英特尔锐炫显卡新老驱动对比(蛰伏二十余载PC独显进入)
3 月 30 日,英特尔正式发布英特尔锐炫 ARC 移动端独立显卡,代号 Alchemist(炼金术士),遥想英特尔首次面向消费端的独显产品推出已经 24 年了,在那之后英特尔独显产品开发就陷入了停滞转而专注核显开发。

在经过多年的技术积累,英特尔此前面向服务器市场推出了 DG1 显卡,今年正式面向消费端推出英特尔锐炫 ARC 独显产品,首批针对移动端推出的 A 系列产品包含锐炫 3/5/7 三个型号。

其中英特尔锐炫 3 主要面向主流游戏市场,锐炫 5 主要面向性能游戏市场,锐炫 7 主要面向发烧级硬核游戏。此次英特尔推出了移动端 A 系列的 A350M 和 A370 M 产品。全新英特尔锐炫显卡支持 XeSS 超采样、完整的 AV1 硬件加速、Smooth Sync 抖动过滤、Deep Link 功能,全方位覆盖游戏、创意设计、功耗控制等场景。

首款搭载英特尔锐炫 ARC 独显的是三星 Galaxy Boo2 Pro 轻薄本产品,这款产品获得英特尔 Evo 严苛认证,目前已经在海外市场正式上市。

未来借助英特尔在处理器市场上的份额优势,将会有大量搭载英特尔锐炫 ARC 独显笔记本产品上市。通过英特尔 Evo 认证的产品在续航和显示能力上也将得到进一步提升。

目前宏碁、华硕、戴尔、海尔、惠普、联想、微星、三星、英特尔 NUC 等品牌或者产品已经有推出锐炫独显笔记本的打算,通过锐炫独显,英特尔未来也可以整合自家产品,推出第一方英特尔笔记本。

配套的英特尔锐炫控制面板也随着英特尔锐炫独显产品的上市同步推出,这一控制面板集合了驱动自动更新、性能监控、性能调优、直播管理、游戏高光时刻生成、活动推广等功能,并且无需强制登录就可使用。

接下来了,我们通过详细的解析了解一下全新的英特尔锐炫 ARC 独立显卡的底层架构和技术亮点。
底层架构
英特尔锐炫 ARC 独显产品基于英特尔 Xe HPG 架构开发,核心采用内置 XMX 的 Xe 内核,包含 Xe 媒体引擎、Xe 显示引擎以及 Xe 图形管线三大核心功能。
通过 Xe HPG 微架构,英特尔锐炫显卡在开发过程中有很大的灵活性,渲染切片是 Xe HPG 微架构的基本模块,每个 Xe HPG 渲染切片包含 4 个 Xe 内核、4 个光追单元、4 个采样器、几何引擎、光栅引擎、HiZ 引擎以及 2 个像素后端构成。

每个 Xe 内核中包含 XMX 矩阵引擎、XVE 适量引擎、光追单元、采样器等,这些构成了一个完整的 Xe 内核,也是 Xe HPG 微架构的基本运算单元,这与以往的执行单元 EU 概念有所不同,通过 4 个 Xe 内核构成的渲染切片,以不同组合方式就构成不同的 SoC 以此形成不同的产品形态。

英特尔锐炫显卡通过叠加渲染切片方式构成不同的产品线,最小为 2 个,最大为 8 个,通过不同形式的组合构成了各种各样的产品。针对光追和 DX12 Ultimate,Xe HPG 微架构也有很好的支持。
回到 Xe 内核上,每个 Xe 内核提供 16 个 256 位的 XVE 矢量引擎、16 个 1024 位的 XMX 矩阵引擎,并配备 192KB 的共享一级缓存。XVE 适量引擎用于执行传统的图像处理计算,XMX 矩阵引擎则主要用于 AI 加速。

其中 XVE 矢量引擎每个时钟周期可以执行 16 个 FP32 操作、32 个 FP16 操作以及 64 个 INT8 操作,专用的 FP 浮点执行接口和共享 INT / EM 执行接口。XMX 矩阵引擎每个时钟周期可以执行 128 个 FP16 / BF16 操作、256 个 INT8 操作、512 个 INT4 / INT2 操作。

XMX 算力提升相比于传统的 MAC 或者进阶的 DP4a 是非常巨大的,我们知道 MAC 是图形中使用的基本 SIMD 矢量指令,每个时钟周期共执行 8 次并行运算乘法和 8 次并行加法。而 DP4a 则针对不需要 32 位精度的 AI 计算所做的优化,每个时钟周期共执行 32 次并行乘法、32 次累加或每个周期总共 64 次 操作,这比标准 SIMD MAC 提高了 4 倍的性能。
而 XMX 矩阵引擎通过将乘法累加 4 深度流水线化,将其提升到一个新的水平。与 DP4a 一样,每个操作数都被分成 4 个块,这些块被独立的相乘和累加 —— 每个阶段 64 个操作 ——(由紫色图块显示)。通过 4 个阶段,每个时钟产生 256 次操作 —— 比传统的 32 位 SIMD MAC 增加了 16 倍的性能。

XMX 的提升最好的应用就是 XeSS 超采样抗锯齿技术,与传统高分辨率渲染相比可以在游戏中提供更高的性能,通过神经网络辅助运动矢量,从低分辨率渲染中生成精美的高分辨率图像,这有些类似英伟达 DLSS。
目前 XeSS 超采样抗锯齿技术将在今年夏天正式到来,首批支持 XeSS 的游戏包括《古墓丽影:暗影》、《超级房车赛:传奇》、《幽灵线:东京》、《死亡搁浅》、《血猎》、《CHORVS》、《Arcadegeddon》、《杀手 3》等 14 款游戏。

通过 Xe 媒体引擎,锐炫显卡支持多种主流格式的编解码器,包括 H.265 / HEVC、H.264 / MPEG-4 / AVC、VP9 以及 AV1。

其中针对 AV1 的硬件编解码加速支持英特尔锐炫显卡是第一家提供的 GPU 提供商,这些格式的编解码可以以极低的处理器利用率完成。由于 AV1 出色的效率,未来 AV1 也将成为主流的视频格式,它相比于 H.264 和 HEVC 效率更高,可以以更低的带宽和更小的文件大小实现更好的画面质量,且 AV1 没有版权费。

英特尔锐炫显卡对 AV1 的硬解码能力相比于传统软解码在编码速度上提高了 50 倍,目前 FFMPEG、Handbrake、Adobe Premiere Pro、 Davinci Resolve、XSplit 都已经集成了锐炫 AV1 硬解码的支持。

Xe 显示引擎主要为当前阶段以及未来的显示技术打造,现阶段英特尔锐炫显卡支持 HDMI 2.0b、DP 1.4a,DP 2.0 10G 也将支持。通过英特尔锐炫显卡,玩家可以享受 2 台 8K@60 HDR 或者 4 台 4K@120 HDR 的最高画面输出。
在游戏场景中,英特尔提供多项同步技术帮助玩家有着更好的体验,其中 VESA 标准 Adaptive Sync 防撕裂技术英特尔锐炫显卡提供支持。而 Speed Sync 这项新的技术,可以为游戏当前帧提供加速,Speed Sync 通过关闭 V-Sync 并渲染帧的整体来达到低延时无撕裂的效果。

Smooth Sync 是英特尔推出的另一项画面优化技术,这项技术通过模糊两个撕裂帧的边界,来减少视觉失真以此让画面看起来更加连贯流畅。

性能表现
此次全新推出的英特尔锐炫独显产品共包含 2 种不同的 SoC 设计,代号分别为 ACM-G10 和 ACM- G11,其中 ACM- G10 共包含 32 个 Xe 内核和光追单元,16MB 的 L2 缓存以及 256 位的 GDDR6 接口、16 路 PCIe 4.0 接口;ACM-G11 则包含 8 个 Xe 内核和光追单元,4MB 的 L2 缓存、96 位的 DDR6 接口、8 路 PCIe 接口。两种芯片均包含 2 个 Xe 多功能编解码引擎和 4 个图像输出引擎。

有关频率问题,我们知道不同的频率要求典雅和功耗也不一样,其实根据日常使用的场景,笔记本往往在不同负载场景下的频率功耗呈现一个动态分布状态。基于这种分布,英特尔锐炫显卡在分配参数是,往往设定一个有代表性的负载,再根据这个负载的频率、参数情况对显卡的频率进行定义。不同的平台有着不同的 TDP,在更宽松的 TDP 限制下,时钟频率的分布范围也会整体提升。

因此,英特尔根据此划分出首批 A 系列的 5 款显卡产品,其中首发的锐炫 3 A370M 包含 8 个 Xe 内核和光追单元、主频 1550MHz、8GB GDDR6 64 bit 显存、TGP 在 35-50W 之间;锐炫 5 A550M 则包含 16 个 Xe 内核和光追单元、主频 900MHz、8GB GDDR6 128 bit 显存、TGP 在 60-80W 之间;锐炫 7 A770M 则包含 32 个 Xe 内核和光追单元、主频 1650MHz、16GB GDDR6 256 bit 显存、TGP 在 120-150W 之间。锐炫 3 产品已经正式上市,锐炫 5/7 则将在今年夏天正式上市。

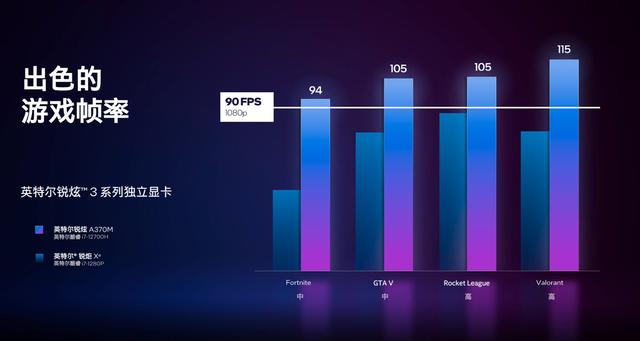
在游戏表现上,首批上市的锐炫 A370M 显卡主要面向中高画质游戏,主打场景在 1080P 帧下的大型游戏。相比于 96EU 的 Xe 核显在帧率上有着 60 帧以上的表现。

而在《堡垒之夜》、《GTA V》等需要高帧率的游戏场景下,锐炫 A370M 中高画质下帧率超过 90 帧,已经达到一个流畅的水平。
创意生产场景下,和 12 代酷睿的集成显卡相比,在搭载 A370M 独立显卡的平台上,性能也有了显著提升。在视频编解码方面,以 Davinci Resolve 为例,4K H.264 转 H.265 的性能可提升多达 60%。而在 AI 相关功能上,例如 Adobe Promiere Pro 里的两个应用场景,更是有翻倍的性能提升。

在创作场景下的提升,不光取决于显卡本身,同时还得益于英特尔全新的 Deep Link 技术带来的巨大提升。下面我们来看看 Deep Link 的工作原理。
英特尔 Deep Link 技术
英特尔 Deep Link 技术区别于以往单纯动态功率共享,英特尔锐炫显卡在与英特尔 12 代酷睿处理器之间除了功耗的动态共享,还引入了超级编码和超级算力能力。

动态功率共享技术能在系统功耗的限制范围内,尽可能最大化释放 CPU 或 GPU 的性能。英特尔已经在这项技术上探索了很长时间。早在 2016 年,Kobe-Lake G 时代,我们就有第一版动态功率共享,在 CPU 裸片和 GPU 裸片之间动态分配功率。
现在的 ADL 和 A 系列独立显卡之间这项功能也得到进一步应用,在运行负载时,如果 CPU 更需要功率,功率会更多的分配给 CPU,反之对 GPU 也是一样,最终目的是让这个负载有更好的性能。

第二项技术则超级编码技术,这项技术的初衷是为最终用户提升编解码效率。以前的编解码流程里,通常把编码工作放在一个显卡的编解码器上,编码效率成为了整个流程的性能瓶颈;而实际上现在的英特尔笔记本系统,例如搭载了 12 代酷睿处理器和锐炫 A 系列独立显卡的系统,集成显卡和独立显卡都有硬件编码能力。所以超级编码技术,就是同时运用两个显卡的编解码引擎,来大大提升编解码效率。

这种协作是通过 OneVPL 的 API 接口来实现的。OneVPL 是一个跨平台的开放性框架,应用程序通过接口可以识别并调用平台上多个多媒体引擎,充分利用视频处理能力。当超级编码开始工作时,一组组解码后的原始帧通过特定的 API 函数被交给 oneVPL,进而按组被分配到不同的多媒体引擎上,拷贝到相应的内存中缓存起来。不论每一组有多少帧,相应的集显或者独显的多媒体引擎会开始按照设定的格式编码。而 OneVPL 会完成后续的打包工作,把编码后的帧一组组拼接成最终视频来输出。这种并行处理,编码效率比单一显卡提升非常显著。
在算力提升上也有着与超级编码类似的逻辑,即尽可能地让整个系统都参与进来,并且合适的模块做合适的事,超级算力这项技术也是这样的逻辑。

搭载英特尔锐炫独立显卡的笔记本可以从独立显卡的算力中获益,但英特尔 CPU 的集成显卡中同样也提供了计算引擎。通过把负载合理的分配给不同的计算引擎,以此实现算力最大化。这其中就使用了 OpenVino 中的 MLS 框架来将算力进行最大化的实现。

MLS 能智能的把负载分配给不同的算力模块,通过延迟敏感度、吞吐量、性能要求、功率消耗等应用或负载的特征帮助 MLS 做出决策,把负载分配给独立显卡、集成显卡或者 CPU。

通过 Deep Link 几项关键的技术,在创作场景英特尔酷睿笔记本 英特尔锐炫显卡的组合带来了性能的大幅提升。系统各个模块更加紧密的协作,让每一个模块的性能得到充分释放。基于这一理念,Deep Link 将英特尔平台上各个模块有机结合,让整体效率更进一步。
总结
英特尔在蛰伏多年,终于开启了独显之路,首批上市的独显产品主要针对移动端,凭借英特尔在处理器领域的强大占有率,未来英特尔锐炫独显产品也将成为继 N 卡、A 卡后一支强大的力量,显卡市场将进入“三国时代”。在显卡市场价格高企的当下,英特尔的入局对于消费者来讲是件好事情,更多的选择也就意味着产品之间价格战将会打响。

对于行业而言,英特尔的 i i 方案既有利于英特尔对产品的整体把控,也让英特尔在开发者与合作伙伴之间提供了更进一步的一致性产品。
英特尔的下海,无疑会搅动独立显卡这个庞大的市场,未来这样的“三国”局面将如何发展,我们拭目以待。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






