随机存储器ram有什么特点(基于静态随机存储器)

导读
7月6日,后摩智能联合智东西公开课策划推出的「存算一体大算力AI芯片在线研讨会」顺利完结。东南大学电子科学与工程学院副研究员司鑫、后摩智能联合创始人&芯片研发副总裁陈亮、后摩智能联合创始人&产品推出副总裁信晓旭三位主讲人参与了本次在线研讨会并进行了主题分享。
司鑫博士以《基于静态随机存储器(SRAM)的存算电路设计》为主题进行了直播讲解。司鑫博士首先介绍了人工智能芯片的背景和挑战,之后重点讲解了存算一体和存内计算技术,以及基于存算一体的AI芯片发展和趋势。错过直播的朋友,可以点击“阅读原文”观看回放。
本文是司鑫博士的主讲回顾:
大家晚上好,我是东南大学电子科学与工程学院副研究员司鑫,非常高兴能够借助智东西公开课平台跟大家做这次分享,也非常感谢后摩智能的邀请。我分享的主题是《基于静态随机存储器(SRAM)的存算电路设计》,主要分为以下4个部分:
1、人工智能芯片的背景和挑战
2、存算一体和存内计算
3、基于存算一体的AI芯片的发展和趋势
4、总结
一、人工智能芯片的背景和挑战
提到存算一体芯片的发展,不得不提背后强有力的驱动因素:AI应用场景。通常来说AI的应用场景可以分为云、边、端三类。
对于云侧AI应用场景来说,需要在云端服务器端进行大规模的数据分析,或者是网络模型的调度与迭代;云侧AI应用对芯片的要求着重体现在低功耗、高性能两个方面。与之相对应的是在一些端侧或边缘侧的场景,它们对于算力的要求不会呈现数量齐备的爆炸性增长,但从近几年的发展趋势来看,整体也呈现出非常强有力的大算力需求。但相对来看,端侧和边缘侧更多的关注AI芯片在能效方面的提升,尤其是在无人机或一些智能终端、机器人等相关场景中。
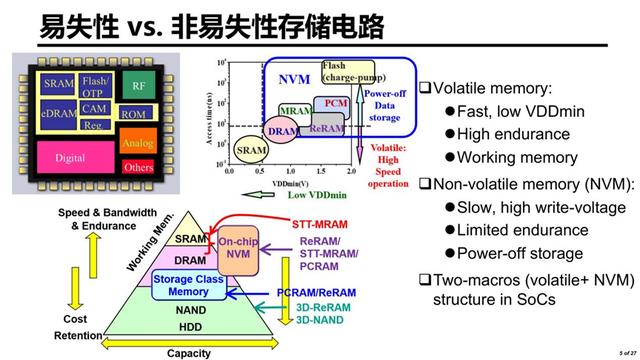
这张图展示了硬件上的存储架构设计,上图左下角是非常经典的金字塔架构图,根据性能、易失性和非易失性可以将存储器分为两个主要类别,一类是易失性存储器,以SRAM和DRAM为代表,它的操作速度快,相对的工作电压可以做到比较低的水平。好处是endurance比较高,但它具有易失性,即当电源供电断开之后,数据就会消失。
与之相对应的是非易失性存储器(Non-Volatile memory),像NAND、Flash,或者一些新型的非易失性存储器,比如RRAM、MRAM、PCM(Phase Change memory),这部分目前也是学术界研究的热点方向。它的最大优势体现在存储密度上,相比SRAM可以实现数量级别的存储密度提升。但它存在的问题是存在有限的endurance,同时需要额外一些高压的program电路的支持。
目前很多的消费类相关的SOC芯片中,大家会发现不同类别的memory,都会在整个系统当中应用到。
那么AI芯片在设计过程中可能遇到的挑战有哪些呢?
第一个挑战是功耗墙问题。比如在云端做大规模的数据读取和调度,针对这部分的功耗开销,我们做了Power分析,发现接近50%的功耗是消耗在散热的过程中,这是因为芯片要维持足够的性能,是不能够让它的热量无限增长的,需要控制芯片工作在一定的温度范围内,这部分对散热的要求相对来说更加明显。
而对于边缘侧的场景,我们比较关注两个趋势:一是电池容量的发展比例,基本上每年以7%的发展速度进行稳步的提升,但是对于AI所驱动的这部分AI任务的能量消耗来看,可以发现整个需求的增长量是巨大的,接近于60%的比例;另一个趋势从上图右边可以看出,随着年限的推进,中间的Gap也越来越大,这也意味着需要对硬件做更多能效级别的优化措施。
第二个挑战是算法需求与芯片性能不匹配。举一个比较经典的例子,从2012年到2015年短短三年间,AI算法不管是从模型的深度还是所需要执行的计算量上,都呈现出数十倍甚至百倍、千倍的增加。今年是2022年,这部分的增长比例则是更加庞大的数字。对于硬件来说,如果不对其算力密度进行优化,它的整个执行效率或性能将会卡在芯片的AI加速部分的计算单元设计上,所以也需要针对特定的AI任务部分做Hardware或Chip的支持。
第三个挑战是存储器访写功耗过大。我们可以从两方面看待这个问题:第一个是网络模型的发展趋势。网络规模基本上都是以数量级别的增长趋势在发展。但是相对以DDR接口的带宽或者能效来看,可以看到从2015年之后,整体发展速度呈现逐步放缓的阶段,原因也与大家所熟知的摩尔定律放缓有关,所以这部分也需要跟Memory的性能做独特的要求或优化。

接下来,我们从近几年ISSCC最新成果来看下当前AI芯片的发展现状。通常分成两大类评判指标,首先是从单独的、芯片级的性能benchmark,也称作Low level benchmark。例如单次operation所需要消耗的能量,以及单位时间内所能够执行的operation数量,它分别对应能效和算力两个大家所熟知的指标。
而对于System level benchmark来说,更看重的是在实际处理AI任务过程中的表现是怎样的。以AI推理应用为例,主要体现在单次influence所消耗的energy是多少,或者是单位时间内能够执行多少次的influence,比如帧率、跑分等是怎么界定的;还有一部分是针对不同的AI任务,或者数据集,整个硬件实际能够达到的效果,像inference accuracy是怎样的。
从架构来看,主要体现在三个大的发展方向。第一类是对于不同精度的支持,比如小到bit,大到各种浮点类型数据的支持,或者是相应的一些Vector扩展。还有一类是结合网络的稀疏性,也是在硬件性能提升方面研究比较多的。从原理性上有数倍甚至2~3倍以上的提升,如input、output、weight sparsity。最后一类是工艺的演进,比如3nm、5nm,还有一些3D技术,像TSV或是Hybrid Bonding等方式,来进一步提升整个AI芯片的性能。
总而言之,整个AI芯片的发展,涉及到各种不同的Software和Hardware之间的协同设计,或共同优化。

接下来用一些具体的指标数据来做一些分析。如上图所示,近几年不管是产品级的工作,或者是学术级的benchmark工作,可以看到目前绝大部分产品级的工作,它的能效都处于在个位数TOPS/W的量级,甚至是在GOPS/W的量级。
算力大小跟具体的应用场景关系比较大。比如对一些小场景,可能1TOPS就足够了,但是对于智能驾驶的场景,可能需要几百TOPS,甚至像特斯拉所标榜的1000TOPS单芯片的目标。再看下上图中上面几个处于比较特立独行的点,它们主要体现在对于精度的极致优化,或者是采用了一些新型的架构设计,包括后面会提到的存算一体架构。
二、存算一体和存内计算

在了解存算一体架构和存内计算电路的设计之前,先熟悉下传统冯诺依曼架构的局限性。
如上图所示,在传统冯诺依曼架构中,大存储单元与CPU运算单元之间是相互独立的,它们之间的交互,必须要用一些有限的BUS带宽。而对于大规模的比如AI或者是数据的一些计算处理任务来说,其实体现在硬件上,就是更长的Latency,更高的传输功耗损失,以及更高的硬件成本。
目前主流的解决的方式分为两大类,目前业界使用比较多的是High-Bandwidth Memory的开发。尤其是近一两年,更多的是一些不同于或者是超越冯诺依曼架构的新型架构的研究。

前面有提到过电池容量跟AI任务之间的发展Gap,而对于实际的硬件核心,也存在Processor性能跟Memory性能之间的Gap。原因是Memory在电路设计过程中,通常要考虑到它的良率、margin以及各种不同OCV情况下的仿真设计等,所以它的性能提升不会像基于CMOS逻辑的Processor演进速度那么快,而且这部分的Gap随着摩尔定律的发展,也在逐渐增大,这会导致什么问题呢?
在整个系统当中,我们会发现绝大部分的性能瓶颈是被卡在Memory的缓存开销中。进一部分细化到各种不同工艺节点下,会发现访存的能量开销已经超过了计算能量的开销。

上图列举了两个目前在产业界已经得到大规模应用的High-Bandwidth Memory设计方式,比如AMD或SK Hynix,采用的TSV 3D堆叠方式,可以提供更大的空间效率、更高的互连密度以及更高的传输的带宽。还有一类是从整个Memory的读写框架布局上缩短读写路径,从而节省整个访存上的功耗开销。

另外一类是存内计算设计,即存算一体架构,这部分的核心优势是扩展了Memory的功能。Memory原本是不具备任何数据处理能力的,导致做任何的事情,都需要先送给另外的处理器,处理完之后再进行处理,这之间的交互成本是非常大的。那如果自己能够做一些任务,就可以节省其他处理器的负担,整个系统也会更加和谐。所以对CIM来说,它需要执行并行的数据运算,从而节省访存开销。所以对于AI或大数据任务,它在能耗和算力密度上有更好的提升效果。
对于典型的CIM宏单元,它的核心操作就是计算,即Memory为什么能做计算,如何做计算?以我们早期的一些工作为例,主要是将数据映射到不同的行或WLs,亦或是定制的Memory cells input端口上,来进行多值的input输入。输入进来的这部分数据,可以跟cell里面的数据进行乘法,或者是布尔逻辑的运算,运算完之后通过每一列之间的bitwise的操作得到中间的一些partial sum的结果。如果是以analog形式来展现,在周边还需要相应的模数转换电路。另外还有一些可以采用数字的方式直接做相应的一些累加,有各种不同的实现路径。
上图列举了典型CIM宏单元的设计模块和整个框架。它核心的问题主要体现在三个部分:
第一点是要支持两种模式,即存储功能,要支持常规的单行数据刷新或者是读写保持,另外就是需要额外扩充它的CIM功能;
第二点主要体现在如何高效使用它的层面,如何将一些实际网络数据,像input、weight或logic values数据Mapping到阵列数据当中,这部分也涉及到各种不同的CIM结构设计;
最后一部分也是大家关注比较多的,即在实际电路实现过程当中,如何去高效的进行电路设计,这里会涉及到Analogue或者是一些混合信号的电路,还有一些高效的、定制数字单元的设计。因为Memory,尤其是存算,需要结合整个I/O,包括工艺部分的局限性,需要有非常严格的要求,尤其是在energy和area overhead上。
接下来是我们课题组早期的工作研究,梳理出来的一些挑战。早期主要体现在单bit或者是比较low precision部分的存储单元设计,它主要存在以下三个大的挑战:
第一个是inference速度会受到量化精度的影响。量化精度越高,对于inference准确度越友好,但是对于实际硬件的操作速度是不太友好的,这也是电路当中通常会讲到的词叫trade off。我们会涉及到output resolution跟 inference speed之间的trade off。
第二个是对于常规的6T based CIM单元来说,这里面的核心问题是当baseline在sum过程当中,如果电压过低,可能会导致原本存取唯一的cell发生误翻,发生误翻的话,整个cell就没有存储功能了,这是无法接受的,这也意味着从整个的设计上来看,必须要保证这部分baseline要高于read margin。这些部分也限制了在执行计算任务当中,各种不同MAC值之间的sensing circuit margin。
第三个是受到PVT Variation的影响,包括一些非线性的问题,甚至是各种不同的pattern,得到的结果可能是一样的,但是对硬件来说,其表现形式可能是不一样的,这部分也需要很多的解决思路。
针对以上三个挑战,接下来介绍下我们早期的一些工作研究。
第一个是针对全连接的网络,开展65nm 4Kb Split-6T SRAM CIM macro的设计,这也是最早一批发表在ISSCC上的工作。它的核心是把6T分成左右两个path的方式来节省计算功耗,同时针对VSA在不同的共模电压下,达到很好的offset降低的效果。我们也提出来新的VSA,最后实现了55.8TOPS/W能耗效率,这是第一个早期的对于binary CIM的探索工作。
第二个工作也是全球第一批在ISSCC上发表多值的multibit运算工作,叫做Twin-8T SRAM CIM的设计。它解决的核心问题是如何实现从单bit到多bit转化过程中的高效Mapping的问题,尤其是对于有符号数的乘加操作,我们采用了2补数的Mapping方式,再结合所定制的Twin-8T cell,可以在存内实现高效的多bit运算,同时不会造成很大面积的开销。
最近几年大家比较关注的点是High Precision CIM设计。它的Challenge比Low Precision CIM相对处于更加进阶的版本,这里也列举了三个比较核心的挑战。
第一个是要支持更高precision,对于整个senseing margin来说,呈现指数级的减少,对电路来说会更复杂。
第二个是在有着不同的area、cell variation和accuracy之间的trade off。第三部分是在执行high precision计算任务过程中,电路实现的成本,包括面积和功耗的代价,也呈现了整体的增长趋势。
为了解决这部分挑战,我们采用了局部计算单元的方式,将原本所有多值都在Analog domain中去计算,这样对于ADC的要求,或者是低bit量化电路的要求非常高。如果将它拆开,可以利用数字电路在执行时的移位以及加法部分的高效特点,同时使得这部分也具有了高精度的扩展性的特色。
我们提出Weight-bitwise MAC的操作,大家有可能会疑问Readout部分的电路,它还是在模拟域实现,如果有计算误差,是否会被数字电路所放大?这部分也有很多相关的校正电路和逻辑在里面。
三、基于存算一体的AI芯片的发展和趋势
最后针对存算一体的AI芯片做总结和发展的预测。我们统计了近几年ISSCC相关的工作,可以看到整个存算,尤其是SRAM,不管是macro level还是processor level的工作都越来越多,所支持的计算类型也越来越复杂,跟产业化的结合也越来越近。
以品质因素的发展来作为驱动,相关的参考文献都有列出,从近几年比较有代表性的工作,可以看到在支持的运算精度上,从早期的logic到BNN再到Multibit MAC;运算类型也有各种各样的类别,包括数字、模拟,模拟又可以细分为电流电荷或时域频域等等。
总的来看,SRAM存算的最大好处是工业成熟度,毫无疑问是最成熟的,它跟CMOS工艺完全匹配,同时操作速度更快,使得它更适合用于高性能、高精度以及中大算力需求的场景当中,包括智能驾驶、等一些场景。当然它也有一些劣势,包括存储密度低、设计复杂度相对较高等。
四、总结
最后,做下简单的总结。我觉得目前整个AI芯片的发展趋势大部分停留在GPU、ASIC、NPU的发展阶段,还是以冯诺依曼架构为主。但是最近这一两年有非常多的新型的架构,不管是近存,还是存内的存算一体架构的设计和研究,这部分的开发难度是要更高的,也会涉及到不同学科之间的交叉,包括算法、体系架构、编译器以及底层电路和器件的优化、协同合作。整体来看,需要产业界和学术界共同进步,来促进存算一体能够早日实现在各种实际任务上的性能优势。以上是我今天的讲解,谢谢大家。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






