吴恩达深度学习笔记16(吴恩达老师课程笔记系列第)
第 29节 -逻辑回归之高级优化 (5)
参考视频:6-6-Advanced Optimization (14 min).mkv
在上一个视频中,我们讨论了用梯度下降的方法最小化逻辑回归中代价函数J(θ)。在本次视频中,我会教你们一些高级优化算法和一些高级的优化概念,利用这些方法,我们就能够使通过梯度下降,进行逻辑回归的速度大大提高,而这也将使算法更加适合解决大型的机器学习问题,比如,我们有数目庞大的特征量。
现在我们换个角度来看什么是梯度下降,我们有个代价函数J(θ),而我们想要使其最小化,那么我们需要做的是编写代码,当输入参数θ时,它们会计算出两样东西:J(θ)以及J等于0、1直到n时的偏导数项。

假设我们已经完成了可以实现这两件事的代码,那么梯度下降所做的就是反复执行这些更新。
另一种考虑梯度下降的思路是:我们需要写出代码来计算 J(θ) 和这些偏导数,然后把这些插入到梯度下降中,然后它就可以为我们最小化这个函数。
对于梯度下降来说,我认为从技术上讲,你实际并不需要编写代码来计算代价函数 J(θ)。你只需要编写代码来计算导数项,但是,如果你希望代码还要能够监控这些 J(θ) 的收敛性,
那么我们就需要自己编写代码来计算代价函数 J(θ)和偏导数项
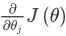
所以,在写完能够计算这两者的代码之后,我们就可以使用梯度下降。
然而梯度下降并不是我们可以使用的唯一算法,还有其他一些算法,更高级、更复杂。
如果我们能用这些方法来计算代价函数 J(θ)和偏导数项

两个项的话,那么这些算法就是为我们优化代价函数的不同方法,共轭梯度法 BFGS (变尺度法) 和L-BFGS (限制变尺度法) 就是其中一些更高级的优化算法,它们需要有一种方法来计算 J(θ),以及需要一种方法计算导数项,然后使用比梯度下降更复杂的算法来最小化代价函数。这三种算法的具体细节超出了本门课程的范畴。实际上你最后通常会花费很多天,或几周时间研究这些算法,你可以专门学一门课来提高数值计算能力,不过让我来告诉你他们的一些特性:
这三种算法有许多优点:
一个是使用这其中任何一个算法,你通常不需要手动选择学习率 α,所以对于这些算法的一种思路是,给出计算导数项和代价函数的方法,你可以认为算法有一个智能的内部循环, 而且,事实上,他们确实有一个智能的内部循环,称为线性搜索(line search)算法,它可以自动尝试不同的学习速率 α,并自动选择一个好的学习速率 α,因此它甚至可以为每次迭代选择不同的学习速率,那么你就不需要自己选择。这些算法实际上在做更复杂的事情,而不仅仅是选择一个好的学习率,所以它们往往最终收敛得远远快于梯度下降,这些算法实际上在做更复杂的事情,不仅仅是选择一个好的学习速率,所以它们往往最终比梯度下降收敛得快多了,不过关于它们到底做什么的详细讨论,已经超过了本门课程的范围。
实际上,我过去使用这些算法已经很长一段时间了,也许超过十年了,使用得相当频繁, 而直到几年前我才真正搞清楚共轭梯度法 BFGS 和 L-BFGS 的细节。
我们实际上完全有可能成功使用这些算法,并应用于许多不同的学习问题,而不需要真正理解这些算法的内环间在做什么,如果说这些算法有缺点的话,那么我想说主要缺点是它们比梯度下降法复杂多了,特别是你最好不要使用 L-BGFS、 BFGS 这些算法,除非你是数值计算方面的专家。实际上,我不会建议你们编写自己的代码来计算数据的平方根,或者计算逆矩阵,因为对于这些算法,我还是会建议你直接使用一个软件库,比如说,要求一个平方根,我们所能做的就是调用一些别人已经写好用来计算数字平方根的函数。幸运的是现在我们有 Octave 和与它密切相关的 MATLAB 语言可以使用。
Octave 有一个非常理想的库用于实现这些先进的优化算法,所以,如果你直接调用它自带的库,你就能得到不错的结果。我必须指出这些算法实现得好或不好是有区别的,因此, 如果你正在你的机器学习程序中使用一种不同的语言,比如如果你正在使用 C、C 、Java 等等,你可能会想尝试一些不同的库,以确保你找到一个能很好实现这些算法的库。因为在
L-BFGS 或者等高线梯度的实现上,表现得好与不太好是有差别的,因此现在让我们来说明:如何使用这些算法:

比方说,你有一个含两个参数的问题,这两个参数是 θ0 和θ1,因此,通过这个代价函数,你可以得到 θ1 和 θ2 的值,如果你将 J(θ) 最小化的话,那么它的最小值将是 θ1=5,θ2=5。
代价函数J(θ)的导数推出来就是这两个表达式:

如果我们不知道最小值,但你想要代价函数找到这个最小值,是用比如梯度下降这些算法,但最好是用比它更高级的算法,你要做的就是运行一个像这样的Octave 函数:
function [jVal, gradient]=costFunction(theta) jVal=(theta(1)-5)^2 (theta(2)-5)^2; gradient=zeros(2,1); gradient(1)=2*(theta(1)-5); gradient(2)=2*(theta(2)-5); end
这样就计算出这个代价函数,函数返回的第二个值是梯度值,梯度值应该是一个2×1的向量,梯度向量的两个元素对应这里的两个偏导数项,运行这个costFunction 函数后,你就可以调用高级的优化函数,这个函数叫 fminunc,它表示Octave 里无约束最小化函数。调用它的方式如下:
options=optimset('GradObj','on','MaxIter',100); initialTheta=zeros(2,1); [optTheta, functionVal, exitFlag]=fminunc(@costFunction, initialTheta, options);
你要设置几个 options,这个 options 变量作为一个数据结构可以存储你想要的 options, 所以 GradObj 和 On,这里设置梯度目标参数为打开(on),这意味着你现在确实要给这个算法提供一个梯度,然后设置最大迭代次数,比方说 100,我们给出一个 θ 的猜测初始值,它 是一个 2×1 的向量,那么这个命令就调用 fminunc,这个@符号表示指向我们刚刚定义的costFunction 函数的指针。如果你调用它,它就会使用众多高级优化算法中的一个,当然你也可以把它当成梯度下降,只不过它能自动选择学习速率 α,你不需要自己来做。然后它会尝试使用这些高级的优化算法,就像加强版的梯度下降法,为你找到最佳的θ 值。
让我告诉你它在 Octave 里什么样:

所以我写了这个关于 theta 的 costFunction 函数,它计算出代价函数 jval 以及梯度 gradient,gradient 有两个元素,是代价函数对于 theta(1) 和 theta(2) 这两个参数的偏导数。我希望你们从这个幻灯片中学到的主要内容是:写一个函数,它能返回代价函数值、梯
度值,因此要把这个应用到逻辑回归,或者甚至线性回归中,你也可以把这些优化算法用于线性回归,你需要做的就是输入合适的代码来计算这里的这些东西。
现在你已经知道如何使用这些高级的优化算法,有了这些算法,你就可以使用一个复杂的优化库,它让算法使用起来更模糊一点。因此也许稍微有点难调试,不过由于这些算法的运行速度通常远远超过梯度下降。
所以当我有一个很大的机器学习问题时,我会选择这些高级算法,而不是梯度下降。有了这些概念,你就应该能将逻辑回归和线性回归应用于更大的问题中,这就是高级优化的概念。
在下一节中,我想要告诉你如何修改你已经知道的逻辑回归算法,然后使它在多类别分类问题中也能正常运行。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






