推荐系统的推荐方法包括(推荐系统多样性)
多样性和相关性是衡量推荐系统的常用的指标,这两个指标同时影响着推荐系统的商业目标和用户体验。相关性主要通过用户兴趣和Item之间的匹配程度来衡量,希望把用户感兴趣Item推荐给用户,可以通过CTR预估模型来构建。多样性的衡量没有那么直观,一种常见方法是计算不同Item之间的Cosine值,值越小表明多样性越好。
MAP众数(mode),指一组中出现次数最多的数据值。
MAP(Maximum a Posteriori),最大化后验概率估计来源于贝叶斯统计学,其估计值是后验概率分布的众数,如下:

其中,x为观测数据、theta为需要估计的参数、f(x)为x的采样分布、f(x|theta)为参数为theta时x的概率(theta的最大似然估计就是似然函数f(x|theta)取最大值时theta的值)。
假设theta的先验分布为g(x),在上面等式中,由于分母与theta无关,则最大化后验估计通过最大化f(x|theta)g(theta)求得,即后验分布的众数。当theta先验分布为常数时,最大后验估计与最大似然估计重合。
DPPDPP(Determinantal Point Process)行列式点过程,是一种性能较高的概率模型,其将复杂的概率计算转换成简单的行列式计算,通过核矩阵的行列式计算每一个子集的概率。DPP在图片分割、文本摘要和商品推荐系统中均具有较成功的应用。
具体地,行列式点过程P刻画的是一个离散集合Z={1,2,...M}中每一个子集出现的概率。当P对于给定空集合出现的概率非零时,存在一个由集合Z的元素构成的半正定矩阵L包含于R^M*M,对于每一个集合Z的子集Y,Y出现的概率满足:
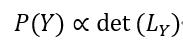
L_Y表示由行和列的下标属于Y构成的L的子矩阵。以商品推荐为例,DPP通过最大后验概率估计,找到商品集中相关性和多样性最大的子集,作为推荐商品集返回给用户。即有:

Cholesky分解:当L是正定矩阵时,Cholesky分解是唯一的,即只存在一个对角元素均严格大于零的下三角矩阵V,使L=VV*成立;当L是半正定矩阵时,分解不一定唯一。
分块矩阵求逆公式:设A是m*m可逆矩阵,B是m*n矩阵,C是n*m矩阵,D是n*n矩阵,D-CA^(-1)B是n*n可逆矩阵,则有

当A=I(单位阵)时有:

当B=O(零矩阵)时有:

当C=O(零矩阵)时有:

当D=O(零矩阵)时有:

行列式点过程的MAP求解是一个复杂的过程,Hulu的论文中提出了一种改进的贪心算法能够快速求解,该算法的时间复杂度为O(N^2*M),N为返回的商品列表中商品的个数。
Fast Greedy MAP Inference每次从候选集中贪心地选择一个能使边际收益最大的商品加入到最终的结果子集中,直到满足停止条件为止。在每次迭代中,item

被添加至目标集Y_g中。L半正定,则其主子式也半正定。假定det(L_(Y_g))>0,则L_(Y_g)的Cholesky分解为:L_(Y_g)=VV*,其中V为可逆下三角矩阵。对任意i属于Z\Y_g,L_((Y_g)U{i})的Cholesky分解为:

其中c_i为行向量,标量d_i>=0满足:

由等式(2)有:

因此,等式(1)等价于:

j选定后,

对于item i属于Z\(Y_gU{j}) ,定义c'_i,d'_i为item i对应向量及标量,重复上述过程有:

算法伪代码如下:

LamingChen, Guoxin Zhang, Hanning Zhou, fast-greedy-map-inference-for-determinantal-point-process-to-improve-recommendation-diversity, 2018
MarkWilhelm, AjithRamanathan, AlexanderBonomo, SagarJain, EdH.Chi, JenniferGillenwater, Practical Diversified Recommendations on YouTube with Determinantal Point Processes, 2018
https://zh.wikipedia.org/wiki/最大后验概率
https://zh.wikipedia.org/wiki/Cholesky分解
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






