sklearn库中自带数据集有几个(sklearn数据集)
sklearn数据集分为几种类型:
1、自带的小数据集(packaged dataset):sklearn.datasets.load_
2、真实世界中的数据集(Downloaded Dataset):sklearn.datasets.fetch_
3、计算机生成的数据集(Generated Dataset):sklearn.datasets.make_
4、svmlight/libsvm格式的数据集:sklearn.datasets.load_svmlight_file(...)
5、从data.org在线下载获取的数据集:sklearn.datasets.fetch_mldata(...)
1、自带的小数据集

loaders 可用来加载小的标准数据集,数据集还包含一些对DESCR描述,同时一部分也包含feature_names和target_names的特征。
1.1、波士顿房价数据集load_boston
数据地址:https://archive.ics.uci.edu/ml/machine-learning-databases/housing/
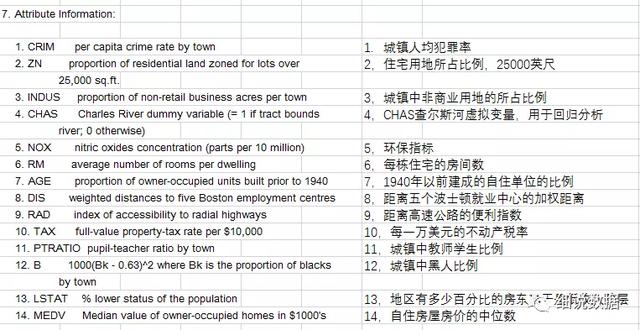
使用sklearn.datasets.load_boston即可加载相关数据。该数据集是一个回归问题。每个类的观察值数量是均等的,共有 506 个观察,13 个输入变量和1个输出变量。
每条数据包含房屋以及房屋周围的详细信息。其中包含城镇犯罪率,一氧化氮浓度,住宅平均房间数,到中心区域的加权距离以及自住房平均房价等等
from sklearn.datasets import load_boston
boston=load_boston()
boston.keys()
结果:
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
调用传给自己创建的变量boston,其实是sklearn自己设计的数据结构,整体可以理解为字典,data:数据集,target:目标值,feature_names:特征值,DESCR:描述值,filename:文件所在位置。





1.2、鸢尾花数据集load_iris
著名的 Iris数据集取自 Fisher 的论文。数据集包含 3 个类,每个类 50 个实例,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。
1.3、糖尿病数据集load_diabetes数据集一共442例糖尿病数据,10 个特征变量:年龄、性别、体重指数、平均血压和6 个血清测量值,预测基线后一年疾病进展的定量测量值。
来源网址:https : //www4.stat.ncsu.edu/~boos/var.select/diabetes.html
1.4、手写数字数据集的光学识别load_digits数据集包含1797个手写数字的图像:10 个类,其中每个类指一个数字。生成一个 8x8 的输入矩阵。来源网址:https://archive.ics.uci.edu/ml/datasets/Optical Recognition of Handwritten Digits
1.5、Linnerrud 数据集load_linnerudLinnerud 数据集是一个多元回归数据集。它由20 名中年男性收集的三个运动数据:chins、仰卧起坐、跳远和三个生理目标变量:体重、腰围、脉搏组成。
1.6、葡萄酒识别数据集load_winehttps://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data
数据一共有178行数据,特征值为酒精、苹果酸等葡萄酒的十三种检测值,预测属于三种葡萄酒中的哪一种。来源网址:
https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data
1.7、乳腺癌威斯康星(诊断)数据集load_breast_cancer数据集包含569个样本,从乳房肿块的细针抽吸(FNA)的数字化图像计算特征。它们描述了图像中存在的细胞核的30个特征:半径、纹理、周长等等。预测癌症是良性还是恶性。来源网址:https://goo.gl/U2Uwz2
2、真实世界中的数据集
2.1、Olivetti 人脸数据集
该数据集包含1992 年 4 月至 1994 年 4 月在 AT&T 剑桥实验室拍摄的一组面部图像,由40个人的400张图片构成,即每个人的人脸图片为10张。每张图片的灰度级为8位,每个像素的灰度大小位于0-255之间,每张图片大小为64×64。。
2.2、20 个新闻组文本数据集20 newsgroups数据集18000多篇新闻文章,一共涉及到20种话题,所以称作20newsgroups text dataset,分为两部分:训练集和测试集,通常用来做文本分类,均匀分为20个不同主题的新闻组集合。20newsgroups数据集是被用于文本分类、文本挖据和信息检索研究的国际标准数据集之一。
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train')
from pprint import pprint
print(list(newsgroups_train.target_names))
结果:
['alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc']
本数据集是网上收集的名人JPEG图片的集合,所有详细信息可在官网查看:http://vis-www.cs.umass.edu/lfw/
scikit-learn提供了两个加载器,它们将自动下载、缓存、解析元数据文件、解码 jpeg 并将有趣的切片转换为 memapped numpy 数组。此数据集大小超过 200 MB。第一次加载通常需要超过几分钟才能将 JPEG 文件的相关部分完全解码为 numpy 数组。。
2.4、森林覆盖类型数据集记录的是美国 Colorado 植被覆盖类型数据,也是唯一一个关心真实森林的数据。每条记录都包含很多指标描述每一块土地。例如:高度、坡度、到水的距离、树荫下的面积、土壤的类型等等。森林的覆盖类型是需要根据其他54个特征进行预测的特征。这是一个有趣的数据集,它包含分类和数值特征。总共有581012条记录。每条记录有55列,其中一列是土壤的类型,其他54列是输入特征。有七种覆盖类型,使其成为一个多类分类问题。来源网址:https://archive.ics.uci.edu/ml/datasets/Covertype
2.5、RCV1 数据集路透社语料库第一卷 (RCV1) 是一个包含超过 800,000 个手动分类的新闻专线故事的档案,由 Reuters, Ltd. 提供,用于研究目的。来源网址:https://jmlr.csail.mit.edu/papers/volume5/lewis04a/
2.6、Kddcup 99 数据集数据集是从一个模拟的美国空军局域网上采集来的9个星期的网络连接数据,分成具有标识的训练数据和未加标识的测试数据。测试数据和训练数据有着不同的概率分布,测试数据包含了一些未出现在训练数据中的攻击类型,这使得入侵检测更具有现实性。在训练数据集中包含了1种正常的标识类型normal和22种训练攻击类型。
2.7、加州住房数据集目标变量是加利福尼亚地区的房屋价值中位数。该数据集源自 1990 年美国人口普查,每个人口普查区块组使用一行。计算了各个街区群形心点之间的距离(以纬度和经度衡量),并排除了针对自变量和因变量未报告任何条目的所有街区群。最终数据包含涉及 8个特征和一个预测值,一共 20640 条观察数据。来源网址:http://lib.stat.cmu.edu/datasets/
3、计算机生成的数据集
3.1、单标签make_blobs 和 make_classification 通过分配每个类的一个或多个正态分布的点的群集创建的多类数据集。
make_blobs 对于中心和各簇的标准偏差提供了更好的控制,可用于演示聚类。
sklearn.datasets.make_blobs(n_samples=100, n_features=2, *, centers=None, cluster_std=1.0, center_box=- 10.0, 10.0, shuffle=True, random_state=None, return_centers=False)
make_classification 专门通过引入相关的,冗余的和未知的噪音特征;将高斯集群的每类复杂化;在特征空间上进行线性变换。
sklearn.datasets.samples_generator.make_classification
(n_samples=100, n_features=20, n_informative=2, n_redundant=2,
n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None,
flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0,
shuffle=True, random_state=None)
make_gaussian_quantiles 将single Gaussian cluster (单高斯簇)分成近乎相等大小的同心超球面分离。
sklearn.datasets.samples_generator.make_gaussian_quantiles
(mean=None, cov=1.0, n_samples=100, n_features=2, n_classes=3,
shuffle=True, random_state=None)
make_hastie_10_2 产生类似的二进制、10维问题。
make_circles和make_moon生成二维分类数据集时可以帮助确定算法(如质心聚类或线性分类),包括可以选择性加入高斯噪声。它们有利于可视化。make_circles生成高斯数据,带有球面决策边界以用于二进制分类,而make_moon生成两个交叉的半圆。
3.2、多标签make_multilabel_classification 生成多个标签的随机样本,
sklearn.datasets.make_multilabel_classification(n_samples=100,
n_features=20, *, n_classes=5, n_labels=2, length=50,
allow_unlabeled=True, sparse=False, return_indicator='dense',
return_distributions=False, random_state=None)
pick the number of labels: n ~ Poisson(n_labels):选取标签的数目
n times, choose a class c: c ~ Multinomial(theta) :n次,选取类别C:多项式
pick the document length: k ~ Poisson(length) :选取文档长度
k times, choose a word: w ~ Multinomial(theta_c):k次,选取一个单词
3.3、双聚类
sklearn.datasets.make_biclusters(shape, n_clusters, *,
noise=0.0, minval=10, maxval=100, shuffle=True, random_state=None)
sklearn.datasets.make_checkerboard(shape, n_clusters, *,
noise=0.0, minval=10, maxval=100, shuffle=True, random_state=None)
make_regression 产生的回归目标作为一个可选择的稀疏线性组合的具有噪声的随机的特征。
sklearn.datasets.make_regression(n_samples=100, n_features=100,
*, n_informative=10, n_targets=1, bias=0.0, effective_rank=None,
tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)
sklearn.datasets.make_s_curve(n_samples=100, *, noise=0.0,
random_state=None)
sklearn.datasets.make_swiss_roll(n_samples=100, *, noise=0.0,
random_state=None)
sklearn.datasets.make_low_rank_matrix(n_samples=100,
n_features=100, *, effective_rank=10, tail_strength=0.5, random_state=None)
sklearn.datasets.make_sparse_coded_signal(n_samples, *,
n_components, n_features, n_nonzero_coefs, random_state=None)
sklearn.datasets.make_spd_matrix(n_dim, *, random_state=None)
sklearn.datasets.make_sparse_spd_matrix(dim=1, *, alpha=0.95,
norm_diag=False, smallest_coef=0.1, largest_coef=0.9, random_state=None)
4、加载其他数据集
4.1、样本图片
scikit 在通过图片的作者共同授权下嵌入了几个样本 JPEG 图片。这些图像为了方便用户对 test algorithms (测试算法)和 pipeline on 2D data (二维数据管道)进行测试。sklearn.datasets.load_sample_images()
sklearn.datasets.load_sample_image(image_name)
4.2、svmlight或libsvm格式的数据集scikit-learn 中有加载svmlight / libsvm格式的数据集的功能函数。
svmlight / libsvm 格式的公共数据集:
https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets
更快的API兼容的实现: https://github.com/mblondel/svmlight-loader
4.3、从openml.org下载数据集openml.org是一个用于机器学习数据和实验的公共存储库,它允许每个人上传开放的数据集。在sklearn.datasets包中,可以通过sklearn.datasets.fetch_openml函数来从openml.org下载数据集.
4.4、从外部数据集加载scikit-learn使用任何存储为numpy数组或者scipy稀疏数组的数值数据。其他可以转化成数值数组的类型也可以接受,如Pandas中的DataFrame。
以下推荐一些将标准纵列形式的数据转换为scikit-learn可以使用的格式的方法:
- pandas.io 提供了从常见格式(包括 CSV、Excel、JSON 和 SQL)读取数据的工具。DataFrames 也可以从元组或字典的列表中构建。Pandas 可以流畅地处理异构数据,并提供用于操作和转换为适合 scikit-learn 的数值数组的工具。
- scipy.io 专门研究科学计算环境中常用的二进制格式,例如 .mat 和 .arff
- numpy/routines.io 用于将柱状数据标准加载到 numpy 数组中
- datasets.load_svmlight_file用于 svmlight 或 libSVM 稀疏格式的scikit-learn
- scikit-learndatasets.load_files用于文本文件的目录,其中每个目录的名称是每个类别的名称,每个目录中的每个文件对应于该类别的一个样本
对于图片、视频、音频等一些杂数据,您不妨参考:
- skimage.io或 Imageio 用于将图像和视频加载到 numpy 数组中
- scipy.io.wavfile.read 用于将 WAV 文件读入 numpy 数组
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






