初识大数据和hadoop(大数据Hadoop之Flink)
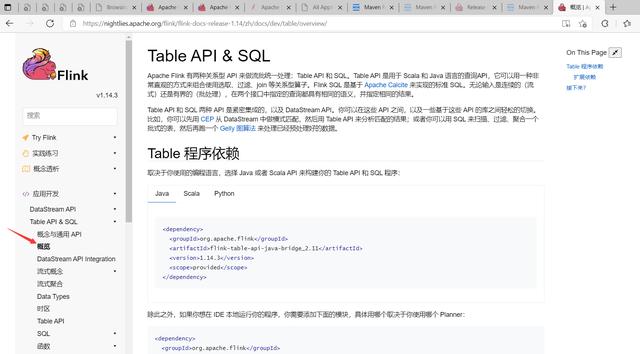
Table API 和 SQL 集成在同一套 API 中。 这套 API 的核心概念是Table,用作查询的输入和输出,这套 API 都是批处理和流处理统一的上层 API,这意味着在无边界的实时数据流和有边界的历史记录数据流上,关系型 API 会以相同的语义执行查询,并产生相同的结果。Table API 和 SQL借助了 Apache Calcite 来进行查询的解析,校验以及优化。它们可以与 DataStream 和DataSet API 无缝集成,并支持用户自定义的标量函数,聚合函数以及表值函数。
Flink官方下载:https://flink.apache.org/downloads.html官方文档(最新版本):https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/table/common/官方文档(当前最新稳定版1.14.3):https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/table/common/
maven地址:
https://search.maven.org/https://mvnrepository.com/
二、配置Table依赖(scala)首先先配置flink基础依赖
【问题提示】官方使用的2.11版本,但是我这里使用的2.12版本。
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-scala-bridge_2.12</artifactId> <version>1.14.3</version> </dependency>除此之外,如果你想在 IDE 本地运行你的程序,你需要添加下面的模块,具体用哪个取决于你使用哪个 Planner:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner_2.12</artifactId> <version>1.14.3</version> </dependency>添加扩展依赖(可选)
如果你想实现自定义格式或连接器 用于(反)序列化行或一组用户定义的函数,下面的依赖就足够了,编译出来的 jar 文件可以直接给 SQL Client 使用:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-common</artifactId> <version>1.14.3</version> </dependency>【温馨提示】如果需要本地直接运行,得先把scope先注释掉,要不然会报如下错误:Exception in thread "main" Java.lang.NoClassDefFoundError: org/apache/flink/table/api/bridge/scala/StreamTableEnvironment$
- flink-table-planner:planner 计划器,是 table API 最主要的部分,提供了运行时环境和生成程序执行计划的 planner;
- flink-table-api-scala-bridge:bridge 桥接器,主要负责 table API 和 DataStream/DataSet API的连接支持,按照语言分 java 和 scala。
- flink-table-common:当然,如果想使用用户自定义函数,或是跟 kafka 做连接,需要有一个 SQL client,这个包含在 flink-table-common 里。
【温馨提示】这里的flink-table-planner和flink-table-api-scala-bridge两个依赖,是 IDE 环境下运行需要添加的;如果是生产环境,lib 目录下默认已经有了 planner,就只需要有 bridge 就可以了。
三、两种 planner(old & blink)的区别四、Catalogs
- 批流统一:Blink 将批处理作业,视为流式处理的特殊情况。所以,blink 不支持表和DataSet 之间的转换,批处理作业将不转换为 DataSet 应用程序,而是跟流处理一样,转换为 DataStream 程序来处理。因 为 批 流 统 一 , Blink planner 也 不 支 持 BatchTableSource , 而 使 用 有 界 的StreamTableSource 代替。
- Blink planner 只支持全新的目录,不支持已弃用的 ExternalCatalog。
- 旧 planner 和 Blink planner 的 FilterableTableSource 实现不兼容。旧的 planner 会把PlannerExpressions 下推到 filterableTableSource 中,而 blink planner 则会把 Expressions 下推。
- 基于字符串的键值配置选项仅适用于 Blink planner。
- PlannerConfig 在两个 planner 中的实现不同。
- Blink planner 会将多个 sink 优化在一个 DAG 中(仅在 TableEnvironment 上受支持,而在 StreamTableEnvironment 上不受支持)。而旧 planner 的优化总是将每一个 sink 放在一个新的 DAG 中,其中所有 DAG 彼此独立。
- 旧的 planner 不支持目录统计,而 Blink planner 支持。
官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/table/catalogs/
1)Catalog概述2)Catalog 类型
- Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。
- 数据处理最关键的方面之一是管理元数据。 元数据可以是临时的,例如临时表、或者通过 TableEnvironment 注册的 UDF。 元数据也可以是持久化的,例如 Hive Metastore 中的元数据。Catalog 提供了一个统一的API,用于管理元数据,并使其可以从 Table API 和 SQL 查询语句中来访问。
- GenericInMemoryCatalog:GenericInMemoryCatalog 是基于内存实现的 Catalog,所有元数据只在 session 的生命周期内可用。
- JDBCCatalog:JdbcCatalog 使得用户可以将 Flink 通过 JDBC 协议连接到关系数据库。Postgres Catalog 和 MySQL Catalog 是目前 JDBC Catalog 仅有的两种实现。 参考 JdbcCatalog 文档 获取关于配置 JDBC catalog 的详细信息。
- HiveCatalog:HiveCatalog 有两个用途:作为原生 Flink 元数据的持久化存储,以及作为读写现有 hive 元数据的接口。 Flink 的 Hive 文档 提供了有关设置 HiveCatalog 以及访问现有 Hive 元数据的详细信息。
【温馨提示】Hive Metastore 以小写形式存储所有元数据对象名称。而 GenericInMemoryCatalog 区分大小写。
3)如何创建 Flink 表并将其注册到 Catalog1、下载flink-sql-connector-hive相关版本jar包,放在$FLINK_HOME/lib目录下
- 用户自定义 Catalog:Catalog 是可扩展的,用户可以通过实现 Catalog 接口来开发自定义 Catalog。 想要在 sql CLI 中使用自定义 Catalog,用户除了需要实现自定义的 Catalog 之外,还需要为这个 Catalog 实现对应的 CatalogFactory 接口。CatalogFactory 定义了一组属性,用于 SQL CLI 启动时配置 Catalog。 这组属性集将传递给发现服务,在该服务中,服务会尝试将属性关联到 CatalogFactory 并初始化相应的 Catalog 实例。
2、添加Maven 依赖
# 登录安装flink的机器 $ cd /opt/bigdata/Hadoop/server/flink-1.14.3/lib $ wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.11/1.14.3/flink-sql-connector-hive-3.1.2_2.11-1.14.3.jar如果您在构建自己的应用程序,则需要在 mvn 文件中添加以下依赖项。 您应该在运行时添加以上的这些依赖项,而不要在已生成的 jar 文件中去包含它们。官方文档
hive 版本
$ hive --version
Maven依赖配置如下(这里不使用最新版,使用1.14.3):使用新版,一般也不建议使用最新版,会有如下报错:
Cannot resolve org.apache.flink:flink-table-api-java-bridge_2.12:1.15-SNAPSHOT
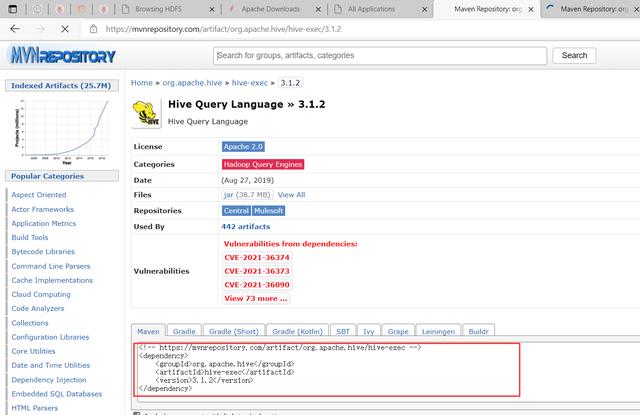
<!-- Flink Dependency --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-hive_2.12</artifactId> <version>1.14.3</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java-bridge_2.12</artifactId> <version>1.14.3</version> <scope>provided</scope> </dependency> <!-- Hive Dependency --> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>3.1.2</version> <scope>provided</scope> </dependency>还需要添加如下依赖,要不然会报如下错误:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/mapred/JobConf
version字段是hadoop版本,查看hadoop版本(hadoop version)
2、使用 SQL DDL
<!--hadoop start--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>3.3.1</version> </dependency> <!--hadoop end-->用户可以使用 DDL 通过 Table API 或者 SQL Client 在 Catalog 中创建表。
// 创建tableEnv import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment} val settings = EnvironmentSettings .newInstance() .inStreamingMode() //.inBatchMode() .build() val tableEnv = TableEnvironment.create(settings) // Create a HiveCatalog val catalog = new HiveCatalog("myhive", null, "<path_of_hive_conf>"); // Register the catalog tableEnv.registerCatalog("myhive", catalog); // Create a catalog database tableEnv.executeSql("CREATE DATABASE mydb WITH (...)"); // Create a catalog table tableEnv.executeSql("CREATE TABLE mytable (name STRING, age INT) WITH (...)"); tableEnv.listTables(); // should return the tables in current catalog and database.用户可以用编程的方式使用Java 或者 Scala 来创建 Catalog 表。
五、SQL 客户端
import org.apache.flink.table.api._ import org.apache.flink.table.catalog._ import org.apache.flink.table.catalog.hive.HiveCatalog val tableEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode()) // Create a HiveCatalog val catalog = new HiveCatalog("myhive", null, "<path_of_hive_conf>") // Register the catalog tableEnv.registerCatalog("myhive", catalog) // Create a catalog database catalog.createDatabase("mydb", new CatalogDatabaseImpl(...)) // Create a catalog table val schema = schema.newBuilder() .column("name", DataTypes.STRING()) .column("age", DataTypes.INT()) .build() tableEnv.createTable("myhive.mydb.mytable", TableDescriptor.forConnector("kafka") .schema(schema) // … .build()) val tables = catalog.listTables("mydb") // tables should contain "mytable"官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/table/sqlclient/
1)启动 SQL 客户端命令行界面SQL Client 脚本也位于 Flink 的 bin 目录中。将来,用户可以通过启动嵌入式 standalone 进程或通过连接到远程 SQL 客户端网关来启动 SQL 客户端命令行界面。目前仅支持 embedded,模式默认值embedded。可以通过以下方式启动 CLI:
$ cd $FLINK_HOME $ ./bin/sql-client.sh或者显式使用 embedded 模式:
$ ./bin/sql-client.sh embedded帮助文档
Flink SQL> HELP;2)执行 SQL 查询
这里主要讲两种模式standalone模式和yarn模式,部署环境,可以参考我之前的文章:大数据Hadoop之——实时计算流计算引擎Flink(Flink环境部署)
1、standalone模式(默认)
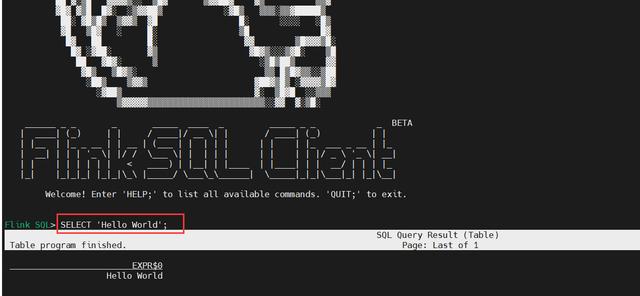
# 先启动集群 $ cd $FLINK_HOME $ ./bin/start-cluster.sh # 启动客户端 $ ./bin/sql-client.sh # SQL查询 SELECT 'Hello World';2、yarn-session模式(常驻集群)
【温馨提示】yarn-session模式其实就是在yarn上生成一个standalone集群
$ cd $FLINK_HOME $ bin/yarn-session.sh -s 2 -jm 1024 -tm 2048 -nm flink-test -d ### 参数解释: # -s 每个TaskManager 的slots 数量 # -jm 1024 表示jobmanager 1024M内存 # -tm 1024表示taskmanager 1024M内存 #-d 任务后台运行 ### 如果你不希望flink yarn client一直运行,也可以启动一个后台运行的yarn session。使用这个参数:-d 或者 --detached。在这种情况下,flink yarn client将会只提交任务到集群然后关闭自己。注意:在这种情况下,无法使用flink停止yarn session,必须使用yarn工具来停止yarn session。 # yarn application -kill $applicationId #-nm,--name YARN上为一个自定义的应用设置一个名字3、启动sql-client on yarn-session(测试验证)
$ cd $FLINK_HOME # 先把flink集群停掉 $ ./bin/stop-cluster.sh # 再启动sql客户端 $ bin/sql-client.sh embedded -s yarn-session # SQL查询 SELECT 'Hello World';3)CLI 为维护和可视化结果提供三种模式
- 表格模式(table mode)在内存中实体化结果,并将结果用规则的分页表格可视化展示出来。执行如下命令启用(默认模式):
SET 'sql-client.execution.result-mode' = 'table';
- 变更日志模式(changelog mode)不会实体化和可视化结果,而是由插入( )和撤销(-)组成的持续查询产生结果流。执行如下命令启用:
SET 'sql-client.execution.result-mode' = 'changelog';
- Tableau模式(tableau mode)更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上。具体显示的内容会取决于作业 执行模式的不同(execution.type):
SET 'sql-client.execution.result-mode' = 'tableau';你可以用如下查询来查看三种结果模式的运行情况:
4)查看帮助
SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
$ ./bin/sql-client.sh --help
SQL CLI已经演示了,这里再演示一下-f接文件的操作。
$ cat>test.sql<<EOF show databases; show tables; EOF执行
5)flink1.14.3中集成hive3.1.2(HiveCatalog )
$ bin/sql-client.sh embedded -s yarn-session -f test.sqlHiveCatalog 有两个用途:作为原生 Flink 元数据的持久化存储,以及作为读写现有 Hive 元数据的接口。 Flink 的 Hive 文档 提供了有关设置 HiveCatalog 以及访问现有 Hive 元数据的详细信息。
1、使用 Flink 提供的 Hive jar
$ cd $FLINK_HOME/lib $ wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.11/1.14.3/flink-sql-connector-hive-3.1.2_2.11-1.14.3.jar # maven网站上下载地址 $ wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-hive_2.12/1.14.3/flink-connector-hive_2.12-1.14.3.jar $ wget https://repo1.maven.org/maven2/org/apache/hive/hive-exec/3.1.2/hive-exec-3.1.2.jar $ wget https://search.maven.org/remotecontent?filepath=org/apache/thrift/libfb303/0.9.3/libfb303-0.9.3.jar $ wget https://repo1.maven.org/maven2/org/antlr/antlr-runtime/3.5.2/antlr-runtime-3.5.2.jar2、配置hive-site.xml并启动metastore服务和hiveserver2服务
【温馨提示】清楚hive metastore服务和hiveserver2服务,可以参考我之前的文章:大数据Hadoop之——数据仓库Hive
hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 所连接的 MySQL 数据库的地址,hive_remote2是数据库,程序会自动创建,自定义就行 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop-node1:3306/hive_remote2?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=Asia/Shanghai</value> </property> <!-- MySQL 驱动 --> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>MySQL JDBC driver class</description> </property> <!-- mysql连接用户 --> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>user name for connecting to mysql server</description> </property> <!-- mysql连接密码 --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> <description>password for connecting to mysql server</description> </property> <property> <name>hive.metastore.uris</name> <value>thrift://hadoop-node1:9083</value> <description>IP address (or fully-qualified domain name) and port of the metastore host</description> </property> <!-- host --> <property> <name>hive.server2.thrift.bind.host</name> <value>hadoop-node1</value> <description>Bind host on which to run the HiveServer2 Thrift service.</description> </property> <!-- hs2端口 默认是1000,为了区别,我这里不使用默认端口--> <property> <name>hive.server2.thrift.port</name> <value>11000</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>true</value> </property> </configuration>启动服务
$ cd $HIVE_HOME # hive metastore 服务 $ nohup ./bin/hive --service metastore & # hiveserver2服务 $ nohup ./bin/hiveserver2 > /dev/null 2>&1 & # 检查端口 $ ss -atnlp|grep 9083 $ ss -tanlp|grep 110003、启动flink集群(on yarn)
3、配置flink sql
$ cd $FLINK_HOME $ bin/yarn-session.sh -s 2 -jm 1024 -tm 2048 -nm flink-test -d在flink1.14 中已经移除sql-client-defaults.yml配置文件了。参考地址:https://issues.apache.org/jira/browse/FLINK-21454
于是我顺着这个issue找到了FLIP-163这个链接:https://cwiki.apache.org/confluence/display/FLINK/FLIP-163: SQL Client Improvements
也就是目前这个sql客户端还有很多bug,并且使用yaml文件和本身的命令语法会导致用户学习成本增加,所以在未来会放弃使用这个配置项,可以通过命令行模式来配置。
$ cd $FLINK_HOME $ bin/sql-client.sh embedded -s yarn-session # 显示所有catalog,databases show catalogs; show databases;创建hive catalog
CREATE CATALOG myhive WITH ( 'type' = 'hive', 'hive-conf-dir' = '/opt/bigdata/hadoop/server/apache-hive-3.1.2-bin/conf/' ); # 切换到myhive use catalog myhive; # 查看数据库 show databases; # 使用 Hive 方言(Flink 目前支持两种 SQL 方言: default 和 hive)登录hive客户端进行验证
$ cd $HIVE_HOME $ ./bin/beeline !connect jdbc:hive2://hadoop-node1:11000 show databases;六、表执行环境与表介绍1)创建表的执行环境(TableEnvironment)
TableEnvironment 是 Table API 和 SQL 的核心概念。它负责:
- 在内部的 catalog 中注册 Table
- 注册外部的 catalog
- 加载可插拔模块
- 执行 SQL 查询
- 注册自定义函数 (scalar、table 或 aggregation)
- DataStream 和 Table 之间的转换(面向 StreamTableEnvironment )
Table 总是与特定的 TableEnvironment 绑定。 不能在同一条查询中使用不同 TableEnvironment 中的表,例如,对它们进行 join 或 union 操作。 TableEnvironment 可以通过静态方法 TableEnvironment.create() 创建。
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment} val settings = EnvironmentSettings .newInstance() .inStreamingMode() //.inBatchMode() .build() val tEnv = TableEnvironment.create(settings)或者,用户可以从现有的 StreamExecutionEnvironment 创建一个 StreamTableEnvironment 与 DataStream API 互操作。
2)在 Catalog 中注册表1、表(Table)的概念
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.table.api.EnvironmentSettings import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment val env = StreamExecutionEnvironment.getExecutionEnvironment val tEnv = StreamTableEnvironment.create(env)2、临时表(Temporary Table)和永久表(Permanent Table)
- TableEnvironment 可以注册目录 Catalog,并可以基于 Catalog 注册表。它会维护一个Catalog-Table 表之间的 map。
- 表(Table)是由一个“标识符”来指定的,由 3 部分组成:Catalog 名、数据库(database)名和对象名(表名)。如果没有指定目录或数据库,就使用当前的默认值。
- 表可以是常规的(Table,表),或者虚拟的(View,视图)。常规表(Table)一般可以用来描述外部数据,比如文件、数据库表或消息队列的数据,也可以直接从 DataStream 转换而来。视图可以从现有的表中创建,通常是 table API 或者 SQL 查询的一个结果。
3、屏蔽(Shadowing)
- 表可以是临时的,并与单个 Flink 会话(session)的生命周期相关,也可以是永久的,并且在多个 Flink 会话和群集(cluster)中可见。
- 永久表需要 catalog(例如 Hive Metastore)以维护表的元数据。一旦永久表被创建,它将对任何连接到 catalog 的 Flink 会话可见且持续存在,直至被明确删除。
- 另一方面,临时表通常保存于内存中并且仅在创建它们的 Flink 会话持续期间存在。这些表对于其它会话是不可见的。它们不与任何 catalog 或者数据库绑定但可以在一个命名空间(namespace)中创建。即使它们对应的数据库被删除,临时表也不会被删除。
可以使用与已存在的永久表相同的标识符去注册临时表。临时表会屏蔽永久表,并且只要临时表存在,永久表就无法访问。所有使用该标识符的查询都将作用于临时表。
七、Table APITable API 是批处理和流处理的统一的关系型 API。Table API 的查询不需要修改代码就可以采用批输入或流输入来运行。Table API 是 SQL 语言的超集,并且是针对 Apache Flink 专门设计的。Table API 集成了 Scala,Java 和 Python 语言的 API。Table API 的查询是使用 Java,Scala 或 Python 语言嵌入的风格定义的,有诸如自动补全和语法校验的 IDE 支持,而不是像普通 SQL 一样使用字符串类型的值来指定查询。
官网文档已经很详细了,这里就不重复了:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/table/tableapi/
八、SQL本页面描述了 Flink 所支持的 SQL 语言,包括数据定义语言(Data Definition Language,DDL)、数据操纵语言(Data Manipulation Language,DML)以及查询语言。Flink 对 SQL 的支持基于实现了 SQL 标准的 Apache Calcite。
官方文档介绍的很详细,可以参考官方文档哦:概览 | Apache Flink
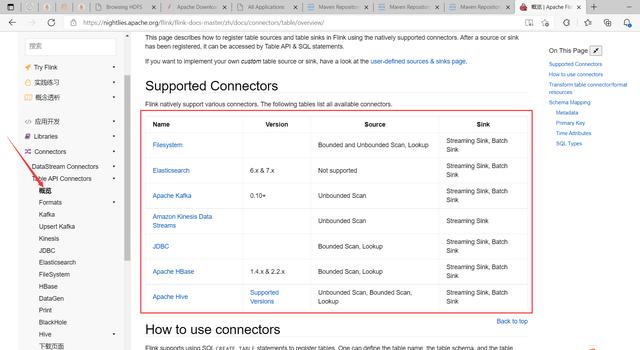
九、Table & SQL Connectors1)概述Flink的Table API&SQL程序可以连接到其他外部系统,用于读写批处理表和流式表。表源提供对存储在外部系统(如数据库、键值存储、消息队列或文件系统)中的数据的访问。表接收器向外部存储系统发送表。根据源和汇的类型,它们支持不同的格式,如CSV、Avro、Parquet或ORC。
官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/connectors/table/overview/
这里主要讲一下kafka连接器
2)Kafka安装(单机)1、下载安装包官方下载地址:http://kafka.apache.org/downloads
2、配置环境变量
$ cd /opt/bigdata/hadoop/software $ wget https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz $ tar -xvf kafka_2.13-3.1.0.tgz -C ../server/
# ~/.bashrc添加如下内容: export PATH=$PATH:/opt/bigdata/hadoop/server/kafka_2.13-3.1.0/bin加载生效
3、配置kafka
$ source ~/.bashrc
$ cd /opt/bigdata/hadoop/server/kafka_2.13-3.1.0/config $ vi server.properties #添加以下内容: broker.id=0 listeners=PLAINTEXT://hadoop-node1:9092 zookeeper.connect=hadoop-node1:2181 # 可以配置多个:zookeeper.connect=hadoop-node1:2181,hadoop-node2:2181,hadoop-node3:2181【温馨提示】其中0.0.0.0是同时监听localhost(127.0.0.1)和内网IP(例如hadoop-node2或192.168.100.105),建议改为localhost或c1或192.168.0.113。每台机的broker.id要设置一个唯一的值。
3、配置ZooKeeper新版Kafka已内置了ZooKeeper,如果没有其它大数据组件需要使用ZooKeeper的话,直接用内置的会更方便维护。
4、启动kafka
$ cd /opt/bigdata/hadoop/server/kafka_2.13-3.1.0/config $ echo 0 > /tmp/zookeeper/myid $ vi zookeeper.properties #注释掉 #maxClientCnxns=0 #设置连接参数,添加如下配置 #为zk的基本时间单元,毫秒 tickTime=2000 #Leader-Follower初始通信时限 tickTime*10 initLimit=10 #Leader-Follower同步通信时限 tickTime*5 syncLimit=5 #设置broker Id的服务地址 #hadoop-node1对应于前面在hosts里面配置的主机映射,0是broker.id, 2888是数据同步和消息传递端口,3888是选举端口 server.0=hadoop-node1:2888:3888【温馨提示】kafka启动时先启动zookeeper,再启动kafka;关闭时相反,先关闭kafka,再关闭zookeeper
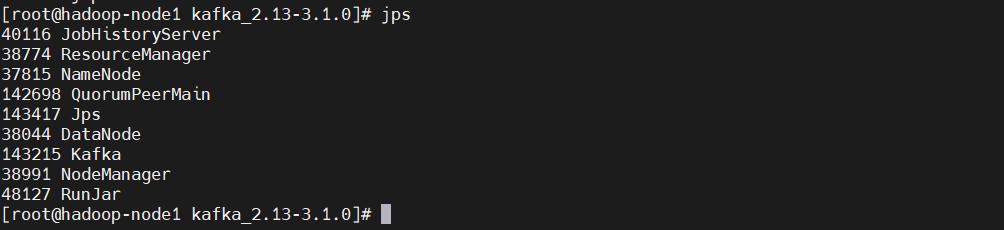
$ cd /opt/bigdata/hadoop/server/kafka_2.13-3.1.0 $ ./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties $ ./bin/kafka-server-start.sh -daemon config/server.properties $ jsp # 会看到jps、QuorumPeerMain、Kafka5、验证
#创建topic kafka-topics.sh --bootstrap-server hadoop-node1:9092 --create --topic topic1 --partitions 8 --replication-factor 1 #列出所有topic kafka-topics.sh --bootstrap-server hadoop-node1:9092 --list #列出所有topic的信息 kafka-topics.sh --bootstrap-server hadoop-node1:9092 --describe #列出指定topic的信息 kafka-topics.sh --bootstrap-server hadoop-node1:9092 --describe --topic topic1 #生产者(消息发送程序) kafka-console-producer.sh --broker-list hadoop-node1:9092 --topic topic1 #消费者(消息接收程序) kafka-console-consumer.sh --bootstrap-server hadoop-node1:9092 --topic topic1
这里只是搭建一个单机版的只为下面做实验用。
3)FormatsFlink 提供了一套与表连接器(table connector)一起使用的表格式(table format)。表格式是一种存储格式,定义了如何把二进制数据映射到表的列上。
1、JSON Format
如果是maven,则可以添加如下依赖:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-json</artifactId> <version>1.14.3</version> </dependency>这里选择直接下载jar的方式
$ cd $FLIN_HOME/lib/ $ wget https://search.maven.org/remotecontent?filepath=org/apache/flink/flink-json/1.14.3/flink-json-1.14.3.jar以下是一个利用 Kafka 以及 JSON Format 构建表的例子:
CREATE TABLE user_behavior ( user_id BIGINT, item_id BIGINT, category_id BIGINT, behavior STRING, ts TIMESTAMP(3) ) WITH ( 'connector' = 'kafka', 'topic' = 'user_behavior', 'properties.bootstrap.servers' = 'hadoop-node1:9092', 'properties.group.id' = 'testGroup', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true' )
参数解释:
json.fail-on-missing-field:当解析字段缺失时,是跳过当前字段或行,还是抛出错误失败(默认为 false,即抛出错误失败)。json.ignore-parse-errors:当解析异常时,是跳过当前字段或行,还是抛出错误失败(默认为 false,即抛出错误失败)。如果忽略字段的解析异常,则会将该字段值设置为null。
2、CSV Format
$ cd $FLIN_HOME/lib/ $ wget https://search.maven.org/remotecontent?filepath=org/apache/flink/flink-csv/1.14.3/flink-csv-1.14.3.jar以下是一个使用 Kafka 连接器和 CSV 格式创建表的示例:
CREATE TABLE user_behavior ( user_id BIGINT, item_id BIGINT, category_id BIGINT, behavior STRING, ts TIMESTAMP(3) ) WITH ( 'connector' = 'kafka', 'topic' = 'user_behavior', 'properties.bootstrap.servers' = 'hadoop-node1:9092', 'properties.group.id' = 'testGroup', 'format' = 'csv', 'csv.ignore-parse-errors' = 'true', 'csv.allow-comments' = 'true' )参数解释:
csv.ignore-parse-errors:当解析异常时,是跳过当前字段或行,还是抛出错误失败(默认为 false,即抛出错误失败)。如果忽略字段的解析异常,则会将该字段值设置为null。csv.allow-comments:是否允许忽略注释行(默认不允许),注释行以 '#' 作为起始字符。 如果允许注释行,请确保 csv.ignore-parse-errors 也开启了从而允许空行。
其它格式也类似
4)Apache Kafka SQL 连接器1、下载对应的jar包到$FLINK_HOME/lib目录下2、创建 Kafka 表
$ cd $FLIN_HOME/lib/ $ wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka_2.12/1.14.3/flink-connector-kafka_2.12-1.14.3.jar
CREATE TABLE KafkaTable ( `user_id` BIGINT, `item_id` BIGINT, `behavior` STRING, `ts` TIMESTAMP(3) METADATA FROM 'timestamp' ) WITH ( 'connector' = 'kafka', 'topic' = 'user_behavior', 'properties.bootstrap.servers' = 'hadoop-node1:9092', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv' )
参数解释:
scan.startup.mode:Kafka consumer 的启动模式。有效值为:earliest-offset,latest-offset,group-offsets,timestamp 和 specific-offsets。
group-offsets:从 Zookeeper/Kafka 中某个指定的消费组已提交的偏移量开始。earliest-offset:从可能的最早偏移量开始。latest-offset:从最末尾偏移量开始。timestamp:从用户为每个 partition 指定的时间戳开始。specific-offsets:从用户为每个 partition 指定的偏移量开始。
未完待续~
,






















免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com