spss快速学习(零基础学习SPSS软件)
作者:郑铿城,经济学博士,数学建模指导教练
开头,和大家讲个笑话

spss软件在数据处理分析中有较广的运用,适合各类学习群体,就算学习者不会编程,也可以通过spss软件实现数据的处理和模型的建立。以下归纳了spss软件中一些比较常用的功能和操作步骤,全是干货哦!

1.熟悉变量窗口和数据窗口
数据窗口是我们打开spss一开始时,其页面所展现的窗口,主要用于输入相关的数据,在其页面中有相关的操作栏项目,可以进行对数据的具体分析。如下:

对于变量窗口,是对数据的变量做相应的改动调整的窗口,包括对数据的名称、类型、宽度、小数位、标签、度量标准等等。

在spss左下方有变量窗口和数据窗口的转换按钮,即可选择不同的窗口进行操作:

2.学会数据输入
数据输入有两种,一种是手动输入数据,一种是通过已经有的excel数据,对数据进行键入。手动输入比较简单,就是在数据窗口把自己想要用的数据打入即可,然后点击左下方选择变量窗口,对数据的属性进行相应的调整。对于使用已经有的数据,并把数据键入,要注意以下问题:
首先数据是以列来排序,即每一列代表一种数据,如果你的数据是每一行代表一种,那么你需要对你的数据进行转置处理。
比如我们键入以下数据:

那么在spss窗口中,点击“文件”--“打开”--“数据”
选择想要键入的数据,会弹出这样一个页面,注意,要选择打钩。

初试数据键入以后,效果是这样的:

我们可以点击到变量窗口,进行相关的调整,使数据看起来更加的好看一点,比如统一小数位,调整数据所在行的宽度等,结果如下:

3.数据管理
这个就很简单了,一些相关的参考书中,主要讲了把数据进行纵向和横向的合并,对数据进行拆分,对数据进行汇总,对数据进行加权,对数据进行查找。这些都很简单,比较有意思的应该是数据的汇总和加权,数据汇总可以通过数据的均值、中值、总和、标准差等标准进行汇总,数据的加权通过“数据”--“加权个案”实现。
4.统计描述分析
用spss进行统计描述分析,主要有三个板块,一个是频数分布描述;一个是描述性统计分析;一个是探索性分析。
首先讲一下频数分布:频数分布就是用来对数据的集中趋势和离散程度进行描述,通过频数分布图、条图和直方图等,来更加形象的说明数据的分布特征。步骤是:“分析”--“描述统计”--“频率”,通过相应程序的操作,假设输入以下数据:

通过频数分布描述的spss步骤运行,同时进行相关的设置:
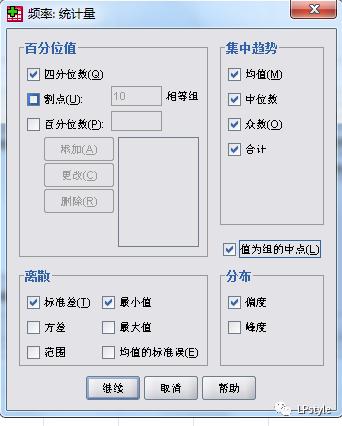

得到的结果如下:

上图反映的是这些输入数据的均值、中值、众数等特性。

上图反映的是频率的一个情况,可以清楚的看出每个型号都频率。

最后也得出了上图这个直方图。
然后我们来说一下描述性统计分布,命令为:“分析”--“描述统计”--“描述”。这个主要也是用来计算描述集中趋势和离散趋势的各种统计量。(此外还有一个重要的功能是进行标准化变换即Z变换),这个和上面那个频数分布其实大同小异吧,都是用来体系数字的特征的。
举个栗子,我键入以下数据,进行描述性分析:

通过的运行,最终得出的结果如下图:
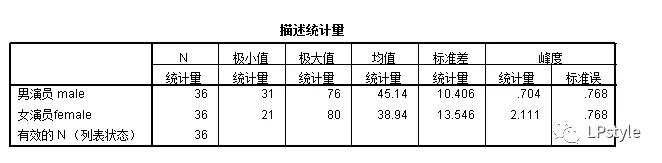
(确实,也就是各类统计量,像极大值极小值标准差等)
最后,该部分的最后一个版块,即探索性分析,这个的话是建立在对数据有一定的了解的基础上,对数据进行更加深入的分析(你可以理解为这种方法做出的图看起来更加牛逼了)
举个栗子,我还是用一些数据进行操作:


spss命令为:“分析”--“描述性统计”--“探索”。操作如下:
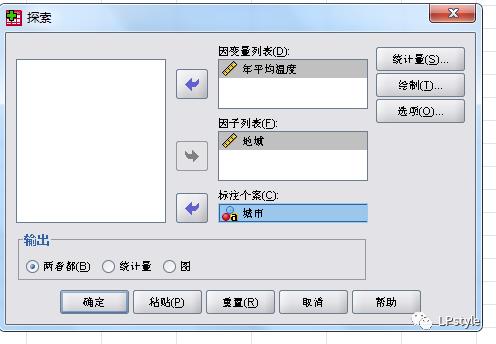
最终得到的结果:

上面这个当然就是简单的数据描述。

还有一个以“南北”分开进行的描述。
还可以得到一个这样的图:

还可以操作出茎叶图等图形。
在前面的操作中,我们从输出窗口可以看到代码,其实这就是spss的运行代码,系统自动生成的,如果你是用spss进行建模写作的话,这些代码就可以复制到你的论文的附录部分。如:

5.均值检验
均值检验也叫means检验,很好理解,就是求数值均值的过程,在spss中的命令为“分析”--“比较均值”--“均值”,这个比较easy,也好理解,就不做例子。

这个比较均值窗口中包括了像单样本T检验,独立样本T检验,配对样本T检验和单因素分析,这些内容其实也是大同小异,可以输入数据尝试输出结果,总结一点:在输出结果中要看到sig值,也就是我们说的P值,这个值如果是小于0.05的(显著性一般为0.05),那么就表明两个数据个体是有差异的。你也可以从概率的角度来理解(p值如果小于显著性水平,则应该拒绝原假设,认为样本之间存在差异)。当然我们也可以对这些概率做一个区分:
单样本T检验的目的是利用某总体的样本数据,推断该总体的均值是否与指定的检验值存在显著性差异;
独立样本T检验的目的是利用两个总体独立的样本,推断两个总体的均值是否有差异。
匹配样本T检验的目的是用两个不同的总体的配对样本,来推断两个总体的均值是否存在差异。
其实吧,都是在分析两个东西的差异性。怎么从他输出的结果来看呢,其实就抓住P值来分析即可。
6.方差分析
在比较两组资料的均数是否相等的时候,可以采用的是T检验,当组数大于等于3的时候,就应该使用方差分析。方差分析的原理不再赘述。在进行方差分析中,要学会通过LSD方法看出组数之间的差异。
具体命令:“分析”--“比较均值”--“单因素ANOVA”
在设置对话框中选择LSD方法,从输出结果来进行分析。
举个栗子:有三组企业和对应的寿命:



利用单因素ANOVA方法,选取LSD进行操作

得到的结果如下:
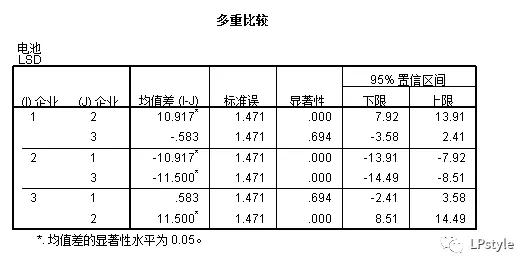
由上表可知显著性的大小为0.05,那么如果两个组别的显著性大小比0.05大,则接受原假设,认为两个组别是无差异的,那么通过上表可以看出1组和3组是无差别的,1组合2组是有差别的,2组合3组也是有差别的。
7.利用spss进行绘图
绘图操作是一项重要技能,利用spss进行绘图,操作简单快捷,只需要对数据进行选择,然后点击自己想要绘制的图形格式即可。

当然绘图的时候你数据窗口中要有数据,具体可以自己实验一下。

假设我们要绘制一个时间为横坐标,GDP为纵坐标的二维直方图,即可进行操作得到如下结果:

当然在第二个绘图指令中,还可以进行这样的操作:

你选择几个变量,就会有相应的几维图形。(最多构造三维哦)
在绘图中,点击“旧对话框”会显示下面内容:

同理根据自己的需求进行图形的绘制。
8.缺失值分析
理解这个很简单,就是我们在数据收集的过程中,可能存在数据的缺失,那么数据的缺失就会对我们的处理结果造成一定的影响。利用spss软件对缺失值进行处理,使我们分析的相关结果更加合理。
对缺失值的处理方法有很多,包括什么直接删除法、或者用什么数据来进行替代,也可以用EM或者回归的方法,从未缺失的数据分布情况中推算出缺失的数据的估计值。“分析”--“缺失值分析”
首先我对之前的那份GDP数据进行故意挖空,形成缺失现象,便于进行分析:

主要挖了三处空,然后利用spss缺失值分析中的EM进行数据的缺失处理,得到下图:

这样就完成了缺失值的处理,当然也可以用回归的方法。


9.简单线性回归和相关性分析
先讲相关性,相关性用r表示,r值为正则正相关,反之则为负相关。r的绝对值越大,则相关性越强。可以用spearman等级相关系数来看相关程度。

举个栗子:利用下面数据做相关性分析并构造回归模型。


当然kendall和pearson相关系数也是可以表示相关性的,都差不多。

通过这个pearson相关系数(等于0.971)可以看出两个变量的相关性很强!

得到的spearman系数和kendall系数也是接近于1的,表明两个变量之间确实存在的正的相关性。再利用回归方法确定出模型:

如下图所示进行相关设置:
进行操作,得到的结果如下:

通过上表,则我们的回归模型为:(设患病率为Y,碘含量为X)
Y=17.484 4.459X。

10.Logistic回归模型
如果要分析的数据是分类变量,那么可以采取logistic回归模型对数据进行分析,首先讲一下二项分类的logistic回归,该模型的方程为:
P=1/(1 EXP(-b0 b1x1 b2x2 ... bnxn))
通过spss确定出上述方程的系数,即可确定出该模型。

举个栗子:

查看变量窗口:

y表示康复情况,y=0则是没有康复,y=1则是康复,x1表示病情的严重程度,x1=0则表示病情不严重,x1=1则表示病情严重。x2表示疗法,x2=0则表示新疗法,x2=1则表示旧疗法。
并进行如下设置:

结果为:

通过上表,可以得到二元logistic回归模型为:
P(Y=1)=1/(1 EXP(-0.928-0.909X1-1.669X2))
即疗法的新旧对于康复情况是有影响的,当疗法比较就新的时候,康复的概率会更高一点。
当然logistic回归除了有二项的以外,还有有序的logistic回归,条件logistic回归等。方法类似。

方法总结,对于该部分的logistic回归方程,首先你要确定你要使用哪个类型的logistic回归模型,然后去寻找该模型的一个表达式,再通过spss软件,求出系数,把系数代入表达式,即可构造出模型。比如上述中确定了二项logistic回归的表达式:

那么通过spss确定系数以后,代入表达式即可得出模型。

11.聚类方法
物以类聚,人以群分。对数据或者样本进行聚类,了解对象的类别,具有一定的探索性。聚类的原理是什么呢,很简单,就是通过距离和相似系数进行聚类,其原理不再说明。
常用的有k均值聚类和系统聚类。
举个栗子:

对以上数据进行聚类:“分析”--“分类”-“k-均值聚类”

同时确定分类数:


由于设置的是聚类成两类,所以结果显示如下:
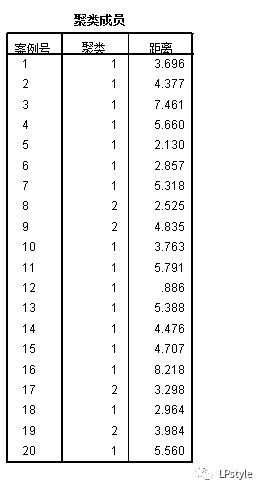
可以看出不同案例号对应的类别,当然你也可以尝试设置成4类等,看看结果会发生什么变化。(如下)

也可以进行系统聚类:比如对这些数据进行系统聚类:

得到的一个垂直冰柱图和树状图:


12.主成分分析、因子分析
这里用的是一个降维的思想,从一堆变量中,选取出一些主要变量进行分析。主要还是通过特征根的大小来衡量。

主成分分析和因子分析到底有什么异同?大家可以先自行了解一下,提示:主成分分析实质是线性变换,无假设检验,因子分析是统计模型,有些因子模型可以做假设检验,其次主成分分析在spss操作中不需要旋转,而因子分析则需要旋转。
举一个因子分析例子,并通过构造碎石图、做球形检验和旋转来看看因子分析的具体操作:

其x1到x9分别表示:

选择“分析”--“降维”--“因子分析”:得到的结果如下:
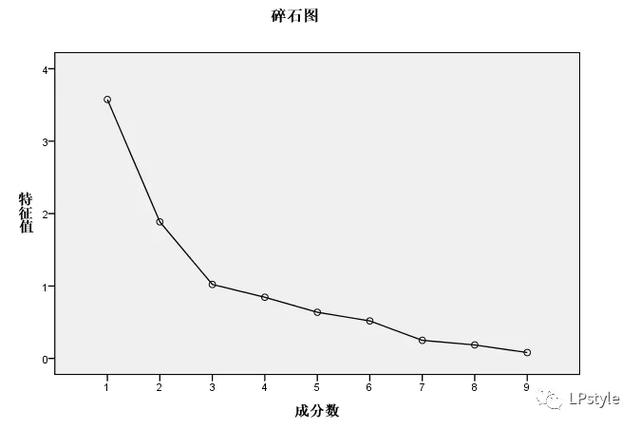
碎石图怎么看?看斜率,前3的成分的斜率比较陡峭,故可以用前三个元素来代表所有元素。

从球形检验这个表,可以看出KMO值大于最低标准0.5,所以适合做因子分析,同时P值小于0.001,适合做因子分析。
也可以看到没有旋转之前的成分矩阵和旋转以后的成分矩阵:
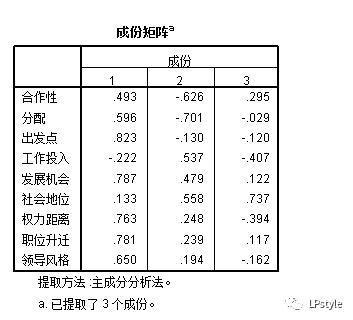

那么我们就可以去说明前3个因子中,他们各自的什么含量成分比较大,同时进行相应的说明。
13.信度分析
这个方法是用在调查问卷中的,信度就是反应测量结果的一致性和稳定性。在spss中的操作为“分析”--“度量”--“可靠性分析”
做一个例子分析:

对上表的结果做一个信度分析:

得到信度结果:

cronbach“阿发”的系数为0.811,故该试卷的信度较好。从下面这个表,可以看出:

有一个crobanch的系数值大于0.811,这个就表明:如果在试卷中删除名解的话,会提高试卷的信度值。
最后再讲一个生存分析和Cox模型:
生存分析是把生存时间和生存结果综合起来,对数据进行分析的一种统计方法。举个栗子就懂了:(数据如下)


通过“分析”--“生存函数”--“寿命表”得到:


Cox模型:可以建立生存时间和危险因素之间的依存关系的模型。
命令:“分析”--“生存函数”--“COX回归”


学完SPSS,对数据量化分析有了进一步的了解,SPSS不仅可以用在建模,也可以用在论文研究等领域,觉得ok就分享给身边的同学吧!
,
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com