自动化运维管理平台的设计(自动化运维之日志统一管理)
一、日志收集及告警项目背景
近来安全测试项目较少,想着把安全设备、nginx日志收集起来并告警, 话不多说,直接说重点,搭建背景:
1. 日志源:安全设备日志(Imperva WAF、绿盟WAF、paloalto防火墙)、nginx日志等;2. 日志分析开源软件:ELK,告警插件:Sentinl 或elastalert,告警方式:钉钉和邮件;3. 安全设备日志->logstash->es,nginx日志由于其他部门已有一份(flume->kafka)我们通过kafka->logstash->es再输出一份,其中logstash的正则过滤规则需要配置正确,不然比较消耗性能,建议写之前使用grokdebug先测试好再放入配置文件;4. 搭建系统:centos 7 , JDK 1.8, Python 2.75. ELK统一版本为5.5.2由于es和kibana的安装都比较简单,就不在下文中说明安装及配置方法了。相关软件的下载链接如下:
Es:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.2.tar.gz
Kibana: https://artifacts.elastic.co/downloads/kibana/kibana-5.5.2-linux-x86_64.tar.gz
Logstash: https://artifacts.elastic.co/downloads/logstash/logstash-5.5.2.tar.gz
测试链接Grokdebug:http://grokdebug.herokuapp.com
二、安全设备日志收集
2.1 Imperva WAF配置
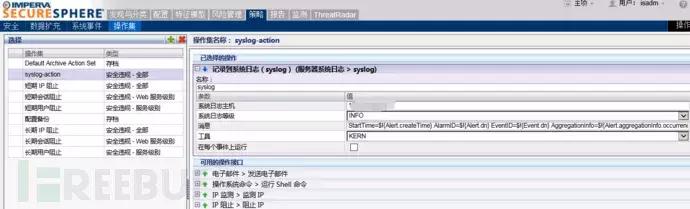
策略->操作集->新增日志告警规则
我这边没有用设备自身的一些日志规则,而是根据手册自定义了一些需要的日志字段,可在自定义策略的消息填入如下字段:
StartTime=$!{Alert.createTime}AlarmID=$!{Alert.dn} EventID=$!{Event.dn} AggregationInfo=$!{Alert.aggregationInfo.occurrences}Alert_level=$!{Alert.severity} RuleName=$!{Alert.alertMetadata.alertName} Category=$!{Alert.alertType} Alert_description=$!{Alert.description}EventType=$!{Event.eventType} PolicyName=$!{Rule.parent.displayName}SrcIP=$!{Event.sourceInfo.sourceIp} SrcPort=$!{Event.sourceInfo.sourcePort}Proto=$!{Event.sourceInfo.ipProtocol} DstIP=$!{Event.destInfo.serverIp}DstPort=$!{Event.destInfo.serverPort} WebMethod=$!{Event.struct.httpRequest.url.method}Domain=$!{Alert.serverGroupName} URL=$!{Event.struct.httpRequest.url.path}ResponseCode=$!{Event.struct.httpResponse.responseCode}Alert_key=$!{Event.struct.httpRequest.url.queryString}Action=$!{Alert.immediateAction} ResponseTime=$!{Event.struct.responseTime}ResponseSize=$!{Event.struct.responseSize} Headers_value=$!{Event.struct.httpRequest.headers.value}Parameters_value=$!{Event.struct.httpRequest.parameters.value}
参数说明:告警开始时间、告警ID、事件ID、事情数量、告警级别…. HTTP返回码、触发告警字符串、响应动作、响应时间、响应大小、http包头的值,中间省略的部分请自行查看手册。其实Imperva WAF的总日志字段数不少于一两百个,单从这一点可以看出确实好于国产WAF太多。
针对Imperva WAF的logstash配置如下:
input{ syslog{ type => "syslog" port => 514 } } filter { grok { match =>["message","%{GREEDYDATA:StartTime} AlarmID=%{NUMBER:AlarmID} EventID=%{NUMBER:EventID}AggregationInfo=%{NUMBER:AggregationInfo} Alert_level=%{DATA:Alert_level}RuleName=%{GREEDYDATA:RuleName} Category=%{GREEDYDATA:Category}Alert_description=%{GREEDYDATA:Alert_description} EventType=%{DATA:EventType}PolicyName=%{GREEDYDATA:PolicyName} SrcIP=%{IPV4:SrcIP} SrcPort=%{NUMBER:SrcPort}Proto=%{DATA:Proto} DstIP=%{IPV4:DstIP} DstPort=%{NUMBER:DstPort}WebMethod=%{GREEDYDATA:WebMethod} Domain=%{DATA:Domain}URL=%{GREEDYDATA:URL} ResponseCode=%{GREEDYDATA:ResponseCode}Alert_key=%{GREEDYDATA:Alert_key} Action=%{DATA:Action}ResponseTime=%{GREEDYDATA:ResponseTime} ResponseSize=%{GREEDYDATA:ResponseSize}Headers_value=%{GREEDYDATA:Headers_value}Parameters_value=%{GREEDYDATA:Parameters_value}"] # 实际复制粘贴可能会有点格式问题,注意参数之间空一个空格即可 remove_field => ["message"] } geoip { source => "SrcIP" #IP归属地解析插件 } } output{ elasticsearch{ hosts => "es单机或集群地址:9200" index => "impervasyslog" } }
说明:其中geoip为elk自带插件,可以解析ip归属地,比如ip归属的国家及城市,在仪表盘配置“地图炮”装X、查看攻击源地理位置的时候有点用,
2.2 绿盟WAF配置
日志报表->日志管理配置->Syslog配置&日志发生参数
针对绿盟WAF的logstash配置如下:
input和output参照imperva waf,贴出最要的grok部分,如下:
grok { match => ["message",%{DATA:syslog_flag} site_id:%{NUMBER:site_id} protect_id:%{NUMBER:protect_id} dst_ip:%{IPV4:dst_ip} dst_port:%{NUMBER:dst_port} src_ip:%{IPV4:src_ip}src_port:%{NUMBER:src_port} method:%{DATA:method} domain:%{DATA:domain} uri:%{DATA:uri} alertlevel:%{DATA:alert_level} event_type:%{DATA:Attack_types} stat_time:%{GREEDYDATA:stat_time} policy_id:%{NUMBER:policy_id}rule_id:%{NUMBER:rule_id} action:%{DATA:action} block:%{DATA:block} block_info:%{DATA:block_info} http:%{GREEDYDATA:URL}
2.3 paloalto防火墙配置
(6.1版本,其他版本可能会有点差异)
新建syslog服务器->日志转发,具体看截图
针对PA的logstash配置如下:
input和output参照imperva waf,贴出最要的grok部分,如下:
grok { match =>["message","%{DATA:PA_Name},%{GREEDYDATA:Time},%{NUMBER:Eventid},%{DATA:Category},%{DATA:Subcategory},%{NUMBER:NULL},%{GREEDYDATA:Generate_Time},%{IPV4:SourceIP},%{IPV4:DestinationIP},%{IPV4:NAT_SourceIP},%{IPV4:NAT_DestinationIP},%{DATA:RuleName},%{DATA:SourceUser},%{DATA:DestinationUser},%{DATA:Application},%{DATA:VMsys},%{DATA:SourceZone},%{DATA:DestinationZone},%{DATA:IN_interface},%{DATA:OUT_interface},%{DATA:Syslog},%{DATA:GREEDYDATA:TimeTwo},%{NUMBER:SessionID},%{NUMBER:Repeat},%{NUMBER:SourcePort},%{NUMBER:DestinationPort},%{NUMBER:NAT-SourcePort},%{NUMBER:NAT-DestinationPort},%{DATA:Flag},%{DATA:Proto},%{DATA:Action},%{DATA:NUll2},%{DATA:ThreatName},%{DATA:Category2},%{DATA:Priority},%{DATA:Direction},%{NUMBER:Serialnum},%{GREEDYDATA:NULL3}"]
贴两张最终的效果图:
三、Nginx日志收集
由于nginx日志已经被其他大数据部门收集过一遍了,为避免重复读取,我们从其他部门的kafka拉取过来即可,这里说一下nginx收集的方式,flume->kafka 示例配置方式如下:
Flume配置如下
配置扫描日志文件
log_analysis_test.conf配置文件
a1.sources=s1 #可以理解为输入端,定义名称为s1a1.channels=c1 #传输频道,类似队列,定义为c1,设置为内存模式a1.sinks=k1 #可以理解为输出端,定义为sk1#source配置
a1.sources.s1.type=execa1.sources.s1.command=tail -F/data/log/nginx/crf_crm.access.loga1.sources.s1.channels=c1#channel配置
a1.channels.c1.type=memorya1.channels.c1.capacity=1000a1.channels.c1.transactionCapacity=100a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink 设置Kafka接收器a1.sinks.k1.channel=c1a1.sinks.k1.topic=crm_nginx_log_topic #设置Kafka的Topica1.sinks.k1.brokerList=x.x.x.x:9092 #设置Kafka的broker地址和端口号a1.sinks.k1.requiredAcks=1a1.sinks.k1.batchSize=20kafka配置
kafka下载
wgethttp://mirror.bit.edu.cn/apache/kafka/0.8.2.2/kafka_2.9.1-0.8.2.2.tgz
配置zookeeper,根据机器状况更改jvm 内存设置
vimbin/zookeeper-server-start.sh
配置kafka
vimbin/kafka-server-start.sh 根据机器状况更改jvm 内存设置
启动zookeeper
nohupbin/zookeeper-server-start.sh config/zookeeper.properties &
启动kafka
nohup bin/kafka-server-start.shconfig/server.properties &
创建应用服务器的topickafka-topics.sh --create –zookeeper x.x.x.x:2181--replication-factor 2 --partitions 5 --topic crm_nginx_log_topic
分区及副本以自己的情况而定
查看Topic是否创建成功
./bin/kafka-topics.sh --list --zookeeperx.x.x.x:2181
启动kafka生产者bin/kafka-console-producer.sh --broker-listx.x.x.x:9092 --topic pay
启动kafka消费者kafka-console-consumer.sh --zookeeperx.x.x.x:2181--topic crm_nginx_log_topic
logstash 配置文件
input{ kafka { codec => "plain" group_id => "logstash1" auto_offset_reset => "smallest" reset_beginning => true topic_id => "crm_nginx_log_topic" zk_connect => "x.x.x.x:2181" # zookeeper的地址 } grok {省略} } output{ elasticsearch{ hosts => "es单机或集群地址:9200" index => "impervasyslog" }
四、安全告警
安全告警可以是Sentinl或 elastalert,Sentinl是kibana插件,可以集成到kibana内图形化展示,但是写规则时需要对JS较熟悉,elastalert 是es的插件,不支持集成到kibana界面进行图形化展示。下面分别对这2个插件进行安装及配置说明。
4.1 Sentinl
安装如下:
kibana-plugin install https://github.comsirensolutionssentinlreleasesdownloadtag-
5.4sentinl-v5.4.1.zip
安装后,以IP请求频次告警设置为例:
每2分钟去es查询一次
针对需要监控的IP字段
Input的body内容即es查询语法
编写过滤条件
{ "script": { "script":"payload.json='超过阀值40';var match=false;var threshold=40;varfirst=payload.aggregations.code.buckets;for(var i=0;i<first.length;i ){varip_count = parseInt(first[i].doc_count);if (ip_count >= threshold){match=true;payload.json = '【ip】:' first[i].key ' 【count】:' first[i].doc_count '\\n';}};match;" } }
如果想对状态码做监控,参考如下:
Action里面添加钉钉群机器人的webhook
钉钉报警如下
钉钉的接口文档链接:
https://open-doc.dingtalk.com/docs/doc.htm?spm=a219a.7629140.0.0.karFPe&treeId=257&articleId=105735&docType=1
邮件告警设置如下:
4.2 elastalert
前置条件:
JDK 1.8python 2.7easy_install -U setuptools (最新setuptools-39.2.0)yum install gccyum install python-develyum install libffi-devel安装
git clonehttps://github.com/Yelp/elastalert.git cd elastalert python setup.py install pip install -r requirements.txt cp config.yaml.example config.yaml
下载https://github.com/xuyaoqiang/elastalert-dingtalk-plugin
elastalert-dingtalk-plugin中的elastalert_modules复制到elastalert下
创建索引
elastalert-create-index
输入 es的IP 及 es的端口,其余根据自己的环境写,一般默认即可配置config.yaml,以下为关键配置信息:
rules_folder: example_rules #指定rule的目录
run_every:
minutes: 1 #每一分钟去探测一次
buffer_time:
minutes: 15 #缓存15分钟
es_host: x.x.x.x
es_port: 9200
writeback_index: elastalert_status #创建的告警索引
alert_time_limit:
days: 2 #失败重试的时间限制
下面先以钉钉告警为例:
在example_rules里面新建钉钉告警配置文件,内容如下
es_host: x.x.x.x
es_port: 9200
name: xxx安全告警
type: cardinality
index: nsfocuswaf_syslog
cardinality_field: src_ip
max_cardinality: 30
timeframe:
minutes: 5 #单IP 5分钟内访问超过30次就会告警
aggregation_key: src_ip
summary_table_fields:
- src_ip
- dst_ip
- dst_port
- Attack_types
- stat_time
alert:
-“elastalert_modules.dingtalk_alert.DingTalkAlerter”
dingtalk_webhook: “your webhook”
dingtalk_msgtype: text
群机器人的配置比较简单,自己搜索一下即可
注意如果告警匹配了N条,却只发出1条告警,修改elastalert.py代码,在856行后面增加如下代码:
修改dingtalk_alert.py的代码,增加如下内容:
src_ip = matches[0]['src_ip'] #src_ip为grok过滤后自定义的字段,以下相同 dst_ip = matches[0]['dst_ip'] dst_port = matches[0]['dst_port'] attack_types = matches[0]['Attack_types'] start_time = matches[0]['stat_time'] 修改payload初的代码,如下: payload = { "msgtype": self.dingtalk_msgtype, "text": { "content": r"发现源IP地址:{}在5分钟内,针对服务器IP:{}的{}端口发动了3次攻击,攻击类型是:{},攻击时间:{},请及时处理,谢谢!".format(src_ip,dst_ip,dst_port,attack_types,start_time) },
如果没有过滤除自定义的字段,只有message字段的话,可以新增如下代码:
message = matches[0]['message'] src_ip_pattern =r"src_ip:(\d \.\d \.\d \.\d )" dst_ip_pattern =r"dst_ip:(\d \.\d \.\d \.\d )" dst_port_pattern =r"dst_port:(\d )" time_pattern =r"stat_time:(\d{4}-\d{2}-\d{2}\s \d{2}:\d{2}:\d{2})" type_pattern =r"event_type:(\w )" src_ip= re.findall(src_ip_pattern, message)[0] dst_ip= re.findall(dst_ip_pattern, message)[0] dst_port= re.findall(dst_port_pattern, message)[0] start_time= re.findall(time_pattern, message)[0] attack_types= re.findall(type_pattern, message)[0]
最终效果图如下:
邮件的rule配置文件如下:
es_host: x.x.x.x es_port: 9200 name: 信息安全告警 type: cardinality index: nsfocuswaf_syslog cardinality_field: src_ip max_cardinality: 5 timeframe: minutes: 5 alert: - "email" smtp_host: mail.crfchina.com smtp_port: 25 smtp_auth_file:/opt/elastalert/smtp_auth_file.yaml email_reply_to: xxxxx@qq.com #回复给谁 from_addr: xxxxxx@qq.com #发件人 email: - xxxxx@qq.com #收件人 alert_subject: "信息安全告警" alert_text_type: alert_text_only alert_text: | XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX 您好, 网站:{}正被人恶意攻击,请及时处理!! 当前匹配XX规则数:{} 发生时间:{} 攻击者的IP:{} 攻击类型:{} 请求的URL:{} alert_text_args: - domain -num_hits -stat_time -src_ip -Attack_types -URL
邮件告警最终效果如下:
五、总结
相关进程运行命令如下:
后台启动es
nohup su - elasticsearch -c'/opt/elasticsearch-5.5.2/bin/elasticsearch -d' &
后台启动logstash
nohup ./bin/logstash -f x.x.x.conf &
后台启动kibana
nohup ./kibana &
启动flumeflume-ng agent --conf conf --conf-fileconf/log_analysis_test.conf --name a1 – Dflume.root.logger=INFO,console
启动kafka
nohup bin/kafka-server-start.shconfig/server.properties &
后台启动elastalert
nohup python -m elastalert.elastalert--config ./config.yaml --verbose --rule ./example_rules/DD_rule.yaml &
常见的告警策略除了来自安全设备的正则之外,大量的IP请求、错误状态码、nginx的request请求中包含的特征码也都是常见的告警规则。
,






















免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






