ai目标检测算法(腾讯AILab现场陈述论文)
腾讯 AI Lab 共有 12 篇论文入选在美国新奥尔良举行的国际人工智能领域顶级学术会议 AAAI 2018。腾讯技术工程官方号独家编译了论文《训练 L1 稀疏模型的象限性消极下降算法》(Training L1-Regularized Models with Orthant-Wise Passive Descent Algorithms),该论文被 AAAI 2018 录用为现场陈述论文 (Oral Presentation),由腾讯 AI Lab 独立完成,王倪剑桥为论文唯一作者。
论文地址:https://arxiv.org/abs/1704.07987
中文概要
L1 范数正则模型是一种常用的高维数据的分析方法。对于现代大规模互联网数据上的该模型,研究其优化算法可以提高其收敛速度,进而在有限时间内显著其模型准确率,或者降低对服务器资源的依赖。经典的随机梯度下降 (SGD) 虽然可以适用于神经网络等多种模型,但对于 L1 范数不可导性并不适用。
在本文中,我们提出了一种新的随机优化方法,随机象限性消极下降算法 (OPDA)。本算法的出发点是 L1 范数函数在任何一个象限内是连续可导的,因此,模型的参数在每一次更新之后被投影到上一次迭代时所在的象限。我们使用随机方差缩减梯度 (SVRG) 方法产生梯度方向,并结合伪牛顿法 (Quasi-Newton) 来使用损失函数的二阶信息。我们提出了一种新的象限投影方法,使得该算法收敛于一个更加稀疏的最优点。我们在理论上证明了,在强凸和光滑的损失函数上,该算法可以线性收敛。在 RCV1 等典型稀疏数据集上,我们测试了不同参数下 L1/L2 范数约束 Logistic 回归下该算法性能,其结果显著超越了已有的线性收敛算法 Proximal-SVRG,并且在卷积神经网络 (CNN) 的实验上超越 Proximal-SGD 等算法,证明了该算法在凸函数和非凸函数上均有很好的表现。
引言:学习稀疏表征一直都是一个非常重要的数据分析任务。比如说,在生物学领域,为了对单个个体进行基因分析,常常涉及到数百万个基因,然而其中真正对某任务,比如帮助预测某种稀有癌症,有用的基因片段并不多。在金融序列预测和网络广告等领域,也有很多数据数量甚至比数据维度还小的情况。这本身是一个病态 (ill-condition) 的问题,然而如果对解有一个稀疏先验的话,问题则是可解的。通信领域的压缩感知中的核心部分也是如何高效求解稀疏模型。目前,这些方法包括 Lasso (Robert Tibshirani), Dantzig Selector (Emmanuel Candes, Terrence Tao), OMP (Joel A. Tropp, Tong Zhang), FoBa (Tong Zhang) 等。
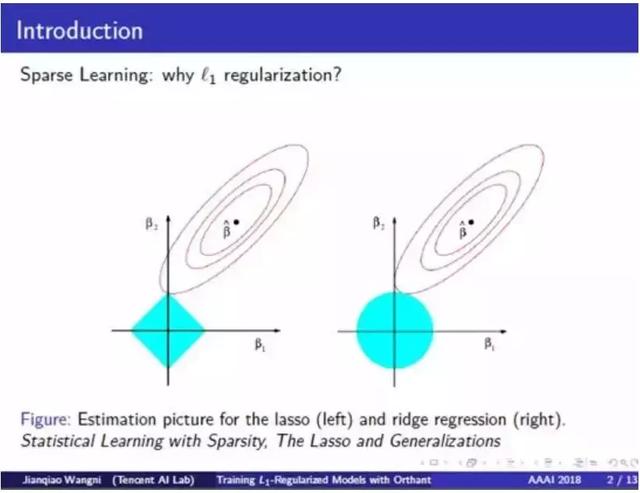
首先,我们给一个直观的例子,为什么 L1 范数正则项(绝对值的和)适用于求解稀疏模型。下图中,蓝色区域是约束内的可行解区域,左边是 L1 范数球(norm ball),右边是 L2 范数球,红色圈是均方损失函数(average-of-square-loss)的等高线。这些球和等高线之间的交点是模型的解。我们可以看到 L1 正则化模型的解接近 Y 轴,这意味着其 X 维元素更接近于 0。这是一个简单的例子,可以看出来 L1 正则项比 L2 正则项更适合于学习稀疏模型。
我们可以把大部分问题统一为最小化一个正则化函数 P(x)= F(x) R(x),其中 F(x) 是 N 个损失函数的平均,其中每个都依赖于一个数据样本,R 是 L1 正则项。我们还假设每个损失函数都满足二次可导 (twice differentiable)、强凸 (strongly-convex) 和光滑 (smooth)。由于该 L1 范数是不可导的(在零点),目前最通用的优化方法是近端方法 (proximal method),通过迭代式地采取梯度下降步骤,然后在当前点上优化一个 proximal 问题。
相关文献介绍:我们的主要参考方法是象限性伪牛顿法 (OWL-QN: Galen Andrew, Jianfeng Gao),这种方法基于 L-BFGS (Jorge Nocedal),一种最常用的伪牛顿法。该方法 OWL-QN 将更新后的参数限制在一个特定的象限内,因为在每个单个象限中,其绝对值函数实际上是可微分的。OWL-QN 的一个关键创新点与在零点的次梯度 (subgradient) 有关。这里 L1 正则项 R(x) 的次梯度既可以是正λ,也可以是负 λ,那么如何选择次梯度会影响收敛速度。以下面大括号内第三个分支为例:我们研究的是当前点 X 的第 i 维 X_i,和梯度 V_i。如果 X_i 等于 0 且 X_i 加上 λ 为负,那么该次梯度就设为 V_i 加上正 λ,因为在减去这个次梯度之后,X_i 将会是一个正值,那么 R(x) 的次梯度将仍然为正 λ,这会使 L1 范数的次梯度在一次迭代中保持一致。
为了处理大规模互联网数据,研究者提出了很多用于加速训练过程的优化方法,比如随机梯度下降法 (SGD)。但是,SGD 通常需要衰减步长才能收敛,而且它的收敛率是次线性的 (sublinear)。近期出现了 SVRG (Rie Johnson, Tong Zhang) 和 SAGA (Aaron Defazio, Francis Bach) 等一些随机方差缩减方法,可以无需降低步长就能收敛,而且可以在光滑和强凸的模型上实现线性收敛率 (linear convergence rate)。在 SGD 方法中,第 k 步的下降方向 v_k 是在该数据集的一个随机子集 S_k 上进行评估的。在 SVRG 方法中,我们需要周期性地在一些参考点(比如 tilde-X)上计算一个准确梯度。这个准确梯度构成了 SVRG 的 v_k 的第三项,然后我们必须通过在 tilde-X 上减去一个随机梯度(这是在同一子集 S_k 上计算的)来平衡它的期望。
受 SVRG 和 OWL-QN 的启发,我们开发了一种针对 L1 正则化模型的随机优化方法。在第一步时,我们计算损失函数 F(x) 的 SVRG,然后我们使用来自 OWL-QN 的思想来计算一个参考方向,尽量使下降方向以在一次迭代后维持同一个象限。而我们的实际下降方向 V_k 是用这里的第三个等式计算的。
现在我们可以计算解前进的方向了。我们可以通过计算当前点上的 Hessian 矩阵或估计近似的 Hessian 矩阵(伪牛顿法)来使用该损失函数的二阶信息,从而加速其收敛。然后我们可以通过在当前点附近的 Taylor 二次展开来计算最优下降方向 D_k。如果我们使用 L-BFGS,我们可以绕开耗时的矩阵求逆运算,只通过快速的矩阵向量乘法就可以做到。我们也可以直接将 V_k 分配给 D_k,这样就是一个典型的一阶方法。在这个步骤之后,方向 D_k 的象限必须与参考方向保持一致,这意味着:如果 D_k 的某些维度与参考方向的符号不同,它们就必须被分配为 0,我们将这个对齐后的版本记为 P_k。
除了对齐参考,上述计算梯度并没有涉及到 L1 正则化 R(x) 的偏导数,因为我们要避免对随机梯度的引入额外方差。为了使解是稀疏的,我们提出了一种全新的对齐算子来激励零元素。这个算子作用在 X,Y 两个元素上,如果 X 和 Y 符号不同或 X 的绝对值小于一个阈值,就强制 X 为零。通过这个对齐算子,每次在我们完成了之前的计算之后,我们就检查下一个点是否与当前点在同一个象限,如果不在,下一个点的某些维度就会被强制为零。在这一步之后,显然 X_k 的更多维度应该为零,而不是绝对值很小的非零值。
收敛性分析:在这篇论文中,我们证明在平滑性和强凸性的假设下,我们的方法将以一个线性速率收敛。
为了进行可视化,我们在这张图中绘制了在一个简单的二维合成函数的优化轨迹。我们的方法 OPDA 用红线标识,作为基准的 Proximal-Gradient Descent 算法用蓝线标识。在迭代了同样多次数之后,我们看到 OPDA 用更快的速度收敛到了等高线中更低的区域。
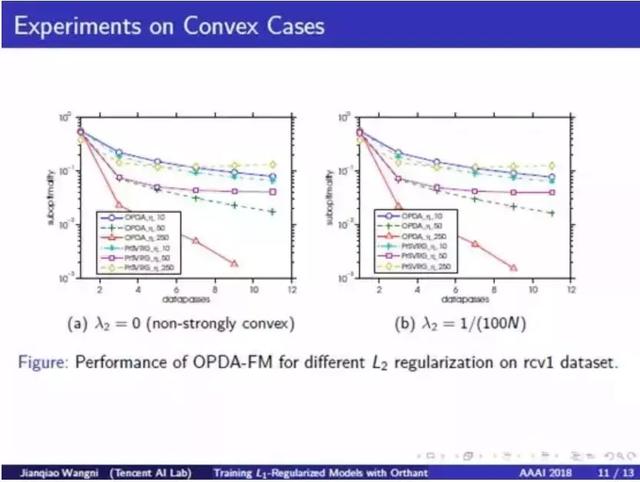
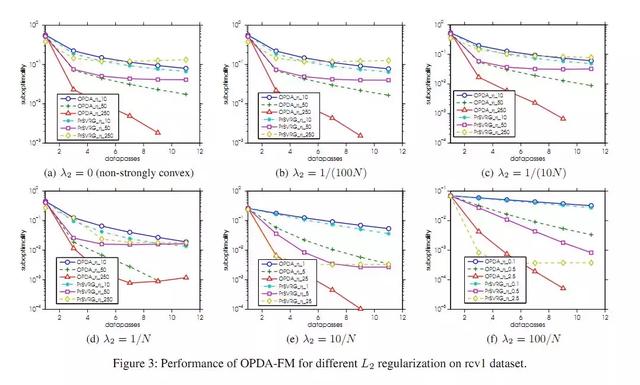
在凸函数上的实验:我们还使用 L2/L1 regularized Logistic 回归上进行了一些实验。在这一部分,我们将我们的方法与一个线性收敛算法 Prox-SVRG (Lin Xiao, Tong Zhang) 进行了比较。在这张图中,Y 轴表示解的次优性 (suboptimality),即当前目标函数与最小值之间的间隔;X 轴表示完整扫过数据集的次数。我们发现使用不同的步长以及 L2 和 L1 正则化系数时,OPDA 的速度稳定地超越了 Prox-SVRG 算法。
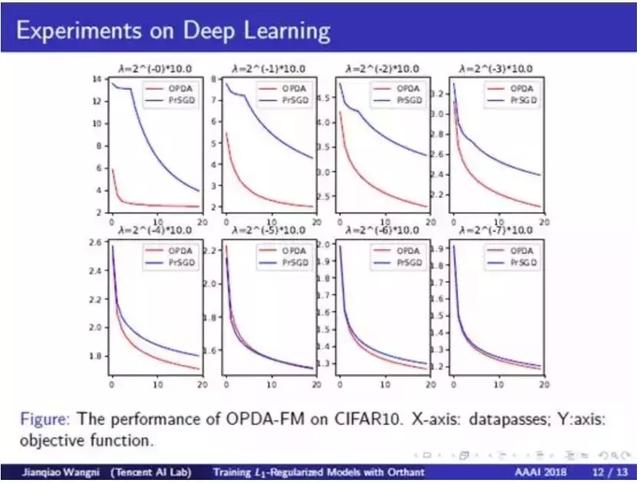
在深度学习上的实验:我们使用 L1 正则化稀疏卷积神经网络 (sparse-CNN) 进行了实验,以表明我们的方法在非凸函数的有效性。下图中红线表示我们的方法,蓝线表示近端 SVRG。我们测试了不同规模的 L1 正则化。我们看到 OPDA 收敛速度比近 Prox-SGD 更快。而且在 L1 正则项更强的情况下,这种差异更大。
总结:我们提出的 OPDA 算法可以适用于快速优化 L1 正则的稀疏模型。实际上,由于我们的方法的象限性本质,下降方向和更新后的点的许多维度都会在对齐过程中被强制变为零,这会使等效步长变小很多;但是,在同等步长条件下,我们方法的速度仍然远远快于近端方法。这证明我们提出的对齐算子确实能将方向调校得更好,使其整体框架更为有效,而且在每次迭代中所需额外运算量接近可以忽略不计。
,









免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






