阿里达摩院人机交互(揭秘阿里达摩院)
【CSDN 编者按】已经换个江湖的马老师说过,达摩院活得要比阿里巴巴长。关注达摩院的开发者朋友应该有所了解,达摩院是面向未来探索未知的研究院,研究领域主要分为 5 个方面,本文作者 —— 阿里巴巴达摩院研究员付强博士就来自其中非常重要的机器智能方面的语音实验室,他有着 20 多年的语音信号处理研究和应用开发经验。
在「CSDN 在线峰会 —— 阿里云核心技术竞争力」上,付强博士深入分享了面向 AIoT 的智能语音交互技术及实践,本文为演讲精华整理。
复制链接或点击「阅读原文」可免费观看付强博士分享视频:
https://edu.csdn.net/course/play/28249/388356

演讲 | 付强,阿里巴巴达摩院研究员
责编 | 唐小引
头图 | CSDN 下载自东方 IC
出品 | CSDN(ID:CSDNnews)

走近阿里达摩院
阿里巴巴达摩院成立于 2017 年,致力于探索科技未知,以人类愿景为驱动力的立足于基础科学、创新性技术和应用技术。达摩院秉承着“Research for solving problems with profit and fun”的宗旨,意在“以科技,创新世界”。
达摩院的研究领域
阿里达摩院分布于中国、美国、以色列以及新加坡等,主要包括了 5 大研究领域,即机器智能、数据计算、机器人、金融科技以及 X 实验室。其中语音实验室属于机器智能方向。

机器智能技术实验室的研究方向
机器智能技术实验室的研究方向包括了语音、语义、视觉以及运筹优化等,面向的领域包括了政府、交通、农业、传媒、工业、新零售等场景。

语音实验室在整个达摩院的学术领域还是具有一定地位的,2019 年力压海外巨头突破人机对话难题,获得了 DSTC7 国际大赛双料冠军。也是在 2019 年,阿里巴巴语音 AI 入选了“2019 年的全球十大突破性技术”。
达摩院语音方案的技术优势,可以分为以下 6 点来介绍:
-
过硬的技术能力:达摩院拥有全栈的技术链条以及世界领先的技术能力。
-
基础能力免费:基础语音能力免费提供等政策。
-
更灵活的解决方案:分层服务的差异化策略和基于不同厂商不同能力的定制输出。
-
阿里生态和服务:阿里巴巴集团提供的庞大生态。
-
丰富的量产经验:软硬件设计、多设备量产经验。
-
服务客户的能力:迅速接入、全链路定制以及持续迭代和 BI 等能力。
NUI 端云一体平台架构
语音交互主要包括了语音分离/增强、识别、理解、合成、对话等。达摩院有一套称之为 NUI(Natural User Interface)的端云一体化平台架构,基于阿里的生态提供内容和服务,支持了淘系、支付宝等应用。NUI 通过自然交互的方式为人提供信息、操控设备或者完成其他任务的产品形态。

面向智能硬件的端云一体语音技术能力
细化到语音相关技术能力,可以分为基本功能和高阶功能。基本能力包括 ASR:近场 远场语音识别、TTS:语音合成、WWV:本地远场唤醒、信号处理:抗噪 AEC 回声抵消、远场 2/4 MIC 模组方案;高阶技术则属于达摩院自主研发的独有专利技术,包括了方言、快捷命令词、唤醒词定制、基于声纹的个性化推荐、基于盲分离的语音增强、10 多个领域的对话理解功能以及即时热词功能等。

同时,还对阿里的生态资源进行整合调用,包括了阿里系的本地、生活、出行、旅游、智能、家居、购物、娱乐等方向。

远场语音交互技术
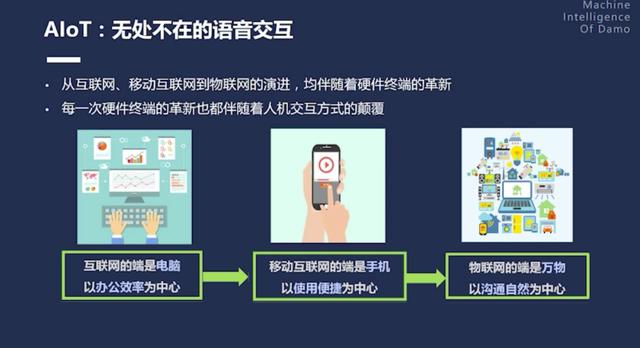
AIoT 时代,语音交互无处不在。从互联网到移动互联网演进的过程,均伴随着硬件终端的革新,而每一次革新其实都伴随着人际交互方式的颠覆。从最早的互联网时代,电脑为办公效率带来了一次革新;在移动互联网时代,重点的端是手机,以使用便捷为中心;在物联网时代,端是万物,这个时候以沟通自然为中心,因此自然语音交互会起到非常重要的作用。
智能设备类语音交互技术链路长
语音交互的技术链条非常长,从硬件侧的电路设计、声学结构到音频链路的排查、连接,再到云上语音识别服务的调优、对话理解领域模型,再到 TTS 合成,整个链条非常的长。
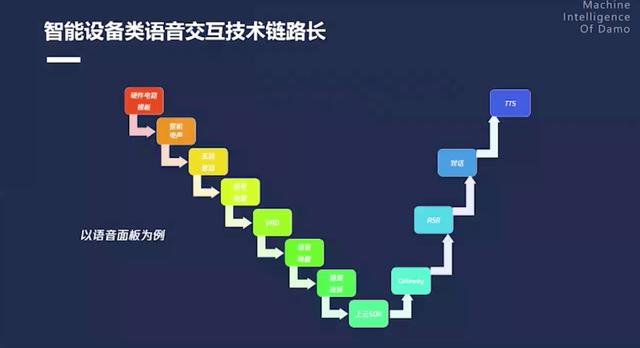
因此在这么多年的语音交互技术的发展过程中,具有全栈技术链条能力的服务商角色越发重要。接下来介绍阿里达摩院在智能设备类语音交互技术链条中的技术积累。
基于盲源分离的远场前端处理统一框架
如前面所提到的,与客户设备端紧密相连的技术就是信号处理。针对于终端侧面向各种各样的声学噪声环境,达摩院拥有独有的基于盲源分离的远场信号处理统一框架。

所谓盲源分离,就是基于处于“盲源”的假设,不对信号或者传播路径做过多的先验要求。它只有一个独立性假设,就是不同源的信号相互独立,通过最大化输出之间的独立性实现分离。
此外,还实现了统一框架,将回声、混响、点声源干扰看做独立信号,并使用盲源分离技术来并来统一来处理,这里面包含的技术有双讲模型、集成学习以及信号处理和唤醒联合优化,这些都是阿里在多年实践中总结沉淀下来的业界领先技术。
前端信号处理技术方案
下图展示了达摩院提供的几种前端信号处理技术方案,包括 2 个麦克风、4 个麦克风以及 8 个麦克风的,分别对应了不同的场景。前两个方案更多适用于电视、车载等场景;最后一个则适用于公共空间、地铁售票机、商业大屏等场景。

唤醒技术
在唤醒技术方面,达摩院语音实验室可以提供芯·端·云一体的唤醒体验,具有极低的误唤醒率;嵌入到芯片的低功耗唤醒能力;本地设备 AP 上的唤醒模块等,并且提供了端云一体的唤醒机制。
免唤醒技术
达摩院的免唤醒技术提供了 Oneshot 语音识别、快捷唤醒词技术、动态唤醒词技术以及连续对话等。

语音识别/语音识别自定制能力
语音识别方面,达摩院拥有领先的声学模型技术,比如 DFSMN 受到了全世界和开源社区的好评,包括谷歌和微软等也在跟进。除此之外,在语言模型技术方面,达摩院还有单遍大规模语言模型解码技术,并且对于领域语言模型有不同的定制,可以解决不同行业和领域的识别准确率问题,能够做到分钟级生效。
语音合成
近两年,达摩院在语音合成技术方面取得了长足的进步,自然度在逐步提升,同时具有超低成本的定制方案,仅需要 2 小时的语音数据就能够提供 TTS 定制方案。

声纹技术
阿里远场的声纹技术是目前工业界率先实施的远场声纹技术,比如天猫精灵音箱的身份认定等。与此同时,达摩院还提供隐式的声纹画像技术。

自然语言理解
达摩院在自然语言理解这部分在过去两年的时间里,支持了常见电视领域的 NLU 理解能力,属于基于规则和统计的混合系统,并且支持客户数据的联合深度优化。

多模态融合技术
所谓多模态就是音频和视频的融合,过往音视频融合的过往经验都是停留在比较浅层的叠加,但是达摩院的多模态融合技术除了能够提供人脸识别、人脸检测、属性之外,能够把基于视频的属性特征利用于声学层面的语音增强,这样才能达到公共空间高噪声场景下的语音交互。

模组方案介绍
声学硬件模组化
声学模组是对语音交互端侧的核心链路,包括音视频软硬件链路、端侧引擎和上云协议的封装。声学硬件模组化能够实现产品方案平台化,与硬件相关的技术和经验被沉淀,提升与客户对接效率,降低对人力和时间成本的要求;在软硬件层面均可做二次开发。

面向 AIoT 的语音交互端云一体引擎(NUI-Things)
NUI-Things 引擎是面向低资源的语音引擎,在底层有 AliOS/YoC 这样面向多端的物联网操作系统进行支撑,语音部分包括了端点检测、回声消除、语音增强等前端处理模块,还包括了语音唤醒、本地语音识别以及本地语义理解。通过 NLS 的语音交互服务协议上云,云端则有阿里语音 AI 云平台、IoT 飞燕平台以及相应的内容资源池。

拾音模组-适配智能电视、投影仪等

Linux 语音模组
语音模组将语音引擎内置到硬件模块之中;多模态的语音模组,将音视频技术沉淀到模组之中。下图中的 Linux 语音模式早在 2018 年就已经成熟了,目前已经应用于消费级的语音面板和售卖机等场景,支持 2 至 8 麦克风的高性能前端处理算法,360 度拾音,端云一体高性能语音唤醒,并且支持“主控模式”和“下位机”模式等。

RTOS 语音模组
在 2019 年的时候,达摩院语音实验室重点发展了 RTOS 的语音模组。面向广泛的家电、电工照明、故事机等场景,符合业界的期待,即在低成本和低功耗的条件下达到高体验。RTOS 语音模组基于多核异构架构,能够支持高性能 2 到 4 个麦克风的前端处理算法,360 度拾音,端云一体语音唤醒,支持离线语音识别和快速响应,并且支持低功耗待机语音唤醒,以及“主控模式”和“下位机”模式。
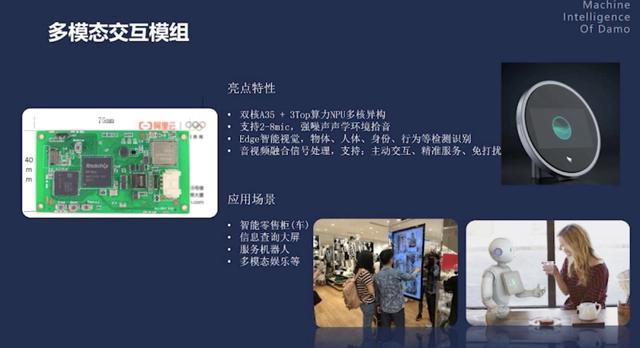
多模态交互模组
多模态交互模组更多地应用于智能零售柜、信息查询大屏、服务机器人、多模态娱乐等场景,其具有 NPU 多核异构架构,支持 2 至 8 麦克风,强噪声声学环境拾音,具有对于物体、人体、行为、身份等检测识别能力。
达摩院在提供模组级或者芯片级方案的同时,还提供了声学硬件研发、质量控制服务体系。从模组期间选型到整机性能,从研发性能到产线质量控制,从国际标准测试环境到自研测试软硬件系统的全方位闭环,除此之外,还提供平台化的声学和 PCB 设计服务。
演讲嘉宾简介:付强博士,阿里巴巴达摩院机器智能技术实验室研究员。曾是中国科学院声学所的研究员,具有 20 余年语音信号处理研究和应用开发经历,在包括 IEEE Trans.等国内外权威学术刊物及会议上发表论文近百篇,发明专利 10 余项,主持制订 1 项语音国家标准。主持和参与包括国家自然科技基金国家和省部委在内的几十项科研课题,其中多项成果在相关部委列装。在智能车载、电视、音箱远场语音和多模交互技术和方案领域均做出过业界开创性的工作。付强博士带领的团队在国际语音分离和识别挑战赛 CHiME3、4 中均取得过前端信号处理环节的较好成绩。2014 年获中国科学院杰出科技成就奖,2016 年获中国语音产业联盟先进个人。
系列阅读:
黑客“借刀杀人”,阿里 14 年经验安全大佬教你如何防御 DDoS 攻击!
一群阿里人如何用 10 年自研洛神云网络平台?技术架构演进全揭秘!

☞朱广权李佳琦直播掉线,1.2 亿人在线等
☞“抗疫”新战术:世卫组织联合IBM、甲骨文、微软构建了一个开放数据的区块链项目!
☞快速搭建对话机器人,就用这一招!
☞据说,这是当代极客们的【技术风向标】...
☞iPhone 12系列旗舰有望分批发布;美威胁吊销中国电信在美经营许可,外交部发言人回应;VS Code新版发布| 极客头条
今日福利:评论区留言入选,可获得价值299元的「2020 AI开发者万人大会」在线直播门票一张。 快来动动手指,写下你想说的话吧。
果断“在看”一下!
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






