人工智能语音识别图解(语音识别基础二)
语音识别的全称是自动语音识别(Automatic Speech Recognition,ASR),说得多了, 就把“自动”省去了,认为“自动”是理所当然的了。语音识别属于序列转换技术,它将语音序列转换为文本序列。大体来说,这是一次搬运,是把一段话的表现形式从语音变成了文本,至于文本想要表达的深层含义(自然语言理解)、倾诉的感情(情感识别)、说话人的身份(说话人识别),就需要其他的技术来处理,所以语音应用开始时是分工明确的,但这显然不符合人类对语音的感知和理解,所以后来的技术也有了不同程度的整合和联合学习。
如何实现有效的语音识别,无非是,先确定问题,然后找个模型,最后训好它。
2.1总体思路
已知一段语音信号,处理成声学特征向量(Acoustic Feature Vector,而不是 Eigenvector)后表示为X= [x1,x2,x3, ...],其中xi表示一帧(Frame)特征向量;可能的文本序列表示为W= [w1,w2,w3, ...],其中wi表示一个词,求W∗=argmaxwP(W|X),这便是语音识别的基本出发点。由贝叶斯公式可知

其中,P(X|W)称之为声学模型(Acoustic Model,AM),P(W)称之为语言模型(LanguageModel,LM),二者对语音语言现象刻画得越深刻,识别结果越准确。化整为零,逐个击破,很符合逻辑惯性,所以大多数研究都把语音识别分作声学模型和语言模型两部分,即分别求取P(X|W )和P(W),并把很多精力放在声学模型的改进上。后来,基于深度学习和大数据的端对端(End-to-End)方法发展起来,它直接计算 P(W|X ),把声学模型和语言模型融为了一体。
对于不同的候选文本来说,待解码语音的概率保持不变,是各文本之间的不变量,所以公式 2.1 中的 P(X) 可以省去不算。
一段语音,经历什么才能变成它所对应的文本呢?语音作为输入,文本作为输出,第一反应是该有一个函数,自变量一代入,结果就出来了。可是,由于各种因素(如环境、说话人等)的影响,同一段文本,读一千遍就有一千个模样,语音的数字化存储也因之而不同,长短不一,幅度不一,就是一大堆数字的组合爆炸,想要找到一个万全的规则将这些语音唯一地对应到同一段文本,这是演算逻辑所为难的;而且常用的词汇量也很庞大,能够拼成的语句不计其数,面对一段语音,遍历搜寻所有可能的文本序列必然无法负担。这样,定义域和值域都是汪洋大海,难以通过一个函数一步到位地映射起来。
如果我们能够找到语音和文本的基本组成单位,并且这些单位是精确的、规整的、可控的,那么二者之间的映射关系会单纯一些。语音,选择的基本单位是帧(Frame),一帧的形式就是一个向量,整条语音可以整理为以帧为单位的向量组,每帧维度固定不变。一帧数据是由一小段语音经由 ASR 前端的声学特征提取模块产生,涉及的主要技术包括离散傅里叶变换和梅尔滤波器组(Mel Filter Bank)等。一帧的跨度是可调的,以适应不同的文本单位。对于文本,字(或字母、音素)组成词,词组成句子,字词是首先想到的组成单位。
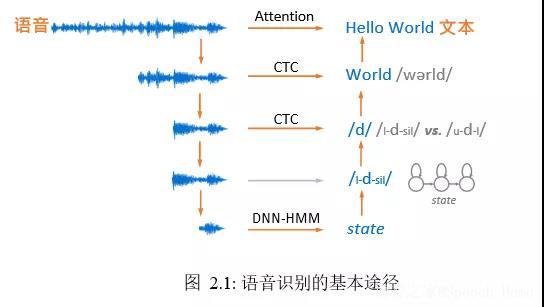
至此,语音的基本组成单位有了统一的格式,文本的基本组成单位又是有限集合,问题便在于如何将二者对应起来,图 2.1 归纳了当下常用的路数,不同方法的差别可以简单归结为文本基本组成单位的选择上,语音的建模粒度也随之而改变,图 2.1 中文本基本组成单位从大到小分别是:
•整句文本,如“Hello World”,对应的语音建模尺度为整条语音。
• 词,如孤立词“Good”、“World”,对应的语音建模尺度大约为每个词的发音范围。
•音素,如将“World”进一步表示成“/wərld/”,其中的每个音标(类比于音素,语音识别系统中使用的音素与音标有所区别)作为基本单位,对应的语音建模尺度则缩减为每个音素的发音范围。
•三音素,即考虑上下文的音素,如将音素“/d/” 进一步表示为“{/l-d-sil/, /u-d-l/,...}”,对应的语音建模尺度是每个三音素的发音范围,长度与单音素差不多。
•隐马尔可夫模型状态,即将每个三音素都用一个三状态隐马尔可夫模型表示,并用每个状态作为建模粒度,对应的语音建模尺度将进一步缩短。
图 2.1 中从“语音”到“文本”的任一路径都代表语音识别的一种实现方法,每种实现方法都对应着不同的建模粒度,这里先做个概览,其中“DNN-HMM”表示深度神经网络-隐马尔可夫模型结构,“CTC”表示基于CTC损失函数的端对端结构,“Attention”表示基于注意力机制的端对端结构,下文将对这几个方法及相关概念进行讲解。
2.2声学模型 GMM-HMM
2.2.1HMM
声学模型解决的问题是如何计算 P(X|W ),它是语音识别的“咽喉”之地,学好了发音,后面的事才能顺理成章。首先要考虑的是,语音和文本的不定长关系使得二者的序列之间无法一一对应,常规的概率公式演算就不适宜了。隐马尔可夫模型(Hidden Markov Model,HMM) 正好可以解决这个问题。比如P(X|W) =P(x1,x2,x3|w1,w2)可以表示成如图 2.2 隐马尔可夫链的形式,图中w是 HMM 的隐含状态,x是 HMM 的观测值,隐含状态数与观测值数目不受彼此约束,这便解决了输入输出的不定长问题,并有
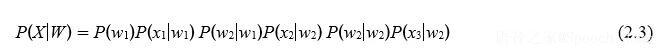
其中,HMM 的初始状态概率(P(w1))和状态转移概率(P(w2|w1)、P(w2|w2))可以用常规的统计方法从样本中计算出来,主要的难点在于 HMM 发射概率(P(x1|w1)、P(x2|w2)、P(x3|w2))的计算,所以声学模型问题进一步细化到HMM 发射概率(Emission Probability)的学习上。

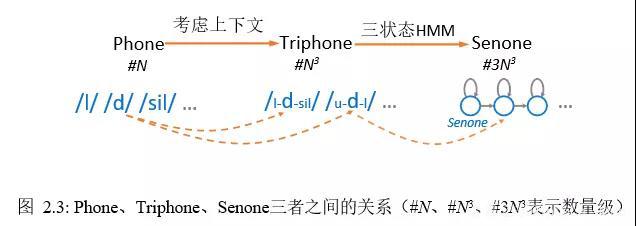
另一个问题是,基本单位的粒度大小。对于语音,帧的粒度可通过调节处理窗口的宽窄来控制。对于文本,字词级别的粒度过于宽泛笼统,于是我们往下分解,如图 2.1 所示:字词是由音素(Phone)组成的;音素的上下文不同,同一个音素就有了不同的变异体,比如 /l-d-sil/ 与 /u-d-l/ 是一对亲兄弟却是两家子,记为三音素(Triphone);每个三音素又可以用一个独立的三状态 HMM 建模,这样,文本方面的基本单位降解为微小的 HMM 状态(与图 2.2 中的 HMM 不同,其每个状态对应一个词)。由于很多三音素并未在语料中出现或数量不多,并且可以通过决策树(Decision Tree) 共享三音素的状态,所以对于共有 N 个音素的语言,最终保留下来的三音素状态数量远小于3N3,一般为几千,并把他们叫做 Senones, 而每一帧与每一个Senone的对应关系表示为三音素 HMM 的发射概率P(xi|sj),其中sj表示第j个 Senone,与之对应的帧(xi)的跨度通常取为 25ms,帧间步移常取为10ms,由于跨度大于步移,相邻帧的信息是冗余的,这是跳帧训练和解码的一个出发点。图 2.3 进一步展示了Phone、Triphone、Senone三者之间的关系,其中Senone是借助数学模型定义出来的音素变种,没有直接的听觉感受,音素“/sil/”无实际发音,仅表示静音、字间停顿或无意义的声音,#N 是Phone 的个数,#N3、#3N3分别是 Triphone、Senone 的可能数量级(真实有效数量远少于数量级)。
文本 Sentence 到 Word,Word 到 Phone,Phone 到 Triphone,每个 Triphone 都用一个HMM建模,将所有相关的HMM按发音顺序首尾相连组成的HMM 长链则表示Sentence,所以 P(X|W) 就是这条HMM长链产生观测序列 X 的概率。因为 Phone 个数是固定的,系统中所有的 Triphone HMM 所构成的基本集合也是固定的,不同 W 对应的长链不同则在于长链所包含的 Triphone 不同,但它们所使用的“字典”是相同的。用 p 表示 Phone、c 表示Triphone,可知一个 p 可以对应多个 c, P(X|W) 有类似如下的转换关系:

从公式 2.5 转到 2.6中,p1的上下文音素分别是“/sil/”和p2,p2的上下文音素分别是p1和p3,以此类推。虽然声学模型的建模粒度细化了,但问题仍是给定 HMM,求产生某个观测序列的概率,只是 HMM 更长一些而已,归根结底仍需要对发射概率P(xi|sj)建模( HMM 的转移概率也需要学习,但相对于发射概率影响小得多,甚至可以使用预设值)。
逐层分解一件事物直至根本,把握住每个关键节点之后,拼装回去,整体又回来了,但理解得更透彻了。上述语音识别系统声学模型的设计正是一个从大到小、从宏观到微观的拆解过程,而语音识别系统的解码是要回去的:从 Frame 到 Senone,从 Senone 到Triphone ,再到Phone ,最后到Word 直至Sentence。
HMM 涉及的主要内容有,两组序列(隐含状态和观测值),三种概率(初始状态概率,状态转移概率,发射概率),和三个基本问题(产生观测序列的概率计算,最佳隐含状态序列的解码,模型本身的训练),以及这三个问题的常用算法(前向或后向算法,Viterbi 算法,EM 算法)。语音识别的最终应用对应的是解码问题,而对语音识别系统的评估、使用也叫做解码(Decoding)。
2.2.2GMM
HMM 确定了语音识别的整体框架,其中发射概率P(xi|sj)的建模直接影响声学模型的好坏,也是研究者探索最多的地方。
高斯混合模型(Gaussion Mixture Model,GMM)是最常用的统计模型,给定充分的子高斯数,GMM 可以拟合任意的概率分布,所以 GMM 成为首选的发射概率模型。每个GMM 对应一个 Senone ,并用各自的概率密度函数(Probability Density Function,PDF) 表示,图 2.4 展示了单个三音素的 GMM-HMM 结构。GMM 把每帧看成空间中一个孤立的点,点与点之间没有依赖关系,所以GMM 忽略了语音信号中的时序信息,并且帧内各维度相关性较小的MFCC(Mel Frequency Cepstral Coefficient)特征更利于GMM 建模。

GMM训练完成后,通过比对每个PDF,可以求出发射概率P(xi|sj),然后结合HMM 的初始状态概率、状态转移概率,通过公式2.7 计算得到 P(X|W ),这其中会有一系列条件限制,比如,这一串 Senones 能否组成Triphone,这一串 Triphones 能否组成Phone,这一串Phones 能否组成Word,这一串 Words 能否组成Sentence。
语音识别是对连续变量的建模,连续变量的概率比较可以等价地使用概率密度函数,文中提到的连续变量的概率并非真实的概率,是概率密度函数参与计算的结果。
2.2.3训练
给定一个训练好的 GMM-HMM 模型和语音序列X,针对不同的W备选,都可以计算出P(X |W ),剩下的问题则是如何训练GMM-HMM。
HMM 和GMM 的训练都使用自我迭代式的 EM 算法(Expectation–Maximization Algorithm)。EM 算法可以有效地解决存在隐变量(Latent Variable)的建模问题,而 HMM 和 GMM 的训练中都有各自的隐变量:
• HMM 的训练中,给定初始 HMM 模型和观测序列,无法确定的是,不同时刻的观测值该由哪个隐含状态发射出来,所以 HMM 的隐变量所表达的意思是,给定整个观测序列,某时刻的观测值由某一个隐含状态“发射”出来的概率,也叫“State Occupation Probability” (真正的隐变量描述的是一种情形,即某时刻的观测值由某一个隐含状态“发射”出来,这里统一用它的概率表示,下同)。
• GMM 的概率密度函数是多个子高斯概率密度函数的线性组合, 所以 GMM 的隐变量所表达的意思是,某个样本由某一个子高斯所描述的比重,也叫“Component Occupation Probability”,可见一个样本由 GMM 中所有的高斯分别进行建模,但汇总时的权重不同,且所有权重之和为 1。
• GMM-HMM 的隐变量则是GMM 和HMM 的结合,其隐变量所表达的意思是,给定整个观测序列,某时刻的观测值由某一个隐含状态(对应一个 GMM)中的某一个子高斯所描述的概率。
对于GMM-HMM 结构,已定义隐变量,则可以按照EM 的标准流程进行迭代训练。GMM-HMM 训练中会进行状态共享,最后所有的PDF 数(即GMM 数)与Senone 数是相同的,因为 Senone 本质上是 HMM 的状态,而一个状态都用一个 PDF 对其进行发射概率的建模。
2.3声学模型 DNN-HMM
GMM 是生成式模型(Generative Model),着重刻画数据的内在分布,可直接求解P(xi|sj),而P(xi|sj) =P(si|xj)P(xj)/P(sj),因P(xj)省去不算,P(sj)可通过常规统计方法 求出,问题进一步归结为求取P(si|xj),这是典型的分类(Classification)问题,也是判别式模型(Discriminative Model) 所擅长的,其中深度神经网络(Deep Neural Network, DNN) 的表现尤为突出。上述各项也有各自的叫法,P(xj|si)是似然(Likelihood),P(si)是先验概率(Prior Probability),P(si|xj)是后验概率(Posterior Probability)。
DNN 用于分类问题,是有监督学习(Supervised Learning),标签(Label)的准备是必不可少的。由于训练集中只提供了整条语音与整条文本之间的对应关系,并未明确指出帧级别的标签,所以还需要额外的算法对数据集进行打标签,选择的方法是上文的GMM。作为生成式模型的 GMM 擅长捕捉已知数据中的内在关系,能够很好地刻画数据的分布,打出的标签具有较高的可信度,但对于未知数据的分类,判别式模型的 DNN 有着更强的泛化能力,所以可以青出于蓝。图 2.5 展示了基本的 DNN-HMM 声学模型结构,语音特征作为 DNN 的输入,DNN 的输出则用于计算HMM 的发射概率。
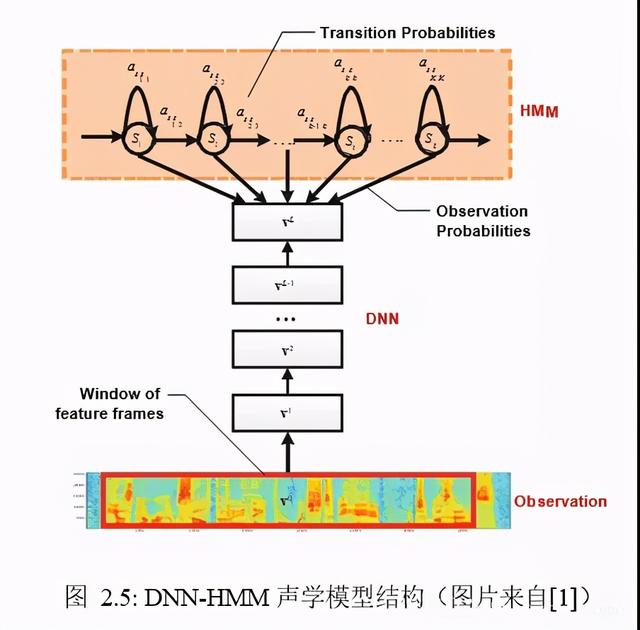
相较于GMM-HMM 结构,DNN-HMM 与之唯一的不同是结构中的发射概率是由 DNN 而非 GMM 求出的,即二者的区别在于 GMM 与 DNN 之间的相互替代。值得注意的是,使用 DNN 来计算发射概率时需要引入先验概率P(si)。此外,GMM 和DNN 中的前向神经网络(Feedforward Neural Network),是独立对待各帧的,即上一帧计算的结果不会影响下一帧的计算,忽略了帧与帧之间的时序信息。DNN 起用循环神经网络(Recurrent Neural Network,RNN)时,便可以考虑时序信息了。
贝叶斯定理(Bayes’ theorem)已被用到两次,宏观的一次是分出了声学模型和语言模型,微观的一次是构造了 HMM 发射概率的判别式求法。
2.4语言模型
语言模型要解决的问题是如何计算P(X |W ),常用的方法基于 n 元语法(n-gram Grammar)或RNN。
2.4.1n-gram
语言模型是典型的的自回归模型(Autoregressive Model),给定词序列W=[w1,w2,...,wm],其概率表示为

其中从公式 2.9 到 2.10则是做出了“远亲不如近邻” 的假设,即所谓的 n-gram 模型[2, 3] ,它假设当前词的出现概率只与该词之前n-1个词相关,该式中各因子需要从一定数量的文本语料中统计计算出来,此过程即是语言模型的训练过程,且需要求出所有可能的P(wi|wi−n 1,wi−n 2, ...,wi−1),计算方法可以简化为计算语料中相应词串出现的比例关系,即

其中count表示词串在语料中出现的次数,由于训练语料不足或词串不常见等因素导致有些词串未在训练文本中出现,此时可以使用不同的平滑(Smoothing)算法 [4, 5, 6]进行处理。
2.4.2RNN语言模型
从公式 2.9 的各个子项可以看出,当前的结果依赖于之前的信息,因此可以天然地使用单向循环神经网络进行建模。单向循环神经网络训练的常规做法是,利用句子中的历史词汇来预测当前词,图 2.6 展示了 RNN 语言模型的基本结构,其输出层往往较宽,每个输出节点对应一个词,整个输出层涵盖了语言模型所使用的词表,故其训练本质上也是分类器训练,每个节点的输出表示产生该节点词的概率,即P(wi|w1,w2, ...,wi−1),故据公式2.9 可以求出P(W)。前向非循环神经网络也可以用于语言模型,此时其历史信息是固定长度的,同于n-gram。
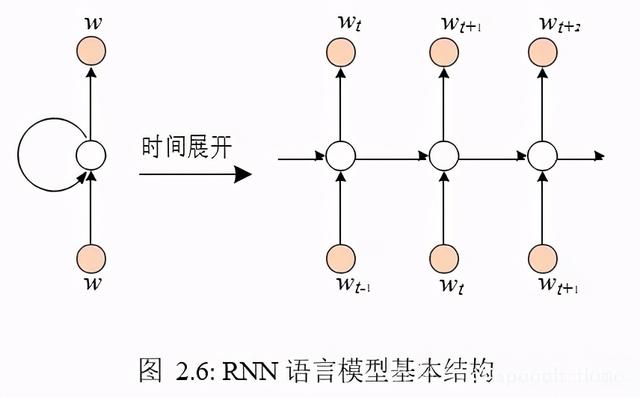
RNN LM 与n-gram LM 二者相比,基本的优劣势包括:RNN LM 可以使用相同的网络结构和参数处理任意长度的历史信息,而 n-gram LM 随着n 的增加,模型大小将呈指数递增;由于 n-gram LM 直接存储的就是各种词汇组合的可能性,可以对其进行直接编辑, 比如两个领域的 n-gram LM 融合、新词添加等,而 RNN LM 则无法修改参数,很难进行新词拓展;RNN LM 的使用中需要临时计算P(wi|w1,w2,…… ,wi−1),实时性不高,而n-gram LM 中直接存储的就是P(wi|wi−n 1,wi−n 2,…… ,wi−1),相同性能下,n-gram LM 的模型存储大小一般大于RNN-LM,但n-gram LM 支持静态解码(即解码图是实现准备好的),进一步节省解码时间;RNN-LM 可以充分利用深度神经网络的表征学习能力,更有潜力,而n-gram 只是简单地“数数”(或许这样也能体现算法的简洁性)。
RNN LM 与 n-gram LM 可以结合使用,而且可以将 RNN LM 预存为 n-gram 的形式,即用 RNN 直接求出P(wi|wi−n 1,wi−n 2, ,wi−1)(此时 RNN-LM 的历史信息长度受到限制),并将其保存,然后利用此 n-gram LM 对原有的n-gram LM 进行调整。
自然语言处理领域常用到的神经网络语言模型预训练技术,比如BERT[7]、RoBERTa[8]、XLNet[9]、ALBERT[10]等,尚未在语音识别领域得到广泛应用,一方面是由于该类语言模型针对的任务是自然语言处理领域的,规模较大,远超声学模型神经网络复杂度,影响语音识别的实时性,另一方面则是该类语言模型的训练可能并不能有效计算P(W),比如BERT 在训练时利用左右的全部上下文来预测当前词(上述单向 RNN-LM 仅使用左侧上下文),不过也有研究在探索将该类语言模型应用于语音识别,比如可以使用BERT模型对预选的多个W进行打分[11]。
2.5解码器
我们的最终目的是选择使得P(W|X) =P(X|W)P(W)最大的W,所以解码本质上是一个搜索问题,并可借助加权有限状态转换器(Weighted Finite State Transducer,WFST) 统一进行最优路径搜索[12]。WFST 由状态节点和边组成,且边上有对应的输入、输出符号及权重,形式为 x : y/w,表示该边的输入符号为x、输出符号为y、权重为w,权重可以定义为概率(越大越好)、惩罚(越小越好)等,从起始到结束状态上的所有权重通常累加起来,记为该条路径的分数,一条完整的路径必须从起始状态到结束状态。
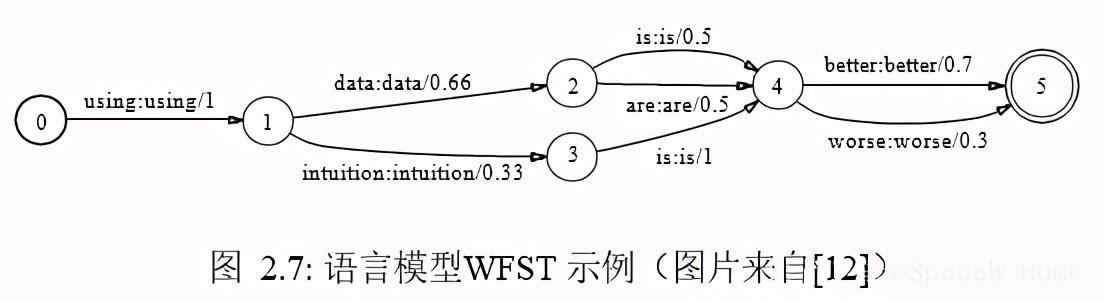
首先,句子由词组成,对于n-gram LM,可以将其表示为WFST,并记为G,图 2.7 是语言模型表示成 WFST 的示例,可以看到,G 的输入符号和输出符号是相同的,均为词, 其后的权重由语言模型中的概率值转换而来,据此图可知,句子“using data is better”的得分为1 0.66 0.5 0.7 = 2.86,句子“using intuition is worse”的得分为1 0.33 1 0.3 = 2.63,如果将权重定义为惩罚,则后一条句子的可能性更大。
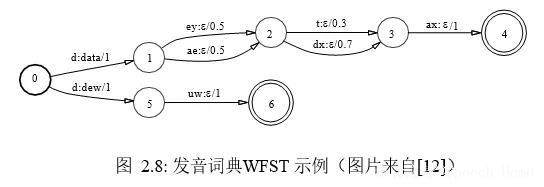
其次,词由音素组成,可以将其表示为 WFST,并记为L,图 2.8 是发音词典表示成WFST 的示例,图中的 ε 是个占位符,表示没有输入或输出。据此图可知,单词“data=/d ey t ax/”的得分为 1 0.5 0.3 1 = 2.8,而单词“dew=/d uw/”的得分为 1 1 = 2,如果将权重定义为惩罚,则“dew”的可能性更大。
以此类推,定义输入为 Triphone、输出为 Phone 的 WFST 为 C,定义输入为 Senone、输出为 Triphone 的WFST 为 H,至此,我们得到4个 WFST,即H、C、L、G,表 2.1 对这 4 个WFST 进行了比较,表中的“输入”、“输出”表示走完一条完整路径后整个 WFST 的输入、输出,而不是一条边上的输入、输出,可见前者的输出是后者的输入,所以可以将它们融合(Composition)为一个 WFST,实现了上文提到的从 Senone 到 Triphone(H)、Triphone 到Phone(C)、 Phone 到Word(L)、Word 到Sentence(G),这就是解码图(Decoding Graph)。

WFST 的融合一般从大到小,即先将G与L与融合,再依次融合C、H,每次融合都将进行确定化(Determinisation)和最小化(Minimisation)操作。WFST 的确定化是指, 确保给定某个输入符号,其输出符号是唯一的;WFST 的最小化是指,将 WFST 转换为一个状态节点和边更少的等价 WFST。H、C、L、G的融合,常用的过程为:
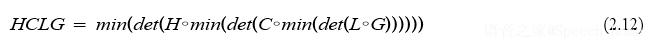
其中HCLG为最终的解码图 WFST, ◦ 表示 Composition,det表示 Determinisation,min 表示Minimisation,OpenFST等工具实现了这些操作。
最终解码时,只需要 GMM 或 DNN(因为 HMM 已在解码图之中),就可以利用 HCLG 进行解码了,给定语音特征序列X,可以通过 GMM 或 DNN 计算出P(xi|sj),即HMM 的发射概率,借助于HCLG,P(W |X ) ∝ P(X |W )P(W )的计算将变得简单,即将 W 路径上的权重(假设定义为惩罚)相加,再减去各状态针对输入的发射概率(log后的值)得到最终得分,该得分越小,说明该语音X转录为W的可能性越大。由于 HCLG 中的权重都是固定的,不同的P(xi|sj)将使得HCLG中相同的 W 路径有不同的得分。通过比较不同路径的得分,可以选择最优路径,该路径对应的 W 即为最终解码结果。由于 HCLG 搜索空间巨大,通常使用束搜索(Beam Search)方法,简单说来,路径搜索中,每走一步,搜索空间都会指数级扩大,如果保留所有的路径,计算将难以支撑,但很多路径是完全没有“希望”的,所以虽未走到终点,可以根据当前的得分仅保留指定数目的最优路径(即n-best),走到下一步时仍然如此,直到走到终点,选择一条最优路径。
2.6端对端结构
由于语音与文本的多变性,起初我们否决了从语音到文本一步到位的映射思路。经过了抽丝剥茧、以小见大,再回过头来看这个问题。假设输入是一整段语音(以帧为基本单位),输出是对应的文本(以音素或字词为基本单位),两端数据都处理成规整的数学表示形式了,只要数据是足够的,选的算法是合适的,兴许能训练出一个好的端对端模型,于是所有的压力就转移到模型上来了,怎样选择一个内在强大的模型是关键。深度学习方法是端对端学习的主要途径。
端对端学习需要考虑的首要问题也是输入输出的不定长问题。
对于输入,可以考虑将不同长度的数据转化为固定维度的向量序列。如果输入一股脑地进入模型,可以选择使用卷积神经网络(Convolutional Neural Network,CNN)进行转换, CNN 通过控制池化层(Pooling Layer)的尺度来保证不同的输入转换后的维度相同;如果输入分帧逐次进入模型,可以使用 RNN,虽然输入是分开进入的,但 RNN 可以将积累的历史信息在最后以固定维度一次性输出。这两个方法常常用于基于注意力(Attention)的网络结构 [13, 14]。
对于输出,往往要参照输入的处理。先考虑输入长度不做处理的情况,此时输出的长度需要与输入保持匹配。因为语音识别中,真实输出的长度远小于输入的长度,可以引入空白标签充数,这是CTC(Connectionist Temporal Classification)损失函数[15, 16] 常用的技巧,如果真实输出的长度大于输入的长度,常规 CTC 就不适宜了;另一个情况是,将输入表示成固定长度的一个向量,这正是前文所述的基于 CNN 或注意力机制的方法,然后再根据这个向量解码出一个文本序列(真正实现时,每次解码出一个词,其针对输入的注意力权重有所差异和偏重),此时输出的长度便没有了参照,则需要其他机制来判断是否结束输出,比如引入结束符标签,当输出该标签时便结束输出。
当仔细斟酌了输入输出的不定长问题,目前最基本的两个端对端方法也呼之欲出,即上文提到的基于 CTC 损失函数和注意力机制的深度学习方法,且二者可以合用。端对端方法将声学模型和语言模型融为一体,简单明了,实施便捷,是当下语音识别的主要方向之一。随着数据量和计算力的增加,端对端方法行之愈加有效,然而这里仍将语音识别系统拆解开来、逐一透视,因为这是真正理解语音识别的必经之路。下面简要介绍几种常用的端对端方法。
2.6.1CTC
CTC 方法早在2006年就已提出并应用于语音识别[15],但真正大放异彩却是在2012年之后[16],随之各种CTC 研究铺展开来。CTC 仅仅只是一种损失函数,简而言之,输入是一个序列,输出也是一个序列,该损失函数欲使得模型输出的序列尽可能拟合目标序列。回忆语音识别系统的基本出发点,即求W∗=argmaxwP(W|X),其中 X= [x1,x2,x3, ...]表示语音序列,W= [w1,w2,w3, ...]表示可能的文本序列,而端对端模型zh本身就是P(W|X ),则CTC 的目标就是直接优化P(W|X),使其尽可能精确。
给定训练集,以其中一个样本(X,W )为例,将X输入模型,输出可以是任意的文本序列W',每种文本序列的概率是不同的,而我们希望该模型输出W的概率尽可能大,于是CTC 的目标可以粗略地理解为通过调整 P 对应的参数来最大化P(W |X )。
下面要解决的问题是该如何表示P(W |X )。以常规的神经网络为例,语音输入序列一粒一粒地进,文本输出序列一粒一粒地出,二者的粒数是相同的,而通常情况下,处理后的语音序列与文本序列并不等长,且语音序列远长于文本序列,于是与输入等长的输出(记为S)需要进行缩短处理后再作为最后的输出(希望其拟合W),因此一个输出单元往往对应多个输入单元,又已知S可以有多种可能,CTC 的优化目标则变为最大化

其中A(W )表示所有与输入等长且能转换为W的所有S集合,因为有些S没有意义或不可能出现,而 CTC 平等地对待每种可能,这使得模型的训练有失偏颇,较大训练数据集则可以进行弥补。
接着需要考虑的问题是S与W之间的转换关系。首先S中的单元(记为s)与W中各单元(记为w)是多对一的关系,即一个w可以拥有多个s(一个有效的发音总要多些语音特征), 但一个s只能抵达一个w(具体的某个语音特征只属于某个特定发音),S转换为W只需删除重复的对应关系即可,比如S = CCChhhhiiiiinnnnaaaa,W = China(这里W是以字母为基本单元),但如果单词里本身就要重复字母,比如 happy、中文语音识别中的叠词(以汉字为基本单元),此时直接删除重复的对应关系则产生误伤,而如果在重复单元之间引入一个特殊字符ε(上文提到的空白字符),则可以阻断合并,比如S=hhhhaaaappppε pppppyyyyy,W = happy。引入 ε 字符是为了有效处理S与W的转化关系,本身并无意义,所以最后一步需要将 ε 删除。假如W = happy,以下几个例子则是有效的S,可以通过先删重复后删 ε 的规则还原回去:

而以下几个例子则是无效的:

空白标签 ε 和静音符同为网络输出单元,但二者有不同的用途。空白标签 ε 表示不输出任何东西,最终在 W 中是没有的,而静音符表示静音、字间停顿或无意义的声音,是实实在在的输出单元。虽然 ε 表示无有效输出,但其对应的输入并非没有意义,可以理解为,该输入的信息通过与近邻相互累积,在未来某个时刻表现出来。
以上的举例中,文本序列的基本单元是字母。不同于DNN-HMM复合结构,CTC 的基本单元一般为宏观层面的(如词、字母、音素等),人的可读性较强,每个单元对应的语音输入长度甚至都是人耳可辨的,比如对于英文可以选择字母或常用的单词,对于中文可以选择常用的汉字。
虽然 CTC 仅是种损失函数,但并非所有的网络结构都能与之有效配合,通过上面的例子可以看出,很多输入单元的输出标签为 ε,它们的贡献在于为后来的某一个输入单元积攒“势”力,这就需要模型结构具有“厚积薄发”的能力,而各种神经网络结构中,具有历史记忆能力的循环神经网络是最合适的。循环神经网络能够累积历史信息(双向网络可以兼顾前后信息),形成长时记忆,在CTC端对端语音识别中表现为隐性的语言模型建模(建模的单元为内部表征,而非文字),且累积效应可以与 ε 搭配使用,所以 CTC 的使用中,常规结构为 LSTM-CTC,其中长短时记忆单元 LSTM(Long Short-term Memory)为典型的循环神经网络结构。如图 2.9 所示,使用 CTC 训练的模型对各个音素的可能性预测是尖峰似的,即当每个音素的信息积累到一定程度才“蹦”出较高的概率,而使用帧级别对齐的训练方法则是尝试将每个音素对应的大部分帧都打高分,体现不出“厚积薄发”。

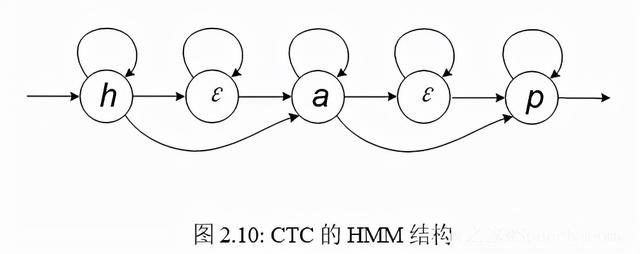
前面提到的 HMM 解决了语音识别系统输入与输出长度不一致的问题,而 CTC 通过引入 ε 也可以规避此问题,故 CTC 是一个特殊的 HMM,如图 2.10 所示,可以将 CTC 的序列转换通过一个 HMM 结构表达出来。
CTC 的端对端训练中,语言模型并不是显性学习的,其建模粒度为网络的隐层表征, 并非 CTC 的输出标签,且训练语料受限于语音对应的标注语料,因此有一定的局限性,当训练数据不够多时劣势尤为明显,所以系统在使用时可以额外搭配一个语言模型优化解码结果,但这样便违背了端对端系统的初衷,端对端系统就是为了使得模型合一、简化流程。所有的端对端ASR系统都可以像DNN-HMM结构一样,额外添加一个语言模型,而当训练数据越来越多时,外接语言模型所带来的性能提高则越来越小。
2.6.2RNN-T
CTC 训练是隐性学习语言模型的,可以通过改进结构,使得系统可以同时显性地学习语言模型,使得声学模型和语言模型能够真正地统一学习,进一步促进系统性能。早在2012 年,实现该目的的 RNN Transducer(RNN-T) 技术就已成型[16, 17],但一直未得到广泛使用,直到 2019 年,谷歌将该技术成功应用于移动端的实时离线语音识别[18]。
语音识别(语音到文本)与机器翻译(一种文本到另一种文本)都是序列学习任务,二者的学习框架是可以相互借鉴的,且都需要学习目标文本的语言模型。RNN-T 显性训练语言模型的思路与机器翻译的做法是类似的,即在预测当前目标时,将之前的结果作为条件。条件概率P(y|x)在深度学习里的表现形式比较直观,只需将x作为输入去预测y即可,常规的 CTC 是以语音x为条件,现在需要多考虑之前的输出y',学习目标更新为P(y|x,y')。图 2.11 展示了RNN-T 与CTC 的结构差异,其中预测网络(Prediction Network)与编码器(Encoder)都使用了LSTM,可以分别对历史输出(y)和历史语音特征(x,含当前时刻)进行信息累积,并通过一个全连接神经网络(Joint Network)共同作用于新的输出,图中的p和h分别为预测网络和编码器的输出,形式为固定长度的向量。
2.6.3Attention
深度学习中的注意力机制最初应用于神经机器翻译(Neural Machine Translation)[19],而语音识别也是一种特别的机器翻译(它的输入是某种机器人可以看懂的“文本”,我们用来记录语音),注意力机制显然可以迁移过来。
注意力是一个经常接触的概念,“将注意力放在学习上”、“注意安全”、“注意,我要开始了”、“注意这个地方”,总的来说,注意力是指人类将自己的意识集中到某个事物上,可以是外在存在,也可以是内在的心理活动。注意力是可以注意到的和控制的,我

们的眼神聚焦就是一种注意力机制。机器翻译里的注意力可以简单理解为目标输出的各个单元与原始输入的各个单元之间的相关性,比如“你是谁”翻译成“who are you”,显然“who”对“谁”、“are”对“是”、“you”对“你”的注意力最强。类似于我们的眼神有余光(形如高斯分布,最中央最聚焦),注意力可以是柔性的(Soft Attention),注意力程度的取值范围为 [0, 1],而非零即一的硬性机制(Hard Attention)只是柔性机制的一种特例,因此柔性机制的应用更加广泛。上面“who are you”的例子中“are”并非将所有的注意力都给了“是”,因为在序列预测中,预测“are”时并不知道“you”,所以单数或复数并不确定,这时就需要“偷瞄”一下上下文。语音识别中,每个音素都需要“看”到与其关联最大的音频区域,且这段音频的每个子单元对音素发声的贡献不尽相同,是不平等地“看”,也是注意力机制的体现。图 2.12 展示了语音及其文本(字母为基本单位)的注意力对齐结果,可以看到,每个输出单元都主要聚焦到某一小截语音,并会受到近邻的上下文语音的影响,这是符合语言的发音规则的,比如“student”中两个“t”的实际发音因前一个音标发音的不同而不同,“你好”的“你”受到“好”第三声音调的影响,在实际发音中是第二声,这种自身发音受近邻发音影响的现象也叫协同发音(Coarticulation)。
机器翻译中,由于语法结构不同,比如主谓宾的顺序,注意力可能会出现前后交叉的情况,比如“who”是目标语言的第一个词,但聚焦在了原始输入的最后一个单元“谁”上,最后的“you”又聚焦到了最前面的“你”,而语音识别中的输入语音与输出文本是顺位相关的,不会出现这种情况,如图 2.12 所示,一个音素的对应范围大约为几十毫秒,上下文顶多扩展到一个单词的发音范围,其他地方的语音对该音素的发音没有影响,所以声学模型通常采用局部注意力(Local Attention)的机制。由于不需要对所有输入“尽收眼底”之后才开始解码,局部注意力能够提高识别的实时性。与局部注意力对应的是机器翻译中的全局注意力(Global Attention),因为从人的认知角度来看,想要对一句话进行翻译,首先要在总体上理解其含义。

人类行为中的语音识别和语言翻译都是认知行为,因为最终都抵达语言理解,知晓全文有助于人类的识别和翻译,但我们对机器中的语音识别任务进行归类时,将其大体归为感知行为,即认为其统计了足够多的数据后,不需要知道意思也能进行文 本的转录,知晓文本意思(如语言模型的学习)固然可以提升性能,但并非技术的 瓶颈;而机器翻译更偏向于对人类认知行为的模仿。
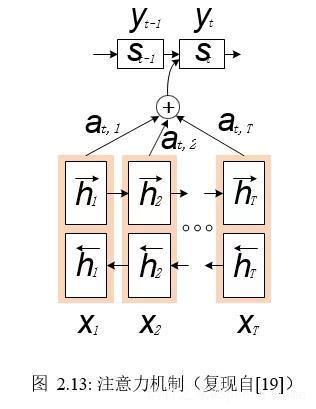
图 2.13 展示了全局注意力机制在深度学习中的实现方式,它大体上是一个编码器-解码器(Encoder-Decoder)结构。首先,其使用双向循环神经网络将所有时序信息编码成隐层信息,接着表示出每个输出单元与所有隐层信息的注意力关系(使用 Softmax 函数保证总的注意力为1),最后预测出每个输出单元。这里两个地方使用了条件学习,一是输出单元对各时刻隐层信息的注意力计算(at,1、at,2、at,3等),除了依赖于隐层信息h以外,也受以往输出内容 y(或对应的解码器隐层信息s)的影响,二是预测每个输出单元时,除了依赖注意力机制注意到的信息以外,也需要参考过往的输出y及其对应的解码器隐层信息 s。
2.6.4Self-attention
相比于上述注意力机制旨在发现输入与输出的关联程度,自注意力机制则是要发现原始输入的各个单元与自身各单元的关联程度,比如翻译“你是谁”时,“是”是“你”的谓语动词,二者之间是有关联度的。当下自注意力机制应用最广泛的结构当属Transformer [21],其优势在于摆脱了循环神经网络和卷积神经网络结构的禁锢,以及使用了多注意力机制,大大加速了并行计算。Transformer 的结构如图 2.14所示。

为了便于实现,Transformer 引入了 (Query,Keys,Values) 三元组来描述自注意力机制,简记为 (Q,K,V),以一个注意力模块为例,输入为X,而Q、K、V都是X的线性变换矩阵:

其中X=x1,x2, ...、Q=q1,q2, ...、K=k1,k2, ...、V=v1,v2, ...均为矩阵,时序长度相同,每个子单元也均为矩阵,该注意力模块的输出结果为:

其中1/√dk用于尺度缩放,dk表示K的维度。
Transformer 未使用循环神经网络结构,为了凸显输入信息的时序性,需要给输入的每个单元添加位置信息。Transformer 还使用了残差结构、层规整(Layer Normalization) 来进一步增强模型的学习能力。
2.6.5CTC Attension
CTC是一种损失函数,注意力机制是一种网络结构,二者可以“强强联合”应用于语音识别,比如CTC与注意力网络共享一个编码器,但各自有各自的解码器,如图 2.15 所示,最后将各解码器的解码结果融合在一起[22]。

2.7开源工具与硬件平台
开源社区大大加速了计算机科学的研究,深度学习领域的茁壮发展更是深受其益,语音识别领域也搭上了这场浪潮。由于深度学习已成为语音识别的关键技术,多数语音识别工具都需要借助于通用型深度学习平台,下面将先介绍通用的深度学习平台,而后介绍“术业专攻”的语音识别工具。这些软件工具最终都要依托于硬件计算平台,通用型的CPU 并不适合神经网络的快速并行计算,下文也将介绍转为神经网络设计的加速器。
2.7.1深度学习平台
随着深度学习的发展,更先进的计算平台层出不穷。通用深度学习框架提供各种深度学习技术,并可拓展应用于多种任务,比如语音识别、计算机视觉、自然语言处理等,所以语音识别系统的建立并不局限于某个平台。通用深度学习框架的内核语言多为C ,前端接口语言多支持Python,这样的搭配使得保持灵活性的同时又不失计算速度。由于神经网络的训练基于梯度下降法,所以自动梯度的功能对于深度学习平台来说是必要的。深度学习平台的开发都以 Linux 系统(可能是用的最多的开源软件)为主,表 2.2 归纳了常用深度学习框架的基本信息,仍有一些框架是对已有框架的进一步封装(如Keras)。

开源工具的更新换代也很快,比如 Theano已停止维护,有些功成身退的意味,而面对执着于Lua 语言的Torch,更多人选择或转移到了 PyTorch。
面对林林总总的深度学习框架,Microsoft 与 Facebook 发起推出 ONNX 深度学习模型格式,让用户可以在不同框架之间转换模型。
2.7.2语音识别工具
语音识别系统有着长久的积淀,并形成了完整的流程(从前端语音信号处理,到声学模型和语言模型的训练,再到后端的解码),而深度学习方法较多地作用于声学模型和语言模型部分(或者端对端模型),所以,深度学习框架常与专有的语音识别工具相结合,各取所长,相互弥补,以减少重复劳动、提高研发效率。表 2.3 列举了部分Github上社区较为活跃的开源语音识别工具。

Kaldi [23] 是语音识别工具中的后起之秀,年轻正是它的优势之一,可以直接汲取前人的经验,吸收当下已成熟的语音技术,没有历史中的摸爬滚打,避免了积重难返的尴尬。清晰的代码结构,完整的 GMM、WFST 实现,大量适合新手的案例教程,繁荣的开源社区,以及更开放的代码许可,使得Kaldi 吸引了大批用户。
深度学习广泛应用于语音识别后, Kaldi 先后设计了不同的神经网络构架(nnet1、nnet2、nnet3),其中 nnet3被越来越的研究者所使用,相较于其他两种构架, nnet3 采用计算图(Computational Graph) 的思路,可以更容易地设计各种类型的网络结构,并支持多任务并行计算,大大缩短训练时间。此外,也可以将 Kaldi 与通用深度学习平台结合,比如使用 Kaldi 处理语音信号和解码,而用深度学习平台专门处理深度神经网络的训练和推断。
各种开源工具应接不暇,然而善假于物而不囿于物,通晓原理,仍是使用工具的基本原则。后文将利用Kaldi 部署实验,并对实验中所涉及的相关概念和技术进行梳理。
2.7.3硬件加速
神经网络的计算多为矩阵计算,我们可以优化已有的计算机芯片(如CPU,处理单元只是芯片的核心部分,下文不做严格区分),乃至设计专门进行矩阵计算的芯片;针对不同的网络结构,也可以量身定制芯片架构、指令集,进一步提高运算效率。由于不同的深度学习平台有不同的神经网络组织格式,而不同的芯片又有不同的计算要求,为了使软件与硬件之间深度契合,二者之间需要搭建一个桥梁,即神经网络编译器。
现在的人工智能技术多使用深度学习,深度学习多使用神经网络,所以常说的人工智能加速器、深度学习加速器都是神经网络加速器,其核心处理单元也叫 NPU(Neural Processing Unit)。图2.16展示了两种常见神经网络加速器GPU、TPU与CPU在内存机制和矩阵计算方式上的差别。
GPU
GPU(Graphics Processing Unit,图形处理器)很多时候是深度学习研究和应用的标配,理所当然地可以看做是神经网络加速器,只是如其名,GPU可以通俗地称为“显卡”, 最初是用于图形像素计算的,“阴差阳错”地碰到了深度学习。因为一幅图像的数据表示形式就是矩阵,所以GPU很适合快速的矩阵运算。

FPGA
现场可编程门阵列(Field Programmable Gate Array,FPGA)也适用于神经网络芯片的设计,使用FPGA的优势在于定制化、实现便捷,但其速度和能耗也会打折扣。
TPU
为特定的方法或模型设计特定的计算芯片,就是专用集成电路(Application-specific In-tegrated Circuit,ASIC)设计。TPU(Tensor Processing Unit,张量处理器)是谷歌为深度学习专门设计的 ASIC[25],这里的“Tensor”既是TensorFlow里的“Tensor”,也是PyTorch里的“Tensor”,表明TPU可以进行Tensor(可以看做多维矩阵)级别的计算。图 2.17 展示TPU 用于计算的子模块以及其最终形态的电路板。

其他 AI 芯片
上述几个神经网络加速器类型都属于 AI 芯片的范畴,具有通用性,既可以做训练也可以做推断,且并不针对特定的神经网络结构,但另一类 AI 芯片则多是用于推断,即实际产品中的使用,更注重功能。随着深度学习的实用化,出现了很多专注于 AI 芯片的公司,比如寒武纪公司、地平线公司、平头哥公司等。
软件层面上,深度学习框架各有不同,模型的格式和算子各异;硬件层面上,CPU、GPU、TPU以及其他ASIC的内存机制和计算方式也各有不同,所以某个模型应用于某种芯片,中间的编译过程是很有必要的,这是使得计算得以顺利进行,以及进一步提高计算效率所必须的。文献 [26] 对主要的神经网络编译器及其方法进行了梳理,当下较为常见的神经网络编译器包括Glow[27]、TVM[24]等。
2.8小结
本章分别介绍了声学模型、语言模型、解码器及端对端语音识别方法。声学模型、语言模型是 ASR 的基本模块,解码器将二者联系起来,实例化 ASR 系统。端对端 ASR 系统融合了声学模型和语言模型,但其模型的设计和训练仍会参照声学模型和语言模型的功能,所以声学建模和语言建模是 ASR 的基本概念。本章也对常用的开源工具和硬件平台进行了简介。
References
[1]Dong Yu and Li Deng. Automatic speech recognition. Springer, 2016.
[2]Christopher D Manning and Hinrich Schütze. Foundations of statistical natural language processing. 1999.
[3]Frederick Jelinek. “Up from trigrams!-the struggle for improved language models”. In: Second European Conference on Speech Communication and Technology. 1991.
[4]Reinhard Kneser and Hermann Ney. “Improved backing-off for m-gram language modeling”. In: IEEE International Conference on Acoustics, Speech and Signal Processing. 1995, pages 181–184.
[5]Kenneth W Church and William A Gale. “A comparison of the enhanced Good-Turing and deleted estimation methods for estimating probabilities of English bigrams”. In: Computer Speech & Language (1991), pages 19–54.
[6]Slava Katz. “Estimation of probabilities from sparse data for the language model component of a speech recognizer”. In: IEEE Transactions on Acoustics, Speech, and Signal Processing (1987), pages 400–401.
[7]Jacob Devlin et al. “Bert: Pre-training of deep bidirectional transformers for language understanding”. In: arXiv preprint arXiv:1810.04805 (2018).
[8]Yinhan Liu et al. “Roberta: A robustly optimized bert pretraining approach”. In: arXiv preprint arXiv:1907.11692 (2019).
[9]Zhilin Yang et al. “Xlnet: Generalized autoregressive pretraining for language understanding”. In: Advances in neural information processing systems. 2019, pages 5754–5764.
[10]Zhenzhong Lan et al. “Albert: A lite bert for self-supervised learning of language representations”. In: arXiv preprint arXiv:1909.11942 (2019).
[11]Joonbo Shin, Yoonhyung Lee, and Kyomin Jung. “Effective Sentence Scoring Method Using BERT for Speech Recognition”. In: Asian Conference on Machine Learning. 2019, pages 1081–1093.
[12]Mehryar Mohri, Fernando Pereira, and Michael P Riley. “Weighted finite-state transducers in speech recognition”. In: Computer Speech & Language (2002), pages 69–88.
[13]Jan K Chorowski et al. “Attention-based models for speech recognition”. In: Advances in Neural Information Processing Systems. 2015, pages 577–585.
[14]Dzmitry Bahdanau et al. “End-to-end attention-based large vocabulary speech recognition”. In: IEEE International Conference on Acoustics, Speech and Signal Processing. 2016, pages 4945–4949.
[15]Alex Graves et al. “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks”. In: Proceedings of the 23rd international conference on Machine learning. 2006, pages 369–376.
[16]Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton. “Speech recognition with deep recurrent neural networks”. In: IEEE International Conference on Acoustics, Speech and Signal Processing. 2013, pages 6645–6649.
[17]Alex Graves. “Sequence transduction with recurrent neural networks”. In: arXiv preprint arXiv:1211.3711 (2012).
[18]Yanzhang He et al. “Streaming End-to-end Speech Recognition For Mobile Devices”. In: IEEE International Conference on Acoustics, Speech and Signal Processing. 2019, pages 6381– 6385.
[19]Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate”. In: arXiv preprint arXiv:1409.0473 (2014).
[20]William Chan et al. “Listen, attend and spell”. In: arXiv preprint arXiv:1508.01211 (2015).
[21]Ashish Vaswani et al. “Attention is all you need”. In: Advances in neural information processing systems. 2017, pages 5998–6008.
[22]Suyoun Kim, Takaaki Hori, and Shinji Watanabe. “Joint CTC-attention based end-to-end speech recognition using multi-task learning”. In: IEEE International Conference on Acoustics, Speech and Signal Processing. 2017, pages 4835–4839.
[23]Daniel Povey et al. “The Kaldi speech recognition toolkit”. In: IEEE 2011 Workshop on Automatic Speech Recognition and Understanding. 2011.
[24]Tianqi Chen et al. “{TVM}: An automated end-to-end optimizing compiler for deep learning”. In: 13th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 18). 2018, pages 578–594.
[25]Norman P Jouppi et al. “In-datacenter performance analysis of a tensor processing unit”. In: Proceedings of the 44th Annual International Symposium on Computer Architecture. 2017, pages 1–12.
[26]Mingzhen Li et al. “The Deep Learning Compiler: A Comprehensive Survey”. In: arXiv preprint arXiv:2002.03794 (2020).
[27]Nadav Rotem et al. “Glow: Graph lowering compiler techniques for neural networks”. In:arXiv preprint arXiv:1805.00907 (2018).
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






