验证码识别属于人工智能吗(验证码识别技术)
摘要
“在互联网上,没人知道你是一条狗。”——网络谚语
“我会回来的。”——电影《终结者》系列
随着春运的临近,购买火车票又成了不少人关注的事情。由于近年来中国铁路把重点放在了网络售票上,中国铁路总公司的售票网站12306是多数人首选的购票网站,它也成为了“黄牛党”试图破解的关键网站。
因此,不难理解,当12306网站提高网站验证码的难度之后,许多人开始抱怨。就在这几天,关于12306网站的“奇葩”验证码的新闻传遍了整个网上,甚至已经被外媒报道。
12306网站的验证码真的是奇葩吗?有评论认为,12306设置这样的验证码是为了为难用户而不是服务用户。这样的指责真的成立吗?
要回答这个问题,我们首先要弄清楚设置验证码究竟是为了什么。
有一句网络谚语“在互联网上,没人知道你是一条狗”。这句谚语通常被理解为强调用户在互联网上的匿名性——没人知道在网络另一端坐着的究竟是什么人。把这句谚语延伸一点,就变成了“在互联网上,没人知道你是一个计算机程序”。事实上,自动化的计算机程序(它们被称为bot)是互联网的组成部分。例如,各大搜索引擎都有各自的自动化程序在网上收集各种信息,这种自动化节省了大量的人力。
但是自动化程序带来的也未必都是便利。有人也会用自动化程序做坏事。例如,别有用心的人可以编写自动化程序伪装成网络用户,在各大交互式网络上滥发广告。具体到12306的例子,我们知道,“黄牛党”的目的是比你更快地抢购到车票,如果他们编写了自动化的程序登录12306网站购票,那么你是根本无法和高速运转的计算机程序对抗的——它们实在太快了。如果彻底取消验证码,那么对于一般用户,可能更难购买到车票。
你可能已经意识到了这个问题的关键:有没有一种方法能把网络那一端的人类用户和自动化的程序区分开来?是的,这就是验证码的作用。这类验证机制有一个名字:CAPTCHA,即“区分计算机与人类的完全自动化大众图灵测试”。
图灵测试是20世纪50年代由英国数学家阿兰•图灵提出的。这个测试是让人测试一个不可见的相对者,从行为上判断对方是人还是机器,目的是检验一台机器是否具有等同于人类的智能。简单地说,图灵测试就是“人类判断对方是人还是机器”。
而CAPTCHA的本质是一种逆向的图灵测试,在这种测试中,是让机器判断一个不可见的相对者(例如,一个互联网上的用户)是人类还是自动化的程序。当90年代互联网开始走向大众的时候,对互联网的滥用也变得越来越多。如何制止不友好的网络自动程序的行为,成为了一个需要解决的问题。“验证码”就是CAPTCHA的具体化的产物:当你需要登录某个网站的时候,你首先需要输入登录页面上显示的一个图片上的字符。如果输入正确,系统就认为你是人类而不是程序,于是允许你进行下一步的操作。
军备竞赛
验证码能起作用的大前提是人类可以轻松地识别验证码,而机器却不能。然而,实际情况要比这复杂得多。很显然,一个只能解读网页的HTML编码的程序对图片方式显示的验证码束手无策。但是简单的验证码也只能挡住简单的程序。光学字符识别(OCR)技术在很早以前就出现了,而且性能越来越好(如果80年代的时候OCR技术已经成熟,在《回到未来第二部》里可能就不会出现条形码号牌的汽车)。如果一个攻击者使用OCR程序自动识别验证码,那么这种CAPTCHA就被攻破了。
事实上,当最早的发明者研究验证码技术的时候,他们已经考虑到了这种情况。有趣的是,他们从扫描仪的说明书中“逆向”获得了灵感:如果说明书指出了应该避免哪些妨碍OCR识别的低劣图像,他们就如法炮制把验证码图像劣化。
这样有效吗?有效。但是这就像一场军备竞赛。验证码的攻击者也在提高识别技术的能力。于是,我们在这些年看到字符型验证码不断复杂化,从最早的规矩的字符,到不断复杂的图像底纹,字符变得更加扭曲、粘连。这导致了人类识别验证码所需的时间也在增加。根据不同的估计,如今每天人类花在识别网页验证码上的时间已经超过了几十万小时。
这是多么惊人的浪费。在网络机器人横行的背景下,在进行图灵测试的同时,还能坚持自由和人道主义的原则吗?这真是一件可悲的事情。为了回收利用这种被浪费的时间,卡内基•梅隆大学的Luis von Ahn等人几年前提出了一个称为reCAPTCHA的系统。2008年,他们在《科学》杂志上发表了这一成功,2009年,该发明被谷歌收购。
reCAPTCHA的运作方式是非常巧妙的,它被设计成既用于区分人类和机器,又用于帮助文献的数字化。首先,对那些信息时代之前出版的需要数字化的文献进行OCR处理,用两种OCR程序识别同一篇文献,挑出那些两种OCR程序识别存在差异的疑难词作为reCAPTCHA的测试词。然后,还要附加一个已知的对照词。用户需要同时输入测试词和对照词才能完成reCAPTCHA。如果用户输入对了对照词,那么系统就认为用户也有很大可能性输入对了测试词(用户不知道网页上显示的哪个词是对照词)。当多个用户对同一个测试词的输入都一致的情况下,系统就认为这个疑难的测试词被用户“校对”了。下一步,这个被校对过的测试词会被用于reCAPTCHA测试的对照词。
reCAPTCHA的巧妙之处就在于,首先,被用于该测试的词都是OCR程序不太擅长识别的,这样就给攻击者带来了一定的麻烦。其次,该测试并没有减少用户花在验证码上的时间,而是借用了用户的力量用于校对OCR处理过的文献。谷歌就是使用reCAPTCHA对纽约时报报纸数字化工程进行了校对。
但是即使是reCAPTCHA也避免不了被破解的命运。自从reCAPTCHA上线以来,已经有研究人员多次报告实现了对谷歌的reCAPTCHA的攻击,其成功率各不相同。谷歌也“与时俱进”地多次升级reCAPTCHA,让它的字符变得更加难以辨认——对人类和机器都是如此。事实上,早就有人抱怨谷歌的验证码让人类用户也难以识别。
验证码变得人类也难以识别,这其实是很正常的现象,因为这说明了人工智能技术在不断进步,当你在识别一个验证码的时候感到困难,你实际上已经游走在了人工智能与人类智能较量的战场前沿上。
除了字符型验证码,研究人员还提出了其他类型的验证码。例如,一种验证码是在字符型验证码的基础上附加了问题。但是,这只不过是给攻击者暂时增加了难度。例如,一个过于简单的问题(验证码:2+4=?)只要简单升级攻击算法就能破解(12306网站也采用过这种验证码)。而过于困难的问题却又不符合“大众测试”的目的。很显然,一个类似于“博士的座右铭是什么”的验证问题能阻挡大多数程序,但是由于这个问题比较小众,也会让许多人类用户感到困惑。而且,随着人工智能技术的不断进步,机器可能会比人类更擅长回答诸如此类的自然语言问题——还记得参加美国知识竞赛Jeopardy!(国内通常译为《危险边缘》)的计算机系统“沃森”吗?
另一种类型的验证码是让用户识图。这种验证码是建立在图像识别比字符识别更困难的前提上的。有多个研究组提出过类似的方案,例如,几年前微软的研究人员提出的一种方案是,为用户随机提供一组动物的照片,让用户在其中选出所有的猫或者所有的狗(其前提是假定机器不擅长区分猫狗)。你可能已经意识到了,这恰恰类似于12306的图形验证码的。其实,12306的图形验证码大致是可行的,它遭人垢病的方面主要有两个,一个是可能超出了用户的知识范围(让用户选出没有接触过的物品,例如,调色板),另一个是它的图像过于模糊,以至于人类用户也无法识别。其实第二个问题是很微妙的:如果图像太清晰,人工智能程序也可能轻易地识别。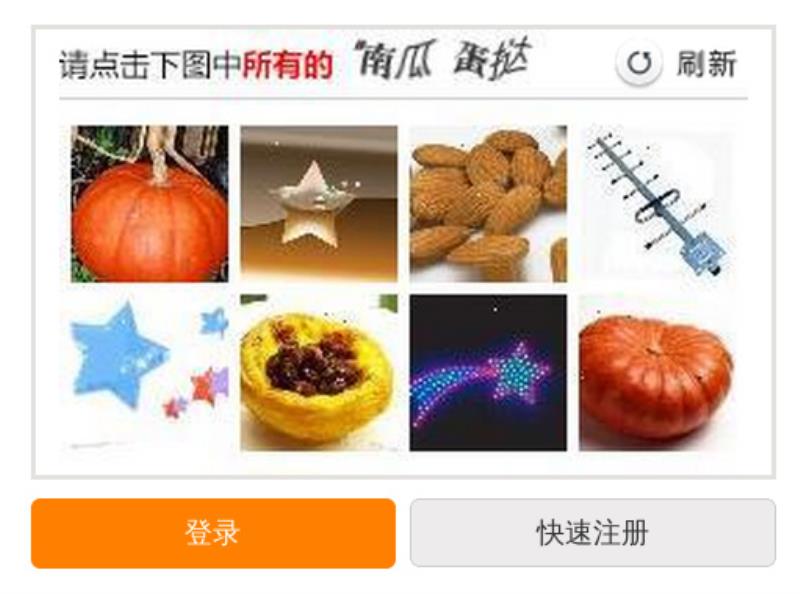
终极的方法是“人肉”识别。既然CAPTCHA的目的是区分人类和机器。如果组织一大批人,让他们专门负责识别验证码,这样就从根本上绕过了CAPTCHA。在特定情况下,这确实是可以实现的。
可以这样说,设计一种CAPTCHA就是提出一个人工智能领域的难题。而CAPTCHA的攻击者就是在解决一个人工智能领域的难题。随着人工智能研究的不断进步,在神经网络、机器学习等技术的帮助下,计算机肯定会更加擅长识别验证码,或许,有朝一日它们会比你更擅长。这听上去似乎是矛盾的:你究竟应当期待验证码有效,还是应当期待验证码被攻破(也就意味着人工智能研究的突破)?
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com