java设计模式代码实现 设计模式你相信吗
大家好,今天给大家介绍一个新的设计模式,叫做memento模式。
memento在英文当中是纪念品的意思,在这里,指的是对象的深度拷贝。通过对对象深度拷贝的方法来实现事务的功能。有了解过数据库的小伙伴们应该都知道,在数据库当中有些操作是绑定的,要么一起执行成功,要么一起不执行,绝对不运行某些操作执行了,某些操作没有执行的情况发生。这一点就被称为事务。
深度拷贝我们先来简单回顾一下Python当中的拷贝。
拷贝在很多语言当中都有对应的函数,在Python当中也不例外。Python中的拷贝函数有两个,一个是copy,另外一个是deepcopy。也就是常说的深拷贝和浅拷贝,这两者的区别也非常简单,简而言之就是浅拷贝只会拷贝父类对象,不会拷贝父类对象当中的子对象。
我们来看一个例子,在下图当中b是a的浅拷贝,我们可以看到当a[2]当中插入了5之后,b当中同样也多了一个5。因为它们下标2存储的是同一个引用,所以当a当中插入的时候,b当中也发生了同样的改变。我们也可以看到,当我们改变了a[0]的时候,b当中则没有发生对应的改变。因为a[0]是一个数字,数字是基础类型直接存储的值而不是引用。

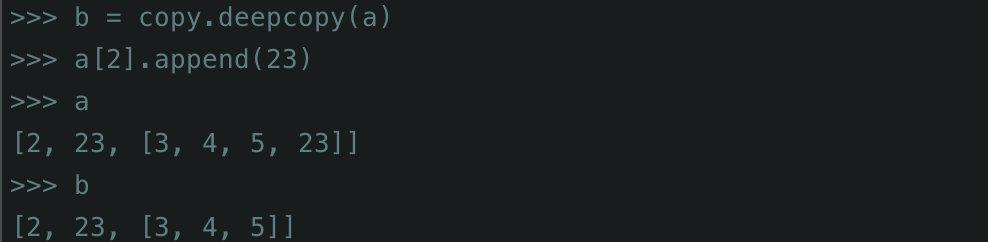
与浅拷贝对应的就是深拷贝,我们可以看到,当a[2]当中插入元素的时候,深度拷贝出来的b并不会发生对应的变化。
利用拷贝,我们可以实现memento函数,它的作用是给对象做备份。在Python当中,对于一个对象obj来说,它所有的成员以及函数等信息全是储存在obj.__dict__这个dict当中的。也就是说如果我们将一个对象的__dict__拷贝一份的话,其实就相当于我们把对象拷贝了一份。
通过使用拷贝,我们可以很容易实现memento函数,我们先来看代码吧。
fromcopyimportcopy,deepcopy
defmemento(obj,deep=False):
state=deepcopy(obj.__dict__)ifdeepelsecopy(obj.__dict__)
defrestore():
obj.__dict__.clear()
obj.__dict__.update(state)
returnrestore
memento是一个高阶函数,它返回的结果是执行函数,而不是具体的执行结果。如果对高阶函数不太熟悉的同学,可以去回顾一下Python当中高阶函数的相关内容。
这里面的逻辑不难理解,传入的参数是一个obj的对象和一个bool型的flag。flag表示使用深拷贝或浅拷贝,obj就是我们需要做对应快照或者是存档的对象。我们希望在对象框架不变的基础上恢复其中的内容,所以我们拷贝的范围很明确,就是obj.__dict__,这当中存储了对象的所有关键信息。
我们看下restore这个函数,当中的内容其实很简单,只有两行。第一行是清空obj目前__dict__当中的内容,第二步是用之前保存的state来还原。其实restore执行的是一个回滚obj的功能,我们捋一下整个过程。我们运行memento函数会得到restore这个函数,当我们执行这个函数的时候,obj当中的内容会回滚到上次执行memento时的状态。
理解了memento当中的逻辑之后,距离我们实现事务就不远了。关于事务我们有两种实现方法,一种是通过对象,一种是通过装饰器,我们一个一个来说吧。
Transaction对象面向对象实现的方式比较简单,它和我们平时使用事务的过程也比较近似。Transaction对象当中应该提供两个函数,一个是commit一个是rollback。也就是说当我们执行成功之后我们执行commit,对执行的结果进行快照。如果执行失败则rollback,将对象的结果回滚到上一次commit时的状态。
我们理解了memento函数之后,会发现commit和rollback刚好对应执行memento函数以及执行restore函数。这样我们不难写出代码:
classTransaction:
deep=False
states=[]
def__init__(self,deep,*targets):
self.deep=deep
self.targets=targets
self.commit()
defcommit(self):
self.states=[memento(target,self.deep)fortargetinself.targets]
defrollback(self):
fora_stateinself.states:
a_state()
由于我们需要事务的对象可能不止一个,所以这里的targets设计成了数组的形式。
Transaction装饰器我们也可以把事务实现成装饰器,这样我们可以通过注解的方式来使用。
这里的代码原理也是一样的,只不过实现逻辑基于装饰器而已。如果对装饰器熟悉的同学,其实也不难理解。这里的args[0]其实就是某一个类的实例,也就是我们需要保证事务的主体。
fromfunctoolsimportwraps
deftransactional(func):
@wraps(func)
defwrapper(*args,**kwargs):
#args[0]isobj
state=memento(args[0])
try:
func(*args,**kwargs)
exceptExceptionase:
state()
raisee
returnwrapper
这是常规装饰器的写法,当然我们也可以用类来实现装饰器,其实原理差不多,只是有一些细节不太一样。
classTransactional:
def__init__(self,method):
self.method=method
def__get__(self,obj,cls):
deftransaction(*args,**kwargs):
state=memento(obj)
try:
returnself.method(*args,**kwargs)
exceptExceptionase:
state()
raisee
returntransaction
当我们将这个注解加在某一个类方法上,当我们执行obj.xxx的时候,就会执行Transactional这个类当中的__get__方法,而不是获得Transactional这个类。并且把obj以及obj对应的类型作为参数传入,也就是这里的obj和cls的含义。这个是用类来实现装饰器的常规做法,我们贴一下常规的代码,来比较学习一下。
classWrapper:
def__init__(self,func):
wraps(func)(self)
def__call__(self,*args,**kwargs):
returnself.__wrapped__(*args,**kwargs)
def__get__(self,instance,cls):
ifinstanceisNone:
returnself
else:
returntypes.MethodType(self,instance)
这是一个用类来实现装饰器的case,我们可以看到在__get__这个函数当中返回的是self,也就是返回了Wrapper这个类。类通常是不能直接执行的,为了让它能够执行,这里给它实现了一个__call__函数。如果还是看不明白也没有关系,可以忽略这部分。用类实现装饰器也不常见,我们熟悉高阶函数的方法就可以了。
实战最后我们来看一个实际应用的例子,我们实现了一个NumObj的类,兼容了上面两种事务的使用,可以对比一下看看区别。
classNumObj:
def__init__(self,value):
self.value=value
def__repr__(self):
return'<%s,%r>'%(self.__class__.__name__,self.value)
defincrement(self):
self.value =1
@transactional
defdo_stuff(self):
self.value ='111'
self.increment()
if__name__=='__main__':
num_obj=NumObj(-1)
a_transaction=Transaction(True,num_obj)
#使用Transaction
try:
foriinrange(3):
num_obj.increment()
print(num_obj)
a_transaction.commit()
print('----committed')
foriinrange(3):
num_obj.increment()
print(num_obj)
num_obj.value ='x'
print(num_obj)
exceptException:
a_transaction.rollback()
print('----rollback')
print(num_obj)
#使用Transactional
print('--nowdoingstuff')
num_obj.increment()
try:
num_obj.do_stuff()
exceptException:
print('->doingstufffailed')
importsys
importtraceback
traceback.print_exc(file=sys.stdout)
print(num_obj)
从代码当中,我们不难发现对于Transaction也就是面向对象实现的,我们需要额外创建一个Transaction的实例来在try catch当中控制是否执行回滚。而使用注解的方式更加灵活,它执行失败会自动执行回滚,不需要太多的额外操作。
一般来说我们更加喜欢使用注解的方式,因为这样的方式更加简洁干净,更加pythonic,能够体现出Python的强大。而第一种方法显得有些中规中矩,不过好处是可读性强一些,代码实现难度也低一些。大家如果在实际工作当中有需要用到,可以根据自己的实际情况去进行选择,两种都是不错的方法。
今天的文章就到这里,衷心祝愿大家每天都有所收获。如果还喜欢今天的内容的话,请来一个三连支持吧~(点赞、关注、转发)
本文始发于公众号:TechFlow,求个关注
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com