xgboost原理的细节(xgboost学习笔记)

一、背景
xgboost作为我们团队早期的主力模型,曾经服务于各个场景的排序模块,通过构建样本和特征,线上对用户的喜好程度进行预测,取得了一定的效果,随着我们团队逐步将模型迁移到深度学习,后续xgboost的重要性会逐渐降级,但是算法本身优雅的数学模型、特征重要性的可解释性,计算性能的高效性,各个比赛广泛应用的活跃性,有必要对xgboost的原理进行一次详细的记录,也作为我们团队的技术沉淀方便同学们持续学习。
二、原理推导
2.1 目标函数
与传统的机器学习类似,xgb算法也是需要有一个目标函数,用来评估预测结果和真实结果之间的差距,通过不断迭代更新模型参数最小化目标函数。
XGBoost的目标函数由训练损失和正则化项两部分组成,其中训练损失表示预测结果和真实结果的差距,正则化项表示模型的复杂度防止模型过拟合,目标函数定义如下:
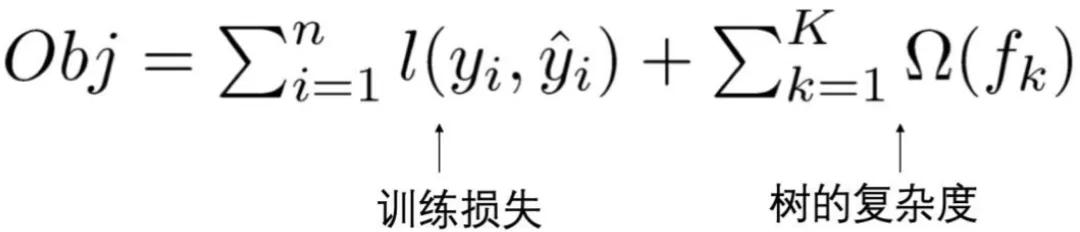
公式(1)
其中~yi 为预测输出,xgboost模型由多棵子树共同构成,每棵子树会对样本做出一个预测得分,样本最终输出的预测得分为该样本在所有子树预测得分总和,因此可以表示为:

公式(2)
其中fk为第k棵子树的模型
2.2 学习 t 时刻的子树
前面也提到了xgboost模型由多棵子树构成,模型迭代的时候会添加一棵子树去拟合上次预测的残差,换句话说:t 时刻的最终预测结果由 t-1 时刻的结果加上 t 时刻子树的结果构成:

因此我们可以将公式(3)带入到公式(1)中:

公式(3)
这里我们将正则化项进行了拆分,由于前 t-1棵树的结构已经确定,因此,前 t-1 棵树的复杂度之和可以用一个常量表示:

常量对于本次优化来说可以忽略(反正求了梯度之后也是0)
最终我们的目标函数改写为:

2.3 泰勒公式展开
回顾一下泰勒公式的二阶展开:

这里损失函数 l 可以看成上式的f(x),t-1时刻的预测值看成是上式的 x,t时刻子树的预测值看成是delta-x, 这样整个目标函数就可以拆解为:

其中一阶导数和二阶导数为了书写上简洁用g和h替换:

至此我们可以把目标函数在泰勒展开上进行改写:

常数项constant表示(t-1)时刻的子树复杂度,t-1时刻预测结果和真实结果也是常数项(因为我们现在考察的是t时刻,变量只有t时刻的子树)
最后我们的目标函数如下:

2.4 树的复杂度
我们定义一颗树的复杂度 Ω,它由两部分组成:
叶子结点的数量T;
叶子结点权重向量的L2范数;

这里引入了一个新的符号w,即叶子节点的权重
我们重新回过头来看看 t 时刻子树的定义f(x),包括两个部分:
叶子结点的权重向量 ω ;
样本到叶子结点的映射关系q;
- 公式表示在第q棵子树,样本落到的最终的叶子节点的权重w
- 我们把树的复杂度和f(x)公式带入到目标函数:
每个样本最终会落到一个叶子结点中,所以我们可以将所有同一个叶子结点的样本重组起来

其中 Ij 表示将属于第 j 个叶子结点的所有样本 xi , 划入到一个叶子结点样本集中

为了进一步简化公式,定义一阶导数和二阶导数的聚合:

含义如下:
- Gj :叶子结点 j 所包含样本的一阶偏导数累加之和是一个常量;
- Hj :叶子结点 j 所包含样本的二阶偏导数累加之和是一个常量;
将 Gj 和 Hj 带入目标式Obj,得到我们最终的目标函数

为了求关于变量w的目标函数最优,对w进行求导得到:

带回目标函数公式得到:

表示第 t 棵树带来的最小损失(训练损失 正则化损失)
2.5 树的分裂节点
对于 t 时刻的子树模型会不断进行叶子节点的分裂来进行建树,建树的最关键一步就是选择分裂准则来评价分裂的质量。损失函数用来评价一棵树的好坏,作为评价准则。
1、从树根节点开始:
2、对树中的每个叶子结点尝试进行分裂;
3、每次分裂后,原来的一个叶子结点继续分裂为左右两个子叶子结点,原叶子结点中的样本集将根据该结点的判断规则分散到左右两个叶子结点中;
新分裂一个结点后,我们需要检测这次分裂是否会给损失函数带来增益,增益的定义如下:

这里表示分裂前的损失减去分裂后的损失,代表了信息的增益,如果增益Gain>0,即分裂为两个叶子节点后,目标函数下降了,那么我们会考虑此次分裂的结果。
但是在一个结点分裂时,可能有很多个分裂点,每个分裂点都会产生一个增益,还需要有一套方法来寻找最佳分裂点。
2.6寻找最佳分裂点在分裂一个结点时,我们会有很多个候选分割点,寻找最佳分割点的大致步骤如下:
全局扫描法
1、遍历每个结点的每个特征;
2、对每个特征,按特征值大小将特征值排序;
3、线性扫描,找出每个特征的最佳分裂特征值;
4、在所有特征中找出最好的分裂点(分裂后增益最大的特征及特征值)
上面是一种贪心的方法,每次进行分裂尝试都要遍历一遍全部候选分割点。但当数据量过大导致内存无法一次载入或者在分布式情况下,效率就会变得很低,全局扫描法不再适用。
基于此,XGBoost提出了一系列加快寻找最佳分裂点的方案:
特征预排序 缓存:XGBoost在训练之前,预先对每个特征按照特征值大小进行排序,然后保存为block结构,后面的迭代中会重复地使用这个结构,使计算量大大减小。
分位点近似法:对每个特征按照特征值排序后,采用类似分位点选取的方式,仅仅选出常数个特征值作为该特征的候选分割点,在寻找该特征的最佳分割点时,从候选分割点中选出最优的一个。
并行查找:由于各个特性已预先存储为block结构,XGBoost支持利用多个线程并行地计算每个特征的最佳分割点,这不仅大大提升了结点的分裂速度,也极利于大规模训练集的适应性扩展。
2.7 停止生长
一棵树不会一直生长下去,下面是一些常见的限制条件。
1、当新引入的一次分裂所带来的增益Gain<0时,放弃当前的分裂。这是训练损失和模型结构复杂度的博弈过程。
2、当树达到最大深度时,停止建树,因为树的深度太深容易出现过拟合,这里需要设置一个超参数max_depth。
3、当引入一次分裂后,重新计算新生成的左、右两个叶子结点的样本权重和。如果任一个叶子结点的样本权重低于某一个阈值,也会放弃此次分裂。这涉及到一个超参数:最小样本权重和,是指如果一个叶子节点包含的样本数量太少也会放弃分裂,防止树分的太细,这也是过拟合的一种措施。
三、参数优化

XGBoost的参数一共分为三类:
1、通用参数:宏观函数控制。
2、Booster参数:控制每一步的booster(tree/regression)。
booster参数一般可以调控模型的效果和计算代价。我们所说的调参,很大程度上都是在调整booster参数。
3、学习目标参数:控制训练目标的表现。我们对于问题的划分主要体现在学习目标参数上。比如我们要做分类还是回归,做二分类还是多分类,这都是目标参数所提供的。
通用参数1、booster:我们有两种参数选择,gbtree和gblinear。gbtree是采用树的结构来运行数据,而gblinear是基于线性模型。
2、silent:静默模式,为1时模型运行不输出。
3、nthread: 使用线程数,一般我们设置成-1,使用所有线程。如果有需要,我们设置成多少就是用多少线程。
Booster参数1、n_estimator:也作num_boosting_rounds这是生成的最大树的数目,也是最大的迭代次数。2、learning_rate: 有时也叫作eta,系统默认值为0.3。
每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。我们一般使用比默认值小一点,0.1左右就很好。
3、gamma:系统默认为0,我们也常用0。
在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。gamma指定了节点分裂所需的最小损失函数下降值。这个参数的值越大,算法越保守。因为gamma值越大的时候,损失函数下降更多才可以分裂节点。所以树生成的时候更不容易分裂节点。范围: [0,∞]
4、subsample:系统默认为1。
这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。典型值:0.5-1,0.5代表平均采样,防止过拟合. 范围: (0,1],注意不可取0
5、colsample_bytree:系统默认值为1。我们一般设置成0.8左右。
用来控制每棵随机采样的列数的占比(每一列是一个特征)。典型值:0.5-1范围: (0,1]
6、colsample_bylevel:默认为1,我们也设置为1.
这个就相比于前一个更加细致了,它指的是每棵树每次节点分裂的时候列采样的比例
7、max_depth:系统默认值为6
我们常用3-10之间的数字。这个值为树的最大深度。这个值是用来控制过拟合的。max_depth越大,模型学习的更加具体。设置为0代表没有限制,范围: [0,∞]
8、max_delta_step:默认0,我们常用0.
这个参数限制了每棵树权重改变的最大步长,如果这个参数的值为0,则意味着没有约束。如果他被赋予了某一个正值,则是这个算法更加保守。通常,这个参数我们不需要设置,但是当个类别的样本极不平衡的时候,这个参数对逻辑回归优化器是很有帮助的。
9、lambda:也称reg_lambda,默认值为0。
权重的L2正则化项。(和Ridge regression类似)。这个参数是用来控制XGBoost的正则化部分的。这个参数在减少过拟合上很有帮助。
10、alpha:也称reg_alpha默认为0,
权重的L1正则化项。(和Lasso regression类似)。可以应用在很高维度的情况下,使得算法的速度更快。
11、scale_pos_weight:默认为1
在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。通常可以将其设置为负样本的数目与正样本数目的比值。
学习目标参数objective [缺省值=reg:linear]- reg:linear– 线性回归
- reg:logistic – 逻辑回归
- binary:logistic – 二分类逻辑回归,输出为概率
- binary:logitraw – 二分类逻辑回归,输出的结果为wTx
- count:poisson – 计数问题的poisson回归,输出结果为poisson分布。在poisson回归中,max_delta_step的缺省值为0.7 (used to safeguard optimization)
- multi:softmax – 设置 XGBoost 使用softmax目标函数做多分类,需要设置参数num_class(类别个数)
- multi:softprob – 如同softmax,但是输出结果为ndata*nclass的向量,其中的值是每个数据分为每个类的概率。
- rmse: 均方根误差
- mae: 平均绝对值误差
- logloss: negative log-likelihood
- error: 二分类错误率。其值通过错误分类数目与全部分类数目比值得到。对于预测,预测值大于0.5被认为是正类,其它归为负类。error@t: 不同的划分阈值可以通过 ‘t’进行设置
- merror: 多分类错误率,计算公式为(wrong cases)/(all cases)
- mlogloss: 多分类log损失
- auc: 曲线下的面积
- ndcg: Normalized Discounted Cumulative Gain
- map: 平均正确率
四、总结回顾
早就想写XGB的总结文档了,一来拖延癌晚期,二来想写个高大上公式又漂亮阐述又清楚的文章,导致拖延癌更加恶化。最近想通了,一个完美但是没有落地的文档,比不上一个东拼西凑排版糟糕但至少落地的文档。因此花了些功夫完成此文,后续我们的基础沉淀希望能持续进展,共勉。
1、xgboost常见面试题目
wuli小萌哥,公众号:小小挖掘机珍藏版 | 20道XGBoost面试题
2、xgboost官方文档
https://xgboost.apachecn.org/#/

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






