新出的捏脸游戏在哪(腾讯游戏开发精粹II)
《腾讯游戏开发精粹Ⅱ》是腾讯游戏研发团队不断积累沉淀的技术结晶,是继2019年推出《腾讯游戏开发精粹》后的诚意续作。本书收录了21个在上线项目中得到验证的技术方案,深入介绍了腾讯公司在游戏开发领域的新研究成果和新技术进展,涉及人工智能、计算机图形、动画和物理、客户端架构和技术、服务端架构和技术及管线和工具等多个方向。本书适合游戏从业者、游戏相关专业师生及对游戏幕后技术原理感兴趣的普通玩家。
腾讯游戏开发精粹II——1.1 游戏中的捏脸系统可戳此查看。
1.2 基于照片的角色捏脸流程
基于照片的自动捏脸流程如图1.1所示。对于给定的单张照片,首先检测其中最主要的人脸,同时进行发型分类及眼镜检测。在检测到的人脸区域,进一步进行关键点检测。在真实照片中,人脸可能并不是正视摄像头的,并且真实人脸并非总是完美对称的,因此,需要将原始照片中的关键点进行预处理,以达到归一、对称、平滑的效果。下一步需要根据游戏具体的风格,对人脸关键点进行调整。
如果是偏向写实风格的游戏,可以直接使用预处理后的关键点,也可以添加额外的调整,如瘦脸等;如果是偏向卡通风格的游戏,则需要根据游戏风格对真实人脸的关键点进行调整,使得调整后的关键点既符合游戏风格,又保持用户特征。
得到了风格化关键点后,需要将其转化为游戏中模型的控制参数。有些游戏采用网格控制,那么可以直接将标准模型网格变形,使变形后的关键点位置达到用户的预期,同时保持平滑;有些游戏采用骨骼或滑条控制,那么需要将风格化关键点转化为相应的参数。

图1.1 基于照片的自动捏脸流程
根据图1.1,2.1~2.9节将对应介绍每一个模块的具体实现及相应的定义。
1.2.1 基于关键点的人脸表示方法为了从照片上自动提取人脸的特征,首先需要对脸部特征进行表示。脸部特征一般分为形状特征与颜色特征两个部分。形状特征主要指脸型及五官的边界。例如,脸部的轮廓、眼睛的轮廓、眉毛的轮廓等。颜色特征包括面部各个区域的颜色,如肤色、眉色、唇色等。无论哪种特征,都需要对脸部重要部分进行形状和位置的定位,并且定位信息需要包含3D坐标。
为了有效表示脸部特征,业内比较成熟的表示方式是使用关键点信息。所有的关键点都定义在脸型和五官的边界处。我们希望尽可能准确地表示人脸各个部分的形状信息,关键点越多,显然拥有越强的表示能力。但是,为了能够自动捏脸,程序需要对定义的关键点的3D信息进行估计,关键点越多,预测难度越大。综合两方面考量,本章介绍的自动捏脸流程采用了如图1.2所示的96个关键点的定义方式。
对于给定的单张照片,程序会检测这96个关键点,并估计出它们的3D空间的坐标,这样就可以得到人脸主要部位的形状信息。根据具体的游戏需求,对关键点进行符合游戏风格的调整,如对称化、眼睛放大、瘦脸等,从而得到游戏人脸模型的关键点的目标位置。对于默认的游戏中的人脸模型,需要预先标定其网格上对应的96个关键点,将它们调整到上述的目标坐标,并在此过程中保持人脸网格的平滑,从而得到最终的带有人脸特征的游戏人脸。

图1.2 人脸关键点定义
《腾讯游戏开发精粹Ⅱ》电子版已上线UWA学堂 | Unity和Unreal游戏引擎的从业者学习交流平台,感兴趣的读者可以前往阅读。
1.2.2 人脸关键点检测
本节将介绍人脸关键点的检测方法。如图1.3所示,为了对用户输入的照片进行关键点预测,首先需要进行人脸检测,根据人脸检测框对输入照片进行裁剪和缩放得到固定大小的人脸照片(如256像素×256像素),才能进行人脸关键点预测。现有基于深度学习或图像特征的方法都可以比较有效地检测到照片中的人脸,基于深度学习的人脸检测方法相对于基于图像特征的方法可以在更加难以识别的照片中检测到人脸,如人脸朝向较偏,或者光照阴影干扰较大的情况。
但是,基于深度学习的方法需要使用GPU进行推理,否则人脸检测速度较慢,尤其是对于较大的照片。图1.4所示为在使用CPU进行计算的情况下,基于深度学习(CNN)和基于图像特征(HoG)的方法进行人脸检测的速度对比。当具体应用时,如果有GPU计算资源,可以使用基于深度学习的方法进行人脸检测;如果没有,可以使用基于图像特征的方法进行人脸检测。

图1.3 人脸检测和关键点预测
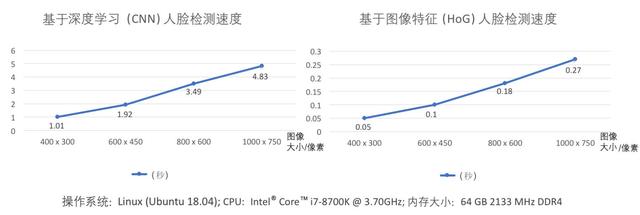
图1.4 人脸检测的速度对比
在进行人脸检测时,依据照片中的人脸个数,检测程序会输出若干方框,所以在使用和处理人脸检测结果前需要进行判断处理。如果输出人脸检测方框数目为0,表明人脸检测没有输出,需要提示用户重新输入照片;如果输出人脸检测方框数目大于1,表明检测到2个或以上人脸,程序会默认选择最大人脸检测方框对应的人脸进行处理。确定使用人脸检测的某个检测方框输出后,需要根据方框进行缩放和裁剪得到固定大小的人脸照片,从而进行人脸关键点预测。缩放和裁剪后得到的照片大小要和人脸关键点检测模型中使用的训练图片大小一致。
人脸关键点检测作为一个计算机视觉领域的长期研究问题,随着近年深度学习的发展,在使用卷积神经网络(CNN)后得到了更好的解决。3D人脸重建和人脸关键点(图像域)检测这两个问题联系紧密,解决一个问题,可以简化另一个问题。传统方法往往进行人脸关键点检测从而辅助人脸识别或3D人脸重建等任务。但是,当人脸偏转或被遮挡时,3D关键点检测往往不准确从而影响后续任务的性能。
基于CNN的3D人脸重建和人脸关键点检测方法,大体上可以分为两类。第一类方法是基于3D Morphable Model(3DMM)的方法[1][2]。这类方法使用CNN来预测3DMM系数或3D形变,根据单张2D人脸照片来复原人脸3D信息,从而进行密集的关键点检测或人脸3D重建。这类方法虽然取得一些进展,但是效果受限于人脸模型或模板定义的模型空间,所重建的3D人脸往往过于接近模板而较少保留重建对象人脸的特征。另外,这类方法使用CNN预测3DMM系数后需要调用模型基得到3D人脸三角面片模型,还需要使用透视投影和3D非线性形变等计算。这一系列计算增加了3D人脸重建的计算开销,不符合实时性高的计算需求。与第一类方法不同,第二类方法跳过3DMM,用端到端的网络直接根据2D人脸照片重建3D人脸模型[3][4]。
其中,Adrian Bulat等通过训练一个复杂的神经网络来回归68个人脸2D关键点,用另一个网络去估计关键点的深度。Aaron Jackson等提出了用体素来表征3D人脸,在一个网络中用2D人脸照片来回归预测体素表达。这种体素表达把人脸网格3D模型转化成一个3D立方体,有很多冗余,几千个顶点的人脸网格3D模型转化成3D立方体后,数据量要增加一个数量级。为了减少数据量,需要牺牲分辨率来减少3D立方体的大小。此外,用于回归这种体素表达的网络很复杂。
目前常用的两类CNN人脸重建方法各有优劣。基于人脸模型的方法保留了关键点的语义信息但是受限于模型空间;无模型/数据驱动的方法(Model-Free)不受模型限制,虽然在性能上略有优势,但是不能保留图像上的语义信息。近年来,第三类方法开始出现,这类方法提出使用无模型的方法重建3D人脸且保留关键点信息[5]。此方法提出了同时预测密集关键点和3D人脸重建的CNN框架,多个公共数据集显示该方法优于同类算法。本文采用了类似直接从原始照片来回归Position Map(位置图)的方法,从而达到关键点预测快速和高准确度的目的。关键点预测模型网络架构如图1.5所示。

图1.5 关键点预测模型网络架构
从应用层面上讲,对于一个人脸重建或关键点检测的应用,选择哪一类CNN方法要考虑方法的性能和泛化能力、模型预测的速度、模型网络的大小等。但是,对于实际应用来说,确定一个适当的网络框架仅仅是整个工作的开始。首先,学术界人脸关键点检测的标准是68个关键点。但是,68个关键点对于具体的应用是否足够?这需要用68个关键点的检测结果,针对具体应用进行实验和分析得出结论。对于VR/AR或人脸卡通化的应用,68个关键点往往不能准确地捕捉人脸的细节和特征。例如,眉毛的厚度、眼角的形状等都不能达到游戏捏脸的精度需求。
在不计时间和成本的情况下,一般希望标注数据中的关键点越多越好。但实际的情况是,关键点定义得越多,标注时间越长且越困难。在68个关键点之外新增加的关键点往往并不位于人脸五官的边界上或没有明显的图像边界特征,在这样的情况下增加的关键点往往很难标准,或者说,不同的人标注的数据差异很大。这样的话,标注本身的噪声就会变大,从而使用这些标注数据进行网络训练也比较难达到好的效果。经过内部迭代,最终确定了使用96个关键点的方案。因为这样关键点数据足够多,且可以保证标注准确度。96个关键点的示例参照图1.2。
定义好关键点后,应该思考如何标注。标注工具基于现有的CNN的人脸关键点检测预训练模型,首先给出初始的68个关键点的预测,用户对68个关键点进行交互式调整。然后用户可以自行添加剩下的新定义的关键点。在整个标注过程中,为了让用户更好地评估自己标注的关键点的质量,关键点的拟合曲线叠加显示在标注图像上作为可选项提供给用户进行参考。如果曲线和人的面部五官轮廓贴合,则标注较好;如果曲线和面部五官轮廓差异大,则标注不够好。通过这种标注方式,标注人员可以快速进行半自动的人脸关键点标注,用户可以用拟合曲线叠加显示的方法对自己的标注进行评估,并进行修改。这样可以保证关键点标注的快速性和准确性。
选择好标注方式后,需要进行数据的收集和整理。数据收集和整理完毕后,可以使用标注工具进行标注。数据标注完毕后,可以开始进行模型训练。为了评估训练好的模型,需要对预测和手工标注的关键点进行比较和模型准确度量化分析。具体量化分析方法:计算模型预测关键点的平面坐标和手工标注关键点的坐标的欧式距离,用来作为度量,距离越近,误差越小,表明预测关键点与手工标注关键点越接近。图1.6所示为111张测试照片数据的量化分析结果。
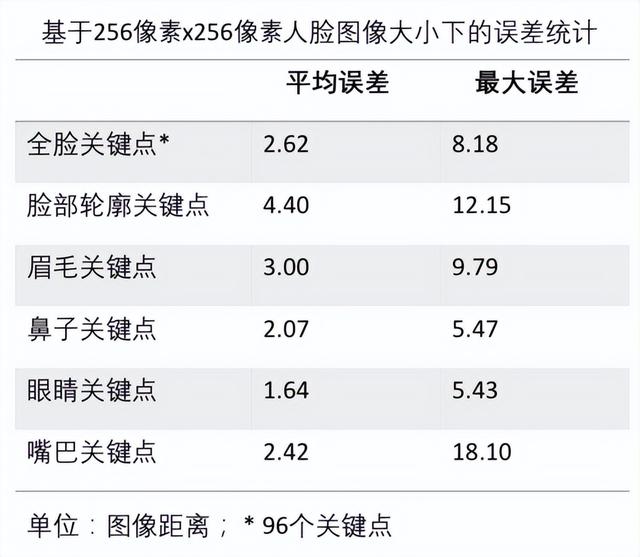
图1.6 111张测试照片数据的量化分析结果
《腾讯游戏开发精粹Ⅱ》电子版已上线UWA学堂 | Unity和Unreal游戏引擎的从业者学习交流平台,感兴趣的读者可以前往阅读。
1.2.3 人脸关键点风格化调整
检测了人脸关键点后,检测结果无法被直接使用。因为真实人脸的视角可能未必正对摄像头,并且存在左右不对称、关键点检测误差等问题。因此,程序需要对检测结果进行一定的预处理。预处理的过程可以分为3步:关键点归一化、关键点对称化、关键点平滑化,如图1.7所示。下面将对其一一具体说明。

图1.7 关键点预处理流程
1.2.3.1 关键点归一化
从图1.1可以看到,系统需要根据真实人脸的关键点预测来调整游戏中的标准人脸模型,这个过程需要确保两者的关键点在尺度、位置、方向等方面统一。因此,程序需要将预测的关键点与标准模型的关键点进行归一化,具体包含以下几个部分:尺度归一化、位置归一化、角度归一化。
定义原始的检测的所有3D人脸关键点为P,其中第i个关键点为pi={xi,yi,zi}。归一化原点可以被定义为1号和17号关键点的中点(请参考图1.2的关键点定义),即c=(p1 p17)/2。对于尺度,定义1号和17号关键点距原点的距离均为1。所以可以得到尺度归一化与位置归一化后的3D关键点为P′=(P-c)/‖p1-c‖2。
尺度归一化与位置归一化后,人脸需要被进一步转正。如图1.8所示,实际照片中的人脸未必正对镜头,往往会有一定的偏转,这种偏转在3个坐标轴上都可能存在。

图1.8 人脸旋转坐标轴定义
依次将预测的人脸3D关键点沿x、y、z坐标轴进行旋转,使得人脸的方向正对摄像头。当沿x轴旋转时,将18号与24号关键点的z坐标对齐(请参考图1.2的关键点定义),即让鼻梁上端与鼻子下端处于同一深度,得到旋转矩阵Rx;当沿y轴旋转时,将1号与17号关键点的z坐标对齐,得到旋转矩阵Ry;当沿z轴旋转时,将1号与17号关键点的y坐标对齐,得到旋转矩阵Rz。这样就可以将关键点方向对齐,并得到归一化的关键点。
Pnorm=Rz×Ry×Rx×P′
1.2.3.2 关键点对称化
从图1.7可以看到,归一化的关键点的尺度、位置、方向都已经调整统一。然而得到的关键点往往并不构成一个比较完美的人脸,如鼻梁不位于中心的一条直线上,五官左右不对称。这是因为真实人脸在照片中由于表情或本身的特征并不会完美对称,并且在关键点预测时会引入额外的误差。虽然真实人脸未必对称,但是游戏中的人脸模型不对称会导致不美观,将大大降低用户体验,因此关键点对称化是一个必要的过程。
因为关键点已经进行过归一化,所以一个简单的对称化方法就是将所有左右对称的关键点的y、z坐标取平均,替代原有的y、z坐标。这种方法在多数情况下效果良好,然而当人脸在y轴方向上旋转角度较大时会对效果造成一定影响。
以图1.7中的人脸为例,当人脸向左侧偏转角度较大时,部分眉毛的区域将不可见,同时透视会造成左眼整体小于右眼。虽然预测的3D关键点可以部分弥补透视造成的影响,但是仍需要保持3D关键点的2D投影与照片上的关键点对应。因此,过大的角度偏转会导致得到的3D关键点检测结果出现明显的双眼、双眉尺寸不同的情况。
为了处理这种由角度造成的问题,当人脸沿y轴偏转角度较大时,自动捏脸系统使用靠近镜头一侧的眼睛与眉毛作为主眼、主眉,并将其镜像复制到另一侧以减小角度偏转造成的误差。
1.2.3.3 关键点平滑化
由于预测误差不可避免,因此在个别情况下,进行对称化的关键点仍然有可能不符合真实人脸,如脸部出现不自然的凹陷、眉毛出现锯齿状等。由于人与人之间的脸型及五官的形状差别较大,所以使用预定义的参数化曲线很难达到相对准确的描述。因此,在平滑化时,程序仅对部分区域进行平滑:人脸轮廓、眼睛、眉毛、下嘴唇。经观察,这些区域在真实人脸上基本都保持了曲线的单调平滑特征,即不存在锯齿状的情况。在这种情况下,目标曲线应该始终为凸曲线或凹曲线。
归一化模块对要检测的边界逐个检查关键点是否满足凸曲线(或凹曲线)的定义。如图1.9所示,不失一般性,假设目标曲线应为凸曲线,那么对于每个关键点(实线圆点),需要检查其位置是否在相邻的左右关键点连线的上方。如果满足条件,则当前关键点符合凸曲线要求;否则,将当前关键点向上移动到左右关键点的连线之上。在图1.9中,左起第3个实线关键点不满足凸曲线的要求,程序会将其移动到上方虚线关键点的位置。需要注意的是,如果多个关键点发生移动,那么由于检查曲线凹凸的关键点为原始关键点,移动后不一定保证曲线为凸曲线或凹曲线。因此,归一化模块采用多轮平滑的方式,以得到相对平滑的关键点曲线。

图1.9 关键点平滑化示例
经过如上步骤预处理的关键点可以相对较好地表示真实人脸的特征,如五官位置、比例、脸型等。下一步需要将这些关键点风格调整为游戏人脸风格。
1.2.3.4 关键点风格化
不同游戏有不同的人脸风格,自动捏脸系统需要将真实人脸的关键点风格转化成游戏所需的风格才能生成游戏中的人脸。真实系的游戏人脸大同小异,但是卡通系的人脸千差万别。因此,关键点风格化很难有统一的标准。
本章介绍的捏脸流程实现了较为通用的、多数游戏可能需要的人脸调整方案。例如,脸长短调整、宽窄调整、五官比例缩放等。根据不同的游戏的美术风格,调整程度、缩放比例等都可以进行自定义的修正。
1.2.4 基于关键点的网格变形
获得了带有人脸特征且符合游戏风格的目标关键点后,自动捏脸系统需要对游戏里的标准人脸模型进行变形,使得标准模型上的关键点能调整到目标位置,并且在调整过程中保持模型的平滑。
为了拥有更强的普适性,本章的捏脸方案在设计之初,就希望能够应用在不同风格不同种类的头模上。在游戏制作中,美工通过3DMax或Maya等3D建模工具制作出的头模尽管有多种保存格式,但是内在的模型表征方式都是多边形网格(Polygon Mesh)。游戏角色的捏脸效果可以通过改变网格结构的组合、顶点位置及贴图等多种方式实现。对网格顶点位置的变形在学术界通常划归于蒙皮(Skinning)研究的范畴。根据应用方式的不同,变形方式可以分为骨骼驱动、关键点驱动等。游戏业内常用的变形方式为骨骼驱动,所以业内蒙皮通常特指骨骼驱动蒙皮。如何通过预测的关键点回归到骨骼驱动的参数将在1.2.5节中介绍。本节将重点介绍如何在没有骨骼的情况下,利用关键点的位置信息的变化对头模进行自动优化变形。
1.2.4.1 基础模型处理和标记3D关键点
要生成3D捏脸的结果,首先需要制作一个3D的基础头模。基础头模往往是由脸、眼睛、睫毛、牙齿、头发等多个部分组合而成的,如图1.10所示。在没有骨骼的情况下,脸部变形依赖的是基础网格的连接结构,因此必须对复合的基础头模进行拆分。其中,变形的主体是脸部依托的连通模型,其他的附件则依赖脸部模型的变形结果进行调整。

图1.10 基础头模组合示例
前文提到过,照片上的人脸关键点可以通过自动检测的方式获得。但是要驱动3D网格变形,照片上的关键点就需要正确地映射到基础的脸部3D模型上。由于网格连接的不确定性和3D模型数据的稀缺性,目前业界并不存在自动标注任意3D头模关键点的方法,本章介绍的捏脸流程包括了一套可便捷使用的交互工具(此处不展开介绍),可以快速在3D模型上人工标注关键点。在自动捏脸时,这些人工标注的关键点位置将移动到风格化之后的关键点位置。
在标注时,3D关键点的位置应该尽量与前文提到的照片关键点位置对应,如图1.11所示。当然,人工标注不可避免地会引入误差。为了消除标注误差带来的失真,在风格化时,可以通过规则调整来弥补。在对真实度要求较高的项目中,由于基础模型制作得比较逼真,可以把基础模型的渲染图作为“照片”进行检测,并将检测到的3D关键点与人工标注的3D关键点进行量化比较,统计出误差。在检测真实照片时,从检测到的关键点中将该统计值剔除,就可以大致消除人工标注误差带来的不良影响。

图1.11 标记3D关键点示例
1.2.4.2 网格自动变形
与网格自动变形(Automatic Skinning)相关的研究有很多。在SIGGRAPH Asia 2014的课程分享中有专门的章节[6]对网格自动变形进行了比较全面的介绍。
解决网格自动变形的主要思路是把这种关键点驱动的形变问题转化为二次项函数优化问题,即求解一个线性偏微分方程组。二次项函数数学模型的建立有很多种方式,本节主要介绍两种:第一种称为双调和变形(Biharmonic Deformation),将网格形变转化为一个双调和函数的求解问题;第二种称为仿射变形,是另一种形式的线性偏微分求解。
1. 双调和变形
从Alec Jacobson等的论文[7]和开源代码实现[8]来看,双调和变形的数学表示可以记为:
Δ2x′=0
受限于关键点约束,即通常意义上的边界条件可以表示为:
x′b=xbc
式中,Δ是拉普拉斯算子;x′是变形后未知的网格顶点坐标;x′b是网格顶点坐标中的关键点;xbc是预测的关键点形变后的位置。这里让每个维度上双拉普拉斯方程的右值为0。双调和函数是双拉普拉斯方程的解,也是拉普拉斯能量的最小值。
能量最小化的过程本质上是网格的平滑过程。如果直接在初始网格上进行能量最小化,那么网格模型上原有的细节特征都会被平滑掉。另外,在关键点的位置没有改变的情况下,即使应用了形变方法,预期得到的结果也应该跟初始的网格模型完全一致。出于以上考虑,双调和变形选择将顶点位置的位移而不是位置本身作为变量。这样一来,变形后的位置就可以写为:
x′=x d
自然地,双调和变形的优化等式变为:
Δ2 d=0
受限于
db=xbc-xb
式中,db是关键点变形前后的位移;d是网格所有未知顶点在每个维度上的变化。如图1.12所示,蓝色区域为边界区域,是形变的驱动部分,对应前文提到的关键点。图1.12左侧3张图片是将关键点位置作为优化对象的结果,图1.12右侧3张图片是对应的优化边界条件位移的结果。可以看到,右侧结果中双调和变形平滑的是每个顶点的变化,既保证了形变后的网格模型变化过渡自然,又保留了原有模型的细节特征。
除可以使用双调和函数外,还可以使用调和函数和多调和函数优化求解。在实际应用中,实验发现以上文定义的关键点位置为边界条件,使用调和函数会导致变形结果不够光滑。而多调和函数的变形结果与双调和函数差别不大,却对被变形网格的连续性提出了更高的要求,很多时候对游戏美术制作的头模提出了更高要求。

图1.12 双调和变形示例
2. 仿射变形
受到Robert Sumner等[9]提出的变形迁移方法启发,仿射变形是另一种以关键点驱动优化求解线性方程组的数学建模方法。仿射变形把从基础网格到预测网格的变形看作每个三角面片的仿射变形的集合。一个三角面片的仿射变形可以定义为一个3×3的矩阵T和一个位移矢量d。因此,可以把顶点位置的改变记为:
vi′=Tvi d,i∈1…4
式中,v1、v2、v3分别表示三角面片的三个顶点坐标;v4是我们在每个三角面片法向方向引入的一个额外点,数学表示为:
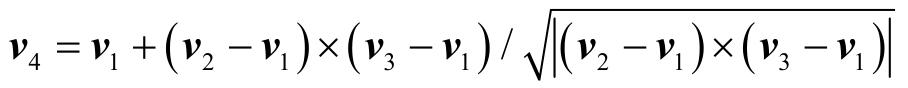
在v4的计算中,仿射变形收缩了叉乘的结果,使其与三角面片原本边的长度保持同比例。之所以引入v4,是因为每个三角面片的3个顶点在形变前后的坐标不足以唯一确定一个仿射变换。而引入了v4之后,可以用v′2,v′3,v′4分别减去v′1,经过矩阵变换后可以得到如下关系,从而唯一确定该仿射变换的非位移部分的矩阵T了。
T=[v′2-v′1v′3-v′1v′4-v′1][v2-v1v3-v1v4-v1]-1
由于矩阵V=[v2-v1v3-v1v4-v1]-1完全可以由基础网格推导出来,并且不受变形影响,所以可以如下将其预计算出来,并存储为合适的系数矩阵,方便在建立整体变形的线性系统时导入使用。


目前为止,仿射变形将每个三角面片的仿射变换的非位移部分矩阵T用数学公式和代码表示了出来。为了建立优化求解的线性矩阵,假设网格顶点数为N,三角面片数目为F,仿射变形考虑以下4种约束。
- 关键点位置约束

c′i表示预测到的变形后的关键点位置。
- 相邻面平滑度约束

代表相邻三角面片的仿射变换应该尽量接近。基础网格的三角面片相邻关系可以提前检索并存储,以避免之后重复计算,并提高最终线性矩阵创建速度。
- 特征相似度约束
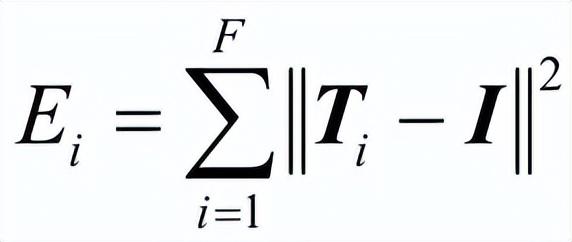
I表示单位矩阵,能量约束的含义是仿射变换幅度应该尽可能小,这样有利于保持基础网格的细节特征。
- 初始位置约束

ci表示变形前基础网格上每个顶点的位置。最终的约束能量是以上4种约束能量的加权相加:
minE=wkEk wsEs wiEi wlEl
式中,权重系数wk、ws、wi、wl按照约束强弱依次递减。根据以上约束,可以构建一个大小为(F N)×(F N)的线性矩阵。未知变量除每个顶点变形后的位置外,还有每个三角面片额外引入的虚拟点v′4。而得到变形结果需要的只有前者,后者将被扔掉。当连续变形时,除关键点约束条件改变外,其他的约束矩阵都可以复用。所以在几千到上万个顶点的网格上,可以达到实时的变形结果。
1.2.4.3 网格变形结果
仿射变形可以通过调整四种约束条件的权重达到不同的变形效果,包括逼近拟合双调和变形的效果。图1.13所示为变形方法比较示例,蓝色点代表关键点,红色代表顶点位置距离初始位置的位移大小。在所有变形结果中,一个关键点位置不变,另一个关键点移动到相同位置。这展示了在逐步调大Es相对于Ei的权重时,变形结果的平滑程度逐渐增加。另外,可以看到图1.13中最右边的双调和变形结果介于仿射变形平滑度位于10~100之间的结果。这说明仿射变形相比于双调和变形拥有更大的自由度。

图1.13 变形方法比较示例
但是双调和变形相比于仿射变形有更快的计算速度。对于几千个顶点的网格,双调和变形比仿射变形快1/3以上。随着顶点数目增多,双调和变形在计算速度上的优势进一步增大。一般情况下,双调和变形的效果已经可以满足头模的变形要求,所以自动捏脸流程默认使用双调和变形。
双调和变形和仿射变形两种自动变形方法都要求变形的网格对象是流形(Manifold)。一般来说,连通且没有重复点、边、面的网格都满足要求。本章最后提到的自动捏脸工具包提供了工具来检测变形网格是否满足要求。
在对头模变形时,网格模型需要改变的部分往往只有脸部区域。头顶、后脑勺和脖子都是不应该变动的部分,否则有可能与头发或躯干网格出现穿模或空洞等问题。本章的自动捏脸流程采用Blend Shape的方式,把由关键点驱动变形得到的头模结果跟基础头模进行线性融合。融合的权重计算可以复用双调和优化的方法计算出来。在求解时,需要把关键点所在点设为权重为1的边界条件。
另外,在头模上,标记一圈固定点,如图1.14中蓝色点所示,并把这些固定点设为权重为0的边界条件。程序可以另外加入不等式约束,令每个未知量介于0~1之间,但这样会增加求解复杂度。经过实验,求解不添加不等式约束的双调和函数,最后将结果中小于0的值设为0,大于1的值设为1,也可以得到较好的结果。在Blend Weights渲染图中,颜色最深的地方权重为1,无色的地方权重为0,关键点跟固定点之间的区域有一个自然过渡。应用了线性融合后,变形结果保持了头模后半部分的顶点位置不改变。

图1.14 融合变形示例
到此为止,本章已经介绍了关键点预测、风格化调整和网格变形。图1.15所示为串联了上述介绍的流程并应用了双调和变形,在一个真实系的基础头模上,对一些随机照片的预测变形结果。

图1.15 预测变形结果A
《腾讯游戏开发精粹Ⅱ》电子版已上线UWA学堂 | Unity和Unreal游戏引擎的从业者学习交流平台,感兴趣的读者可以前往阅读。
1.2.5 骨骼参数估计
有了风格化的人脸关键点,可以使用网格变形方法得到目标游戏人脸的网格。然而,很多游戏中的人脸网格变形并不直接调整网格本身,而通过定义的骨骼或滑条来进行调整。所以,对于此类游戏,需要进一步根据风格化的关键点来预测骨骼或滑条参数。对于生成的任一组风格化关键点,游戏需要自动找到一组合适的参数,使得由此参数得到的游戏人脸的关键点位于自动检测并风格化之后的相应位置。
由于游戏中的骨骼或滑条的定义各不相同,且存在随时修改的可能性,因此直接定义从关键点到骨骼参数的简单参数化函数并不可行。因此,本节将介绍一种机器学习的方法,通过一个神经网络来实现从关键点到参数的转换,该神经网络称为K2P网络(Keypoints to Parameters)。一般情况下,参数与关键点的数目都不多(一般小于100),所以此网络采用K层全连接网络。
为了使用机器学习的方法,需要生成大量训练数据(参数、关键点)。生成训练数据可以首先对骨骼或滑条参数进行随机采样,然后通过脚本调用游戏客户端,提取生成的游戏人脸中的关键点。由于训练模型的效果需要匹配游戏客户端,所以如果游戏的客户端更新了骨骼驱动的美术效果,那么训练数据需要重新生成。
有了训练数据后,一个直接的训练方式就是根据这些训练数据反向生成K2P网络,即从关键点到参数,以参数估计的Mean Square Error(MSE)作为损失函数进行训练。这种方法虽然直观,但是存在两个问题。
一方面,不同参数对最终游戏人脸的视觉效果的影响程度可能有很大不同。有些参数微调可能对人脸产生明显影响,有些参数即使发生较大调整可能对整体人脸的视觉效果也影响甚微。这样就造成平均的MSE Loss的训练效果不能达到满意的结果。用户需要根据具体的参数手工定义相应的权重,但是由于每个模型的骨骼或滑条的定义各不相同,因此合适的权重定义非常困难。
另一方面,如图1.16所示,之前获得的训练数据都是根据游戏的骨骼或滑条参数生成的关键点,这些关键点并不能涵盖整个关键点采样空间,而仅仅涵盖关键点全空间(图1.16右侧黄色最大椭圆区域)的一个子集(图1.16中间蓝色小椭圆区域)。由此所生成的风格化关键点,部分关键点可能在参数可生成的关键点空间内,而更多的关键点可能并不在其中。也就是说,自动捏脸系统期望生成的风格化关键点中的一部分样例在理论上不可能根据游戏端定义的骨骼或滑条参数得到。
例如,风格化关键点可能含有偏方形人脸,而游戏中限定人脸一定为椭圆形或倒三角形,那么这时无论如何改变骨骼或滑条参数都无法得到目标的风格化人脸。所以前面提到的直接训练K2P网络的方法实际上学习的目标是图1.16中间蓝色小椭圆关键点子空间到参数空间的映射,而自动捏脸系统期望学习的目标是图1.16右侧绿色小椭圆关键点空间到参数空间的映射。这就造成了训练数据与测试数据的Domain Gap,在训练时虽然可以达到很好的收敛,但是在实际的测试数据上会造成较大的关键点误差。对于图1.16右侧的风格化关键点空间,虽然可能并不存在能准确表示其中关键点的参数组合,但是,自动捏脸系统寻找到的参数生成的人脸应该尽可能接近目标关键点的坐标。

图1.16 参数空间与关键点空间示例
为了解决以上问题,本节介绍了一种自监督的机器学习方法,即关键点到控制参数训练,其过程如图1.17所示,分为两步:
第一步,训练一个P2K网络(Parameters to Keypoints)来模拟游戏参数到关键点生成的过程。
第二步,采用大量未标注的真实人脸照片,通过这些照片生成大量的风格化关键点,这些未标注的风格化关键点就是自监督学习的训练数据。对于一组关键点K,将其输入想要学习的K2P网络中,得到输出的参数P。由于这些关键点所对应的理想参数的Ground Truth无法获得,骨骼参数估计模块将P进一步输入第一步训练好的P2K网络中,得到关键点K′。通过计算K与K′的MSE Loss,模型可以对K2P网络进行学习。
需要注意的是,在第二步的过程中,P2K网络是固定不变的,并不会因为神经网络的学习而继续调整。通过P2K网络的辅助,模型将游戏客户端的控制参数到关键点这一过程使用神经网络模拟出来,这样就给第二步的K2P网络的学习打下了基础。通过这种方法,可以确保最终根据参数生成的人脸与预期生成的目标风格化人脸的关键点保持接近。同时,如果想对某些部分的关键点增加权重(如眼睛的关键点),只需要在计算K与K′的MSE Loss时调整相应的权重即可。由于关键点的定义是预定义的,并不会受到不同游戏客户端的骨骼或滑条定义变化的影响,所以调整权重比较容易。
在实际应用过程中,为了提高模型的准确率,对于可以解耦合的部分,可以采用分开训练神经网络的方式。例如,如果某些骨骼参数仅对眼睛区域的关键点有影响,并且其他参数都对眼睛区域的关键点没有影响,那么这些参数及这部分关键点就形成了一组独立的区域。如果对每一组这样的区域都训练一个单独的K2P模型,那么每个模型可以采用更加轻量级的网络设计。这样不仅可以进一步提高模型的准确率,还可以降低计算复杂度。

图1.17 关键点到控制参数训练过程
《腾讯游戏开发精粹Ⅱ》电子版已上线UWA学堂 | Unity和Unreal游戏引擎的从业者学习交流平台,感兴趣的读者可以前往阅读。
1.2.6 图像特征提取
为了美观,游戏中的人脸往往使用预定义的贴图,而不会使用真实的人脸的贴图。但是为了在保持美观的同时使得游戏中形象的贴图更加符合用户特征,很多游戏会根据用户照片中的图像特征对标准贴图进行调整。例如,如果用户肤色比多数人的平均肤色偏深,则游戏中人物的肤色会进行相应加深。
图像特征的提取一般有两种思路:基于图像处理的方式与基于监督学习的方式。前者的好处是不需要任何训练数据,可以直接分析图像中的信息,如边界、颜色、纹理等,来获取希望提取的特征,算法较为轻量;后者则需要大量的人工标注,在运行时需要载入预训练的模型,算法相对复杂,带来的好处是获取到的图像特征更为准确,对于较为复杂的问题可以处理得更好。因此,两种方式适用于不同的场景。对于准确度要求不高的特征,则基于图像处理的方式更为合适;而对于预测难度较大准确度要求较高的特征,则基于监督学习的方式更为合适。
对于游戏中的贴图调整,往往对标准的贴图进行统一修正,所以仅仅需要真实照片中的平均的颜色即可,如肤色、眉色等,这个特点决定了图像特征提取模块不需要获得非常精确的各部分颜色,只需要大体与图像颜色接近即可。因此,对于颜色提取,本节介绍的方法均采用了轻量级的基于图像处理的方式。而对于游戏中的发型修改,则需要将真实照片中的发型进行分类,划分到游戏中设定好的发型库。发型分类和眼镜检测是相对较为困难的问题,因此,1.2.7节将介绍一种基于监督学习的方式进行判断。
需要注意的是,本节提到的图像特征提取方法都假定人脸检测及关键点检测已完成,提取特征的图片为归一化大小后的人脸区域的图片(如256像素×256像素)。本节将依次介绍不同的图像特征提取方法。
1.2.6.1 平均肤色提取
为了提取图像中的特征,首先需要将图像中的人脸区域进行旋转,使得人脸左右两侧的1号与17号关键点对齐,然后需要确定肤色像素检测区域,如图1.18所示。检测区域选取眼部的最下方关键点为上边界,鼻子的最下方关键点为下边界;左右边界则选取上下边界的y坐标所对应的脸部关键点的边界。如此,得到肤色关键点区域如图1.18右侧长方形区域所示。

图1.18 肤色提取示例
图1.18右侧长方形区域中并非所有的像素都是肤色像素,可能还包含部分的睫毛、鼻孔、法令纹、头发等。因此,此区域内所有像素R、G、B值的中位数被选取作为最终预测的平均肤色。
1.2.6.2 平均眉色提取
对于眉色提取,首先选取主眉毛,即更靠近镜头的一侧眉毛作为目标。如果两侧眉毛均为主眉毛,则两侧的眉毛像素均被提取。假设左侧眉毛为主眉毛,那么如图1.19所示,77号、78号、81号、82号关键点组成的绿色四边形区域将作为眉毛像素搜索区域。这是由于靠近外侧的眉毛部分过细,小范围的关键点误差造成的影响会被放大;而靠近内侧的眉毛往往比较稀疏,与肤色的部分混合严重。因此,程序选取了中段的眉毛区域收集像素,并且每个像素都要先与平均肤色进行比较,只有区别大于一定值的像素才会被收集。最后,与肤色类似,收集像素R、G、B值的中位数作为最终的平均眉色。

图1.19 眉色提取示例
1.2.6.3 平均瞳色提取
与眉色提取类似,在提取瞳色时,首先选取靠近镜头的主眼睛。如果两个眼睛均为主眼睛,则两个眼睛的像素一起收集。眼睛的关键点所包含的封闭区域的内部除瞳孔本身外,可能还包含睫毛、眼白、反光。这些应该在像素收集的过程中尽可能去除,以保证最终得到的多数像素来自瞳孔。
为了去除睫毛像素,需要将眼睛的关键点沿y轴方向向内收缩一段距离,形成如图1.20所示的绿色折线所包含区域。为了去除眼白和反光(见图1.20中红色椭圆框区域),需要对此区域内的像素进行进一步排除。如果某个像素的亮度大于一个预定义的阈值,则将其排除。如此,收集到的像素可以保证多数来自瞳孔。同样地,采用中位数颜色作为平均瞳色。

图1.20 瞳色提取示例
1.2.6.4 平均唇色提取
对于唇色的提取,程序仅检测下嘴唇区域的像素。如图1.21所示,上嘴唇往往比较薄,对于关键点误差相对敏感,而且上嘴唇颜色较浅,无法很好地代表唇色。因此,对照片进行旋转修正后,收集所有下嘴唇关键点所包围的区域内的像素,并采用中位数颜色作为平均唇色。

图1.21 唇色提取示例
1.2.6.5 平均发色提取
发色提取相对前面几个部分而言较为困难。由于每个人的发型各不相同,照片的背景也复杂多样,如图1.22所示,所以很难定位头发的像素。如果希望准确地找到头发像素,则可以使用神经网络进行图像的头发像素分割。由于图像分割的标注代价很大,并且对于游戏应用而言不需要非常高准确度的颜色提取,因此,本节介绍一个基于关键点的大致预测的方法。

图1.22 不同发型与背景示例
为了获取头发像素,需要确定一个矩形检测区域。下边界为两侧眉脚;矩形高度为眉毛上沿到眼睛下沿的距离;左右边界为1号、17号关键点分别向左、向右扩充固定距离后得到。头发像素检测区域如图1.23中绿色矩形区域所示。

图1.23 头发像素检测区域
检测区域中一般包含皮肤、头发、背景三种类型的像素,有些更复杂的情况还会包含头饰等。因为上述检测区域左右范围相对扩充得较为保守,一般情况下可以假定包含进来的头发像素远多于背景像素。因此,程序仅将检测区域的像素划分为头发像素或皮肤像素。
一个简单的方法是根据平均肤色选取一个阈值进行皮肤像素的检测,即肤色阈值法。但是由于皮肤的颜色并不一致,靠近边缘的皮肤往往颜色较暗,所以很难选取一个合适的阈值,既排除足够多的皮肤像素,又保留足够多的头发像素,如图1.24左侧所示。第二种方法是简单的肤色、发色两类K-Means,将检测区域内的像素进行二分类。此方法对于深色头发的情况效果良好,但是对于浅色头发(如金色)则很容易与皮肤混淆。如图1.24中间所示,可以看到很多的头发像素由于颜色较浅,被错误划分为皮肤像素。因此,这里介绍第三种相对较为简单且稳定的连通区域法。

图1.24 不同的发色像素提取方法
对于每行在检测区域内的像素,可以观察到肤色的变化往往是连续的,如由亮到暗,而在皮肤与头发的交界处,肤色往往有明显的变化。因此,我们选取每行中间像素作为起始点,向左右两侧检测皮肤像素。首先使用一个相对保守的阈值找到比较可靠的皮肤像素,然后对其进行左右扩展。如果邻域像素的颜色比较接近,则也标记为皮肤像素。此方法将肤色的渐变考虑进来,可以得到相对准确的结果。如图1.24右侧所示,中间区域为皮肤像素,两侧区域多数为头发像素(绿色部分)。
1.2.6.6 平均眼影颜色提取
眼影颜色的提取与前面的部分有些不同。这是由于眼影是一个可能存在也可能不存在的部分。所以在提取眼影颜色的时候,需要首先确定眼影是否存在,如果存在,则提取其平均颜色。与眉毛和眼睛颜色提取类似,仅对靠近镜头的一侧的主眼睛、主眉毛所在的部分进行眼影颜色提取。
首先,确定哪些像素属于眼影。对于像素的检测区域,采用如图1.25所示的竖线区域,区域的左右边界分别为眼睛的内外眼角,区域的上下边界分别为眉毛的下沿和眼睛的上沿。这个区域内除可能存在眼影像素外,还可能存在睫毛、眉毛、皮肤等像素,这些像素需要在提取眼影时进行排除。

图1.25 眼影颜色提取示例
为了排除眉毛的影响,需要将检测区域的上沿进一步下移。为了减少睫毛的影响,需要将亮度低于一定阈值的像素排除。为了与肤色进行区分,程序将检查每个像素的色相(Hue)与平均肤色的差别,只有差别大于一定阈值,才将其作为可能的眼影像素进行收集。这里之所以使用色相而非RGB值,是因为平均肤色的采集主要在眼睛下方,而眼睛上方的皮肤颜色可能在亮度上会有较大变化,但是色相对于亮度的变化并不敏感,所以比较稳定,更适于判断是否是皮肤。
通过以上过程,程序可以判断每个检测区域内的像素是否属于眼影像素。眼影像素预测示例如图1.26所示,其中判断为眼影的像素被标记。可以看到,对于没有眼影的情况,仍然存在部分像素被识别为眼影,这种误差不可避免。

图1.26 眼影像素预测示例
因此,程序对检测区域每列进行判断,如果当前列的眼影像素数量大于一定阈值,则标记当前列为眼影列。如果检测区域内眼影列的数量与检测区域宽度的比例大于一定阈值,则认为当前图像中存在眼影,并将收集到的眼影的颜色中位数作为最终颜色的判断。这种方式可以将图1.26中左下的样例判断为无眼影。
1.2.6.7 颜色提取实验结果
人脸颜色特征提取结果如图1.27所示。可以看到多数的颜色提取相对较为准确,可以提供游戏人脸个性化的贴图调整。虽然瞳孔区域在图像中很小,但是依然可以提取到相对准确的颜色。但是检测结果中仍存在一些错误。例如,对于第一列和第二列,眉毛的位置与长刘海儿混淆,造成眉色提取成刘海儿部分头发的颜色;第四列的人脸带有头饰,导致发色提取成头饰的颜色;最后一列的照片由于光照,左右两侧头发颜色区别较大,因此最终提取的为未被光照影响的头发部分的颜色。

图1.27 人脸颜色特征提取结果
《腾讯游戏开发精粹Ⅱ》电子版已上线UWA学堂 | Unity和Unreal游戏引擎的从业者学习交流平台,更多精彩内容可以前往阅读。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com