实验室合作开发的。)
这是 nanoPU 的样子:
nanoPU 实现了多核处理器,带有您可能想象的硬件线程调度程序,每个都有自己的专用收发器队列,与 NIC 集成,并且与 Tonic 一样,它具有在 NIC 硬件中实现的可编程传输。对于那些延迟更长且不需要从网络直接进入CPU寄存器的快速路径的应用程序,从NIC中的硬件传输到最后一级缓存或CPU主内存的DMA路径仍然存在。硬件线程调度程序独立运行,不让操作系统运行,因为这会增加操作系统协议栈上下的巨大延迟。
在 FPGA 中实现的 nanoPU 原型被模拟为以 3.2GHz 的频率运行,这与当今最高速度的 CPU 差不多,并使用改进的五级“Rocket”RISC-V 内核。线对线延迟仅为 69 纳秒,单个RISC-V内核每秒可以处理1.18亿个RPC调用。(在一个72B的数据包中包含8B的消息。)
与支持 RDMA 的 NIC 相比,nanoPU 可以通过传统应用程序运行单边 RDMA:
我们假设这是图表左侧的 InfiniBand,但不知道年份;它可以是带有 RoCEv2 的以太网。
以下是 nanoPU 运行 MICA 键值存储的方式,该存储也来自卡内基梅隆和英特尔实验室:
正如您所看到的,与传统RDMA方法相比,nanoPU在这个键值存储上可以提高吞吐量,并且显著降低延迟——同时也可以做到这一点。
看起来我们可能需要一个新标准来允许所有 CPU 支持嵌入式 NIC,而无需让任何人承诺使用任何特定的嵌入式 NIC。或者,更有可能的是,每个 CPU 供应商都有自己的嵌入式 NIC 风格,并试图将两者的性能和收入联系起来。市场总是在开放之前就拥有所有权。毕竟,这是实现销售额和利润最大化的最佳途径。
顺便说一下,nanoPU 工作是由赛灵思、谷歌、斯坦福大学和美国国防高级研究计划局资助的。
最后一个想法是:这种方法不是很好的MPI加速器吗?早些时候,根据nanoPU的论文,J-Machine超级计算机和Cray T3D就支持类似于RPC的低延迟、内核间通信,但因为它们需要原子读写,所以很难阻止线程读写它们不应该读写的东西。nanoPU中的集成线程调度程序似乎通过其寄存器接口解决了这个问题。也许有一天所有的CPU都会有注册接口,就像它们集成了PCI Express和以太网接口一样。
参考文献:
[1] Amazon ec2 f1 instances. https://aws.amazon.com/ec2/instance-types/f1/. Accessed on 2020-08-10.
[2] Lixiang Ao, Liz Izhikevich, Geoffrey M. Voelker, and George Porter.Sprocket: A Serverless Video Processing Framework. In ACM SoCC,2018.
[3] Mina Tahmasbi Arashloo, Alexey Lavrov, Manya Ghobadi, Jennifer Rexford, David Walker, and David Wentzlaff. Enabling programmable transport protocols in high-speed nics. In 17th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 20), pages 93–109, 2020.
[4] Michael Armbrust, Armando Fox, Rean Griffith, Anthony D. Joseph,Randy H. Katz, Andrew Konwinski, Gunho Lee, David A. Patterson,Ariel Rabkin, Ion Stoica, and Matei Zaharia. Above the clouds: A berkeley view of cloud computing. Technical Report UCB/EECS-2009-28, EECS Department, University of California, Berkeley, Feb 2009.
[5] Krste Asanovic, Rimas Avizienis, Jonathan Bachrach, Scott Beamer,David Biancolin, Christopher Celio, Henry Cook, Daniel Dabbelt,John Hauser, Adam Izraelevitz, et al. The rocket chip generator. EECS Department, University of California, Berkeley, Tech. Rep. UCB/EECS-2016-17, 2016.
[6] Aws nitro system. https://aws.amazon.com/ec2/nitro/. Accessed on 02/04/2020.
[7] Jonathan Bachrach, Huy Vo, Brian Richards, Yunsup Lee, Andrew Waterman, Rimas Avižienis, John Wawrzynek, and Krste Asanovi´c. Chisel: constructing hardware in a scala embedded language. In DAC Design Automation Conference 2012, pages 1212–1221. IEEE, 2012.
[8] Carsten Binnig, Andrew Crotty, Alex Galakatos, Tim Kraska, and Erfan Zamanian. The end of slow networks: It’s time for a redesign.Proc. VLDB Endow., 9(7):528–539, March 2016.
[9] Pat Bosshart, Glen Gibb, Hun-Seok Kim, George Varghese, Nick McKeown, Martin Izzard, Fernando Mujica, and Mark Horowitz. Forwarding metamorphosis: Fast programmable match-action processing in hardware for sdn. ACM SIGCOMM Computer Communication Review, 43(4):99–110, 2013.
[10] Joao Carreira, Pedro Fonseca, Alexey Tumanov, Andrew Zhang, and Randy Katz. Cirrus: A Serverless Framework for End-to-End ML Workflows. In ACM SoCC, 2019.
[11] Yanzhe Chen, Xingda Wei, Jiaxin Shi, Rong Chen, and Haibo Chen. Fast and general distributed transactions using rdma and htm. In Proceedings of the Eleventh European Conference on Computer Systems,pages 1–17, 2016.
[12] Alexandros Daglis, Mark Sutherland, and Babak Falsafi. Rpcvalet: Ni-driven tail-aware balancing of µs-scale rpcs. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, pages 35–48, 2019.
[13] William J Dally, Andrew Chien, Stuart Fiske, Waldemar Horwat, an John Keen. The j-machine: A fine grain concurrent computer. Technical report, MASSACHUSETTS INST OF TECH CAMBRIDGE MICROSYSTEMS RESEARCH CENTER, 1989.
[14] Francis M. David, Jeffrey C. Carlyle, and Roy H. Campbell. Context switch overheads for linux on arm platforms. In Proceedings of the 2007 Workshop on Experimental Computer Science, ExpCS ’07, page 3–es, New York, NY, USA, 2007. Association for Computing Machinery.
[15] Scott Davidson, Shaolin Xie, Christopher Torng, Khalid Al-Hawai,Austin Rovinski, Tutu Ajayi, Luis Vega, Chun Zhao, Ritchie Zhao,Steve Dai, et al. The celerity open-source 511-core risc-v tiered accelerator fabric: Fast architectures and design methodologies for fast chips. IEEE Micro, 38(2):30–41, 2018.
[16] Intel corporation. intel data direct i/o technology (intel ddio): A primer. https://www.intel.com/content/dam/www/public/us/en/documents/technology-briefs/data-direct-i-o-technology-brief.pdf. Accessed on 2020-08-17.
[17] Jeffrey Dean and Luiz André Barroso. The tail at scale. Communications of the ACM, 56(2):74–80, 2013.
[18] nanoPU GitHub. https://github.com/l-nic. Accessed on 08/17/2020.
[19] Sadjad Fouladi, Riad S Wahby, Brennan Shacklett, Karthikeyan Vasuki Balasubramaniam, William Zeng, Rahul Bhalerao, Anirudh Sivaraman, George Porter, and Keith Winstein. Encoding, Fast and Slow:Low-latency Video Processing Using Thousands of Tiny Threads. In USENIX NSDI, 2017.
[20] Mark Handley, Costin Raiciu, Alexandru Agache, Andrei Voinescu, Andrew W Moore, Gianni Antichi, and Marcin Wójcik. Re-architecting datacenter networks and stacks for low latency and high performance.In Proceedings of the Conference of the ACM Special Interest Group on Data Communication, pages 29–42, 2017.
[21] Ram Huggahalli, Ravi Iyer, and Scott Tetrick. Direct cache access for high bandwidth network i/o. In Proceedings of the 32nd Annual International Symposium on Computer Architecture, ISCA ’05, page 50–59, USA, 2005. IEEE Computer Society.
[22] Stephen Ibanez, Gianni Antichi, Gordon Brebner, and Nick McKeown. Event-driven packet processing. In Proceedings of the 18th ACM Workshop on Hot Topics in Networks, pages 133–140, 2019.
[23] Stephen Ibanez, Muhammad Shahbaz, and Nick McKeown. The case for a network fast path to the cpu. In Proceedings of the 18th ACM Workshop on Hot Topics in Networks, pages 52–59, 2019.
[24] Zsolt István, David Sidler, and Gustavo Alonso. Caribou: Intelligent distributed storage. Proc. VLDB Endow., 10(11):1202–1213, August 2017.
[25] Zsolt István, David Sidler, Gustavo Alonso, and Marko Vukolic. Consensus in a box: Inexpensive coordination in hardware. In Proceedings of the 13th Usenix Conference on Networked Systems Design and Implementation, NSDI’16, page 425–438, USA, 2016. USENIX Association.
[26] Xin Jin, Xiaozhou Li, Haoyu Zhang, Nate Foster, Jeongkeun Lee,Robert Soulé, Changhoon Kim, and Ion Stoica. Netchain: Scale-free sub-rtt coordination. In 15th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 18), pages 35–49, 2018.
[27] Kostis Kaffes, Timothy Chong, Jack Tigar Humphries, Adam Belay, David Mazières, and Christos Kozyrakis. Shinjuku: Preemptive scheduling for µsecond-scale tail latency. In 16th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 19),pages 345–360, 2019.
[28] Anuj Kalia, Michael Kaminsky, and David Andersen. Datacenter rpcs can be general and fast. In 16th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 19), pages 1–16, 2019.
[29] Anuj Kalia, Michael Kaminsky, and David G Andersen. Using rdma efficiently for key-value services. In Proceedings of the 2014 ACM conference on SIGCOMM, pages 295–306, 2014.
[30] Anuj Kalia, Michael Kaminsky, and David G Andersen. Fasst: Fast, scalable and simple distributed transactions with two-sided ({RDMA}) datagram rpcs. In 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16), pages 185–201, 2016.
[31] Sagar Karandikar, Howard Mao, Donggyu Kim, David Biancolin, Alon Amid, Dayeol Lee, Nathan Pemberton, Emmanuel Amaro,Colin Schmidt, Aditya Chopra, et al. Firesim: Fpga-accelerated cycle-exact scale-out system simulation in the public cloud. In 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), pages 29–42. IEEE, 2018.
[32] Changhoon Kim, Anirudh Sivaraman, Naga Katta, Antonin Bas, Advait Dixit, and Lawrence J Wobker. In-band network telemetry via programmable dataplanes. In ACM SIGCOMM, 2015.
[33] Marios Kogias, George Prekas, Adrien Ghosn, Jonas Fietz, and Edouard Bugnion. R2p2: Making rpcs first-class datacenter citizens. In 2019 {USENIX} Annual Technical Conference ({USENIX}{ATC} 19), pages 863–880, 2019.
[34] Hyeontaek Lim, Dongsu Han, David G Andersen, and Michael Kaminsky. {MICA}: A holistic approach to fast in-memory key-value storage.In 11th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 14), pages 429–444, 2014.
[35] Feilong Liu, Lingyan Yin, and Spyros Blanas. Design and evaluation of an rdma-aware data shuffling operator for parallel database systems. In Proceedings of the Twelfth European Conference on Computer Systems, EuroSys ’17, page 48–63, New York, NY, USA, 2017. Association for Computing Machinery.
[36].Mellanox bluefield-2. https://www.mellanox.com/products/bluefield2-overview. Accessed on 02/04/2020.
[37] Behnam Montazeri, Yilong Li, Mohammad Alizadeh, and John Ousterhout. Homa: A receiver-driven low-latency transport protocol using network priorities. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, pages 221–235, 2018.
[38] Naples dsc-100 distributed services card. https://www.pensando.io/assets/documents/Naples_100_ProductBrief-10-2019.pdf.Accessed on 02/04/2020.
[39] Stanko Novakovic, Alexandros Daglis, Edouard Bugnion, Babak Falsafi, and Boris Grot. Scale-out numa. ACM SIGPLAN Notices, 49(4):3–18, 2014.
[40] Options for Code Generation Conventions. https://gcc.gnu.org/onlinedocs/gcc/Code-Gen-Options.html#Code-Gen-Options. Accessed on 02/04/2020.
[41] Amy Ousterhout, Joshua Fried, Jonathan Behrens, Adam Belay, and Hari Balakrishnan. Shenango: Achieving high {CPU} efficiency for latency-sensitive datacenter workloads. In 16th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 19), pages 361–378, 2019.
[42] John Ousterhout, Arjun Gopalan, Ashish Gupta, Ankita Kejriwal, Collin Lee, Behnam Montazeri, Diego Ongaro, Seo Jin Park, Henry Qin, Mendel Rosenblum, Stephen Rumble, Ryan Stutsman, and Stephen Yang. The ramcloud storage system. ACM Trans. Comput.Syst., 33(3), August 2015.
[43] George Prekas, Marios Kogias, and Edouard Bugnion. Zygos: Achieving low tail latency for microsecond-scale networked tasks. In Proceedings of the 26th Symposium on Operating Systems Principles, pages 325–341, 2017.
[44] Redis. https://redis.io/. Accessed on 2020-08-12.
[45] Risc-v specifications. https://riscv.org/technical/specifications/. Accessed on 2020-08-17.
[46] Rocket-chip github. https://github.com/chipsalliance/rocket-chip. Accessed on 08/17/2020.
[47] Mark Sutherland, Siddharth Gupta, Babak Falsafi, Virendra Marathe,Dionisios Pnevmatikatos, and Alexandros Daglis. The nebula rpcoptimized architecture. Technical report, 2020.
[48] Amin Tootoonchian, Aurojit Panda, Chang Lan, Melvin Walls, Katerina Argyraki, Sylvia Ratnasamy, and Scott Shenker. Resq: Enabling slos in network function virtualization. In 15th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 18), pages 283–297, 2018.
[49] Verilator. https://www.veripool.org/wiki/verilator. Accessed on 2020-01-29.
[50] Zhuolong Yu, Yiwen Zhang, Vladimir Braverman, Mosharaf Chowdhury, and Xin Jin. Netlock: Fast, centralized lock management using programmable switches. In Proceedings of the Annual Conference of the ACM Special Interest Group on Data Communication on the Applications, Technologies, Architectures, and Protocols for Computer Communication, SIGCOMM ’20, page 126–138, New York, NY, USA,2020. Association for Computing Machinery.
[51] Yibo Zhu, Haggai Eran, Daniel Firestone, Chuanxiong Guo, Marina Lipshteyn, Yehonatan Liron, Jitendra Padhye, Shachar Raindel, Mohamad Haj Yahia, and Ming Zhang. Congestion control for large-scale rdma deployments. ACM SIGCOMM Computer Communication Review, 45(4):523–536, 2015.
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2798内容,欢迎关注。
晶圆|集成电路|设备|汽车芯片|存储|台积电|AI|封装
,





免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






