julia职业装备(为什么我不再推荐你用Julia)
选自yuri.is
作者:Yuri Vishnevsky
机器之心编译
编辑:蛋酱、小舟
从诞生之日起,Julia 已经走过了十多个年头。
作为一个面向科学计算的高性能动态高级程序设计语言,Julia 在许多情况下拥有能与编译型语言相媲美的性能,且足够灵活。
曾有开发者盛言赞美 Julia,从速度、通用性、多重派发等多个维度出发,认为 Julia 甚至比 Python 更胜一筹。
当然,也有人发现了 Julia 尚存在一些不足之处,开发者 Yuri Vishnevsky 就写了一篇博客控诉 Julia,并表示自己在使用多年后,已经正式停用了 Julia。
以下是博客内容:
多年来,我一直使用 Julia 语言来转换、清理、分析和可视化数据、进行统计和执行模拟。
我还发布了一些开源包,例如最近邻搜索等。但不久前我停止使用 Julia 了,我也不再推荐使用它,现在我来阐述一下原因。
根据我的经验,在我使用过的所有编程系统中,Julia 及其包的错误率最高,我来举例说明一下:
- 对概率密度进行采样会出现错误;
- 对数组进行采样会产生有偏差的结果;
- 乘积函数可能对 8 位、16 位和 32 位整数产生不正确的结果;
- 将直方图拟合到 Float64 数组会出现错误;
- 基本函数 sum!、prod!、any! 和 all!可能会返回不正确的结果。
还有一些开发者也提出了类似的问题:
- OrderedDict 可能会损坏密钥;
- dayofquarter () 函数在闰年的情况下会出现错误;
- 使用带有 error bar 的数字类型时,模拟结果不正确;
- stdout=IOStream 的 pipeline 乱序写入;
- 由于某些 copyto! 方法不检查别名而产生错误的结果;
- if-else 控制流程存在 bug。
我经常会遇到这样严重的错误,足以让我质疑 Julia 中复杂计算的正确性,在尝试新的包或者函数的组合时尤其如此。
例如,我发现 Distance 包中的 Euclidean distance 不适用于 Unitful vector;还有人发现 Julia 运行外部命令的函数不适用于 substring,Julia 对缺失值的支持在某些情况下会破坏矩阵乘法,标准库的 @distributed 宏不适用于 OffsetArrays......
尤其是 OffsetArrays 被证明是 correctness bug 的重要来源。这个包提供了一种数组类型,它利用 Julia 灵活的自定义索引功能来创建数组,而不必从 0 或 1 开始。
这可能会导致内存访问越界,如果你很幸运,将导致 segfault;如果不幸运,则会导致错误的结果。我曾经在 Julia 核心代码中发现一个 bug—— 即使用户和库作者都编写了正确的代码,它也可能导致内存访问越界。
我向 JuliaStats 组织提交了一些与索引相关的问题,该组织负责管理诸如 Distributions 之类的统计数据包和 StatsBase。我列出的问题包括:
- 存在 offset axes 的情况下,大多数采样方法都是不安全且不正确的;
- 拟合 DiscreteUniform 分布会返回不正确的答案;
- counteq、countne、sql2dist、L2dist、L1dist、L1infdist、gkldiv、meanad、maxad、msd、rmsd 和 psnr 可能会返回带有 offset 索引的错误结果;
- @inbounds 的不正确使用会导致统计数据计算错误;
- Colwise 和 pairwise 会返回不正确的 distance;
- offset 数组的权重向量访问内存越界。
这些问题背后的根本原因不单单是索引,还有当与 Julia 中的 @inbounds 一起使用时,就允许 Julia 从数组访问中删除边界检查。
function sum(A::AbstractArray) r = zero(eltype(A)) for i in 1:length(A) @inbounds r = A[i] # ← end return r end上面的代码让 i 从 1 迭代到数组的长度。如果将一个具有异常索引范围的数组传给它,就会导致内存访问越界,并且错误地使用 @inbounds 导致程序中删除了边界检查。
然而,这段代码正是多年来如何使用 @inbounds 的官方示例。
该问题现已修复,但令人担忧的是,@inbounds 很容易被滥用,导致数据损坏和不正确的数学结果。根据我的经验,这些问题包括但不限于 Julia 生态系统中的数学部分。
我在尝试完成 JSON 编码 、发出 HTTP 请求、将 Arrow 文件与 DataFrames 一起使用,以及使用 Pluto 编辑 Julia 代码等日常任务时,发现一些库中也存在 bug。
当我开始好奇我的经历是否具有代表性时,一些 Julia 用户私下分享了类似的故事。
例如,Patrick Kidger 描述了他使用 Julia 进行机器学习研究的尝试:
在 Julia Discourse 上看到帖子说「XYZ 库不 work」是很常见的,随后其中一位库维护者的回复说「这是 XYZ 依赖的 ABC 库的新版本 a.b.c 中的上游错误。我们会尽快修复。」
Patrick 还谈到:
我记得我的一个 Julia 模型训练失败的时候,我非常不开心。我断断续续地花了几个月的时间试图让它 work,尝试了能想到的每一个 trick。
最终我发现了错误:Julia/Flux/Zygote 返回了不正确的梯度。在花了这么多精力之后,我放弃了。经过两个小时的开发工作,我成功地在 PyTorch 中训练了模型。
在讨论中,其他人表示也有类似的经历:
@Samuel_Ainsworth:像 @patrick-kidger 一样,我被 Zygote/ReverseDiff.jl 中的梯度错误 bug 所困扰。我花费了数周的时间,彻底动摇了我对整个 Julia AD 领域的信心。在使用 PyTorch/TF/JAX 的时候,我从未遇到过这样的梯度 bug。
@JordiBolibar:从我开始使用 Julia 进行研究以来,我在 Zygote 中遇到了两个 bug,这使我的工作减慢了几个月。积极的一面是,这迫使我深入研究代码,并了解到很多关于我正在使用的库的信息。但是我发现自己需要花费大量时间调试代码,而不是进行本职研究。
可见,Julia 的问题是如此普遍。Julia 没有正式的接口概念,泛型函数倾向于在边缘情况下不指定其语义,并且许多常见隐式接口的性质尚未明确(例如,Julia 社区对数字是什么没有达成一致意见) 。
Julia 社区有非常多有能力、有才华的人,他们用自己的时间、工作和专业知识为 Julia 的改进做出了贡献。但一些系统性问题很少能自下而上解决,我的感觉是开发团队 leader 不承认存在严重的正确性问题。他们接受个别孤立问题的存在,但不接受这些问题背后的根本模式存在错误。
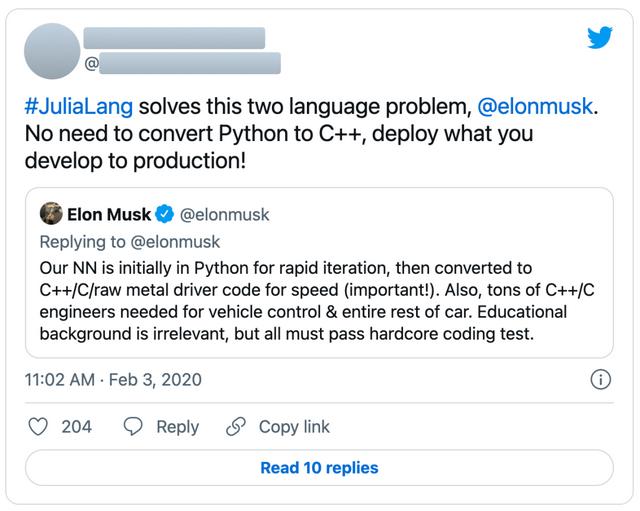
例如,在 Julia 机器学习生态系统还不够成熟的时候,该语言的一位联合创始人就兴奋地谈到在自动驾驶汽车生产中使用 Julia:
另一位联合创始人曾表示 Julia 有一个很大的优势是利于代码复用:
我认为最重要的不是 Julia 是一门多棒的语言,而是它的设计让实现代码复用的能力提升了一大截。在 Julia 中,使用者可以有效地联合使用由一个人编写的通用算法和由其他人编写的自定义类型。语言设计者不应该仿照 Julia 的所有功能,但他们至少应该理解为什么它会如此有效,并且能够在未来的设计中实现类似级别的代码复用。
从社区的角度看,每当出现一篇批评 Julia 的帖子时,社区内都会有开发者为其辩驳
例如:
2016 年时存在这个问题,但现在已经得到了很好的解决。
在 Julia 中,没有对一致性的强制执行,但泛型函数是很有效的。
Julia 当然有 bug,但没有一个是严重的。
这些说法在小范围内似乎是合理的,但如果一直如此会造成使用者的合法体验被削弱或淡化,更深层次的根本问题没有得到承认和解决。
凭借过去十年在编程语言和开源社区方面的经验,我认为至少在基本正确性方面,Julia 目前并不可靠,也许正在变可靠的路上。Julia 及其开发者必须重新审视和修改它的可靠性。
参考链接:
https://yuri.is/not-julia/
https://news.ycombinator.com/item?id=31396861
,

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






