大数据技术flink(大数据Flink数据处理)


1.并行计算不同的任务,分配到不同的线程上就可以并行计算了
2.然后并行任务,现在我们知道,如果我们设置的并行度是3,那么这里需要的slot就是3个对吧
这个跟任务的最大并行度有关
3.然后就是我们写的一串代码,到底包含几个任务呢?每个算子包含几个任务了呢?
这个也需要解释.


然后我们再来看什么是并行度,可以看到一个任务,有几个子任务就有几个并行度,实际上就是
看一个任务是被拆成了几个任务来处理对吧.
可以看到上面source,这里,分成了2个子任务对吧,分别是source1,source2,两个子任务,并行度就是2了,然后再看map,这里两个map,那么并行度也是2,这两个map会分配到不同的slot上去执行.
然后再看整条流他的并行度是什么呢?注意,整条流的并行度,可以看到,就是在这个数据流图的过程中,他的拥有最多子任务的,那个任务的并行度,也就是,并行度最大的那个任务的,并行度,就是整个数据流图的并行度.


然后我们接着看,可以看到上面,每个taskmanager,都是一个jvm的进程,这里注意是进程,而每个slot拥有独立的内存,但是他不拥有独立的cpu对吧,因为cpu是需要时间片轮转的,然后而每个在taskmanager中的slot,都相当于,taskmanager这个进程中的一个单独的线程对吧.
而为了不让时间片轮转,所以我们给一个taskmanager设置slot的个数的时候,我们一般是
cpu有几核就设置几个slot对吧,这样,这个taskmanager中的slot就可以,每个slot独占一个cpu核心
实现并行处理了.
并且可以看到,一个slot中,也就是一个taskmanager进程中的一个线程中,可以执行,多个子任务对吧,就是这两个子任务,时间片轮转执行呗对吧.


然后我们再看,上面这个数据流图中,实际上一共有几个子任务,可以看到有7个对吧,
2个source,2个map,两个keyby,window,apply操作,然后1个sink对吧,7个子任务
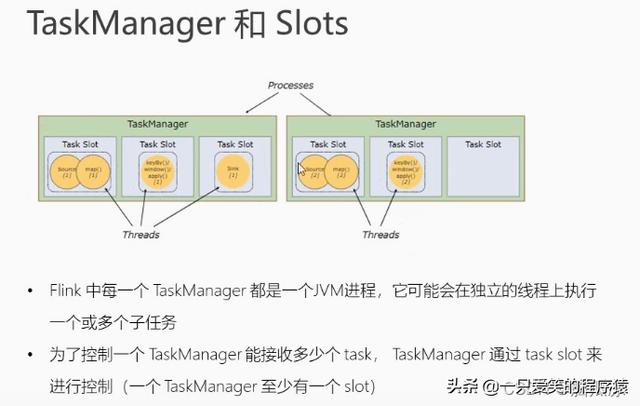

所以也就是说,上面的数据流图,实际上有7个子任务,如果每个任务用一个slot来执行的话需要7个slot对吧,但实际上运行的时候,他需要7个slot来执行吗?
不需要对吧,实际上只需要2个对吧,因为这里,分割以后最大的是2对吧,source分割以后是2,map分割以后也是2...我们说slot数,只需要满足分割子任务最多的那个就可以运行了.
因为同一个任务的子任务不能放到同一个线程中执行,因为如果放到同一个线程执行一个任务的,不同子任务,那么就不再是并行执行了对吧.


然后我们再看,上面这个,这里有几个slot?
现在我们把slot给分开了:
我们source分了6个对吧,map也是分了6个,然后keyby,window,apply这个我们分了6个,然后
sink1,所以这里我们有19个slot,也就是19个任务对吧.


但是实际上我们只需要6个slot就可以开始运行了对吧,因为我们最多的把一个任务是分成了6个slot 对吧.
然后我们再看,实际上,一个,slot中可以包含,保存作业的整个管道什么意思?
就是一个slot中可以包含整个作业的流程,可以看到:
最左边,这个slot中包含了,source,map 然后和 keyby,window,apply 然后sink,这个就是所有的,这个流程中的任务都包含了对吧,这样有什么好处呢?
这样的话,如果其他的taskmanager,蹦了,那么他也可以在这个slot中慢慢执行完所有任务对吧,这是其一,然后,还有就是所有流程都在这一个slot中,这样减少了,不同slot之间的交互性能高.这样的话整个运行过程中的健壮性和性能都会得到提升.


可以看到,默认情况下,flink允许子任务共享slot,也就是说,一个taskmanager中,slot要尽可能的共享,就是一个slot中包含所有的任务,这样才符合健壮性以及性能比较好.


那么可以看到,上面的这种一条线排开的情况就很不合理了对吧,因为没有准守上面的共享原则,
而且还有一种情况就是,如果是上面这样分配的话,比如上面左边的slot,source和map这两个任务,
他们的计算要求比较低所以耗cpu也不多,但是中间那个keyby,window开窗操作,耗cpu很高对吧,这样就导致,第一个slot很闲,第二个slot很忙对吧,这样也不好,而如果根据共享任务的原则如果source,map,keyby,windows,sink都在一个slot中了,如果一个简单的,比如source,map执行完了,他还可以直接进行keyby的操作,就不会有忙的忙死,闲的闲死的情况了.
所以上面那样分配slot,健壮性不好,然后性能也不好,那么这样的话在实际的应用中,会出现这样的情况嘛?
可以出现这种情况对吧?但是需要我们代码中规定,指定哪个任务要在一个slot里面,也就是在一个共享组里.


比如上面,这个分组实际上也是我们可以规定的,而且每个子任务也可以规定一个分组对吧,
可以看到上面我们给sum这个任务指定了并行度,我们还可以给他指定一个分组.slotSharingGroup("red")对吧,是红组,这里的red是个字符串,自己随便写,给分组起了个名字.


然后我们再给flatMap操作,这个设置一个slotSharingGroup是green绿组


然后我们如果不设置分组呢?
如果不给一个任务设置分组,比如上面的这个source,读取的这个,我们没有设置分组,那么他就会
使用默认的那个default这个分组了.


然后我们再看,这个resultStream.print().setParallelism(1)
这里我们也没有指定分组对吧,他是什么组呢?
注意如果没有指定他跟上一个分组在一个组里,就是红组对吧red组.


然后现在我们有几个slot呢?我们代码分组以后?
我们再编译一个jar包,然后上传到后台,然后看一下执行计划


我们上传以后,然后我们点开这个上传的,代码中修改了分组的这个jar包


然后我们再写上参数,这里写上
com.atguigu.wc.StreamWordCount
然后--host localhost --post 7777
然后直接点击show plan 去看执行计划


可以看到,有几个?slot?4个对吧? ,然后我们再点击提交


然后我们再去看看,没有执行成功对吧


我们去看看这个overview这里,有4个可用的slot啊?
怎么没有执行?


去看看日志,发现是因为我们的netcat没有启动对吧


我们启动一下,然后再去看


这个时候我们直接点击submit提交.


然后这个时候就可以看到执行了对吧.


然后我们看,他这个slot是怎么算的?
1.source操作这个读取文件的操作,是default这个分组的
2.然后flatMap这个是绿组的,我们自己起的
3..sum这个计算操作是红组的,然后最后print 那个没有指定分组,但是和最近的是一个分组.
之前我们说他的slot的占用个数是,几个任务中的最大并行度对吧,但是现在呢?
现在他是这样算的,获取每个分组中的最大的并行度,然后加起来,
可以看到上面1分组的并行度是1,任务是1对吧,2分组绿组的并行度也是1,然后3分组可以看到也就是红组,包含了sum,keyby这个任务的并行度是2对吧,然后还包含了一个任务print的并行度是1,这之间最大的并行度是2对吧,所以这个时候并行度就取2,所以这里,最终需要的slot就变成了.
1 1 2=4对吧.
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






