英伟达cuda核心技术(英伟达全面分析)
本文为英伟达全面分析第二篇文章,聚焦英伟达的计算底座“芯片”,主要关注GPU和CUDA架构的演变,有关英伟达基础篇请参考前一篇文章,之后三篇(计算平台和软件栈)请继续关注本号更新。

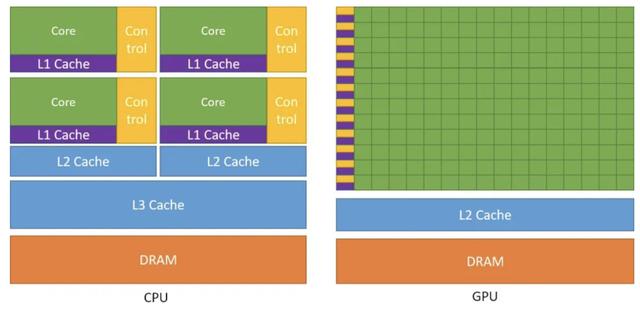
相比于CPU架构,在相同的面积上,GPU将更多的晶体管用于数值计算,取代了缓存(Cache)和流控(Flow Control),GPU的计算单元Core数量远多于CPU,但Cache和Control都要少。
如下右图GPU典型架构,每一行一个control和cache对应有多个Core,代表着同样指令在同一时刻可由多个Core执行,这样并行的设计使GPU可以并行执行几千个线程,而其内存访问的延时被计算掩盖。
英伟达GPU架构历经多次演变,从2008年的Tesla架构到2020年的Ampere架构,时间节点如下:

2010年英伟达发布的Fermi架构,是第一个完整的GPU架构。其计算核心由16个SM(Stream Multiprocesser)组成,每个SM包含2个线程束(Warp),16组加载存储单元(LD/ST)和4个特殊函数单元(SFU)组成。
最核心的是,每个线程束包含16个Cuda Core组成,每一个Cuda Core由1个浮点数单元FPU和1个逻辑运算单元ALU组成。

这个架构确立了英伟达GPU整体的发展方向,2012年的Kepler架构和2014年的Maxwell架构,都在这个基础上增加Cuda Core。
初代深度学习架构Pascal2016年的Pascal架构,英伟达开始往深度学习方向演进。
在SM内部,除了以往支持单精度的FP32 Cuda Core,还增加了支持双精度的DP Unit,而DP Unit实际上是FP64的Cuda Core。
一个SM由64个FP32 Cuda Cores和32个 FP64 Cuda Cores(DP Unit)组成,此外,FP32 Cuda Core也具备处理半精度FP16的能力,以满足当时行业开始对低精度计算的需求。

Pascal架构还引入了新的总线和通信协议NVLink,用于GPU和CPU,以及多个GPU间的连接。通过Pascal架构,英伟达GPU开始用于数据中心和超算的深度学习中。
完全深度学习架构Volta2017年的Volta架构,完全以深度学习为核心。

SM在FP64 Cuda Cores和FP32 Cuda Core基础上增加了INT32 Cuda Core,意味着可以执行INT32的操作。
更重要的是,引入了张量核Tensor Core模块,用于执行融合乘法加法。
其中两个4*4 FP16矩阵相乘,然后将结果添加到4*4 FP16或FP32矩阵中,最终输出新的4*4 FP16或FP32矩阵。

Tensor Core所做的这种运算输入矩阵的精度为半精度,但乘积可以达到完全精度,在深度学习的训练和推理中十分常见,Tensor Core的引入增加了浮点计算的吞吐量。
Tensor Core的流水线与标准算术逻辑单元ALU是一致的,更多面向的是矩阵运算,而对于单指令流多数据流标量(Scalar)运算结果不好。
在Volta架构中,一个SM由8个FP64 Cuda Cores,16个INT32 Cuda Core,16个FP32 Cuda Core,和128个Tensor Core组成,一共有4个SM,算力相比于Pascal架构快了5倍。
在Volta基础上,2018年英伟达发布Turing架构,对Tensor Core进行了升级,增加了对INT8、INT4、Binary(INT1)的计算能力,性能依次翻倍。
此外,在架构配备了RT Core(专用光线追踪处理器),能够高速对光线和声音进行渲染。
2020年发布Ampere 架构,对Tensor Core又进行了升级,增加了TF32和BF16两种数据格式的支持,也增加了对稀疏矩阵计算的支持。

CUDA(Compute Unified Device Architecture),是2006年英伟达为了解决GPU编程的复杂度问题推出的通用并行计算平台。
CUDA本质上有两层含义,第一层是硬件平台,即在多线程的设计GPU上跑通用并行计算;
GPU平台上的向量运算由CUDA Core承担(FP32/FP64),GPU平台上的低精度浮点运算(FP16、INT8)由Tensor Core 承担。
第二层含义是CUDA代表着软件栈,即一堆软件的集合,包括了设备驱动和SDK。

在CUDA软件栈基础上,向上抽象和扩展了CUDA-X,对接不同的行业应用需求,分为面向AI计算的CUDA-X AI和面向HPC计算的CUDA-X HPC。
此外依托于CUDA软件栈进行第三方应用及工具的扩展,形成了广义的CUDA生态。
从CUDA满足易部署(用户开箱即用)、层次灵活的开发接口(OpenCL、OpenGL类似的一种API)、满足不同领域开发者编程语言(Fortran, C/C , Python)、品类齐全的工具集(GDB、Nsight、Memcheck等)、第三方工具和软件库(和用户及厂商并肩,构筑软件生态城)。
汽车人参考小结从GPU架构的演变历史,在Cuda基础上衍生出的生态产业,英伟达可以说是十年磨一剑,每一代架构都会根据需求进行快速迭代。
GPU和CUDA两翼双飞,已被从业者视为深度学习的标配,进一步奠定了GPU做加速计算全球龙头地位。
本文为汽车人参考第381篇原创文章,如果您觉得文章不错,“推荐和关注”是对我最大的支持。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com