面试技巧 数据分析(教你面试的时候如何迅速完成90)
目录
- 一、多系统订阅数据回顾
- 二、核心数据的监控系统
- 三、电商库存数据如何监控
- 四、数据计算链路追踪
- 五、百亿流量下的数据链路追踪
- 六、自动化数据链路分析
- 七、下篇预告
上篇文章《美团二面:如果每天有百亿流量,你如何保证数据一致性?》,初步给大家分析了一下,一个复杂的分布式系统中,数据不一致的问题是怎么产生的。
简单来说,就是一个分布式系统中的多个子系统(或者服务)协作处理一份数据,但是最后这个数据的最终结果却没有符合期望。
这是一种非常典型的数据不一致的问题。当然在分布式系统中,数据不一致问题还有其他的一些情况。
比如说多个系统都要维护一份数据的多个副本,结果某个系统中的数据副本跟其他的副本不一致,这也是数据不一致。
但是这几篇文章,说的主要是我们上篇文章分析的那种数据不一致的问题到底应该如何解决。
一、多系统订阅数据回顾
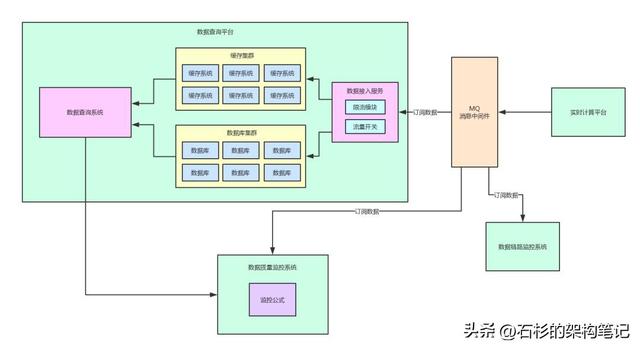
我们先来看一张图,是之前讲系统架构解耦的时候用的一张图。

好!通过上面这张图,我们来回顾一下之前做了系统解耦之后的一个架构图。
其实,实时计算平台会把数据计算的结果投递到一个消息中间件里。
然后,数据查询平台、数据质量监控系统、数据链路追踪系统,各个系统都需要那个数据计算结果,都会去订阅里面的数据。
这个就是当前的一个架构,所以这个系列文章分析到这里,大家也可以反过来理解了之前为什么要做系统架构的解耦了。
因为一份核心数据,是很多系统都可能会需要的。通过引入MQ对架构解耦了之后,各个系统就可以按需订阅数据了。
二、核心数据的监控系统如果要解决核心数据的不一致问题,首先就是要做核心数据的监控。
有些同学会以为这个监控就是用falcon之类的系统,做业务metrics监控就可以了,但是其实并不是这样。
这种核心数据的监控,远远不是做一个metrics监控可以解决的。
在我们的实践中,必须要自己开发一个核心数据的监控系统,在里面按照自己的需求,针对复杂的数据校验逻辑开发大量的监控代码。
我们用那个数据平台项目来举例,自己写的数据质量监控系统,需要把核心的一些数据指标从MQ里消费出来,这些数据指标都是实时计算平台计算好的。
那么此时,就需要自定义一套监控逻辑了,这种监控逻辑,不同的系统都是完全不一样的。
比如在这种数据类的系统里,很可能对数据指标A的监控逻辑是如下这样的:
- 数据指标A = 数据指标B 数据指标C - 数据指标D * 24。
每个核心指标都是有自己的一个监控公式的,这个监控公式,就是负责开发实时计算平台的同学,他们写的数据计算逻辑,是知道数据指标之间的逻辑关系的。
所以此时就有了一个非常简单的思路:
- 首先,这个数据监控系统从MQ里消费到每一个最新计算出来的核心数据指标
- 然后根据预先定义好的监控公式,从数据查询平台里调用接口获取出来公式需要的其他数据指标
- 接着,按照公式进行监控计算。
如果监控计算过后发现几个数据指标之间的关系居然不符合预先定义好的那个规则,那么此时就可以立马发送报警了(短信、邮件、IM通知)。
工程师接到这报警之后,就可以立马开始排查,为什么这个数据居然会不符合预先定义好的一套业务规则呢。
这样就可以解决数据问题的第一个痛点:不需要等待用户发现后反馈给客服了,自己系统第一时间就发现了数据的异常。
同样,给大家上一张图,直观的感受一下。
如果用电商里的库存数据来举例也是一样的,假设你想要监控电商系统中的核心数据:库存数据。
首先第一步,在微服务架构中,你必须要收口。
也就是说,在彻底的服务化中,你要保证所有的子系统 / 服务如果有任何库存更新的操作,全部走接口调用请求库存服务。只能是库存服务来负责库存数据在数据库层面的更新操作,这样就完成了收口。
收口了之后做库存数据的监控就好办了,完全可以采用MySQL binlog采集的技术,直接用Mysql binlog同步中间件来监控数据库中库存数据涉及到的表和字段。
只要库存服务对应的数据库中的表涉及到增删改操作,都会被Mysql binlog同步中间件采集后,发送到数据监控系统中去。
此时,数据监控系统就可以采用预先定义好的库存数据监控逻辑,来查验这个库存数据是否准确。
这个监控逻辑可以是很多种的,比如可以后台走异步线程请求到实际的C/S架构的仓储系统中,查一下实际的库存数量。
或者是根据一定的库存逻辑来校验一下,举个例子:
- 虚拟库存 预售库存 冻结库存 可销售库存 = 总可用库存数
当然,这就是举个例子,实际如何监控,大家根据自己的业务来做就好了。

此时我们已经解决了第一个问题,主动监控系统中的少数核心数据,在第一时间可以自己先收到报警发现核心是护具有异常。
但是此时我们还需要解决第二个问题,那就是当你发现核心数据出错之后,如何快速的排查问题到底出在哪里?
比如,你发现数据平台的某个核心指标出错,或者是电商系统的某个商品库存数据出错,此时你要排查数据到底为什么错了,应该怎么办呢?
很简单,此时我们必须要做数据计算链路的追踪。
也就是说,你必须要知道这个数据从最开始到底是经历了哪些环节和步骤,每个环节到底如何更新了数据,更新后的数据又是什么,还有要记录下来每次数据变更后的监控检查点。
比如说:
- 步骤A -> 步骤B -> 步骤C -> 2018-01-01 10:00:00
第一次数据更新后,数据监控检查点,数据校验情况是准确,库存数据值为1365;
- 步骤A -> 步骤B -> 步骤D -> 步骤C -> 2018-01-01 11:05:00
第二次数据更新后,数据监控检查点,数据校验情况是错误,库存数据值为1214
类似上面的那种数据计算链路的追踪,是必须要做的。
因为你必须要知道一个核心数据,他每次更新一次值经历了哪些中间步骤,哪些服务更新过他,那一次数据变更对应的数据监控结果如何。
此时,如果你发现一个库存数据出错了,立马可以人肉搜出来这个数据过往的历史计算链路。
你可以看到这条数据从一开始出现,然后每一次变更的计算链路和监控结果。
比如上面那个举例,你可能发现第二次库存数据更新后结果是1214,这个值是错误的。
然后你一看,发现其实第一次更新的结果是正确的,但是第二次更新的计算链路中多了一个步骤D出来,那么可能这个步骤D是服务D做了一个更新。
此时,你就可以找服务D的服务人问问,结果可能就会发现,原来服务D没有按照大家约定好的规则来更新库存,结果就导致库存数据出错。
这个,就是排查核心数据问题的一个通用思路。
五、百亿流量下的数据链路追踪如果要做数据计算链路,其实要解决的技术问题只有一个,那就是在百亿流量的高并发下,任何一个核心数据每天的计算链路可能都是上亿的,此时你应该如何存储呢?
其实给大家比较推荐的,是用Elasticsearch技术来做这种数据链路的存储。
因为es一方面是分布式的,支持海量数据的存储。
而且他可以做高性能的分布式检索,后续在排查数据问题的时候,是需要对海量数据做高性能的多条件检索的。
所以,我们完全可以独立出来一个数据链路追踪系统,并设置如下操作:
- 数据计算过程中涉及到的各个服务,都需要对核心数据的处理发送一条计算链路日志到数据链路追踪系统。
- 然后,数据链路追踪系统就可以把计算链路日志落地到存储里去,按照一定的规则建立好对应的索引字段。
- 举个例子,索引字段:核心数据名称,核心数据id,本次请求id,计算节点序号,本次监控结果,子系统名称,服务名称,计算数据内容,等等。
此时一旦发现某个数据出错,就可以立即根据这条数据的id,从es里提取出来历史上所有的计算链路。
而且还可以给数据链路追踪系统开发一套用户友好的前端界面,比如在界面上可以按照请求id展示出来每次请求对应的一系列技术步骤组成的链路。
此时会有什么样的体验呢?我们立马可以清晰的看到是哪一次计算链路导致了数据的出错,以及过程中每一个子系统 / 服务对数据做了什么样的修改。
然后,我们就可以追本溯源,直接定位到出错的逻辑,进行分析和修改。
说了那么多,还是给大家来一张图,一起来感受一下这个过程。

到这里为止,大家如果能在自己公司的大规模分布式系统中,落地上述那套数据监控 链路追踪的机制,就已经可以非常好的保证核心数据的准确性了。
通过这套机制,核心数据出错时,第一时间可以收到报警,而且可以立马拉出数据计算链路,快速的分析数据为何出错。
但是,如果要更进一步的节省排查数据出错问题的人力,那么可以在数据链路追踪系统里面加入一套自动化数据链路分析的机制。
大家可以反向思考一下,假如说现在你发现数据出错,而且手头有数据计算链路,你会怎么检查?
不用说,当然是大家坐在一起唾沫横飞的分析了,人脑分析。
比如说,步骤A按理说执行完了应该数据是X,步骤B按理说执行完了应该数据是Y,步骤C按理说执行完了应该数据是Z。
结果,诶!步骤C执行完了怎么数据是ZZZ呢??看来问题就出在步骤C了!
然后去步骤C看看,发现原来是服务C更新的,此时服务C的负责人开始吭哧吭哧的排查自己的代码,看看到底为什么接收到一个数据Y之后,自己的代码会处理成数据ZZZ,而不是数据Z呢?
最后,找到了代码问题,此时就ok了,在本地再次复现数据错误,然后修复bug后上线即可。
所以,这个过程的前半部分,是完全可以自动化的。也就是你写一套自动分析数据链路的代码,就模拟你人脑分析链路的逻辑即可,自动一步步分析每个步骤的计算结果。这样就可以把数据监控系统和链路追踪系统打通了。
一旦数据监控系统发现数据出错,立马可以调用链路追踪系统的接口,进行自动化的链路分析,看看本次数据出错,到底是链路中的哪个服务bug导致的数据问题。
接着,将所有的信息汇总起来,发送一个报警通知给相关人等。
相关人员看到报警之后,一目了然,所有人立马知道本次数据出错,是链路中的哪个步骤,哪个服务导致的。
最后,那个服务的负责人就可以立马根据报警信息,排查自己的系统中的代码了。

到这篇文章为止,我们基本上梳理清楚了大规模的负责分布式系统中,如何保证核心数据的一致性。
那么下篇文章,我们再就技术实现中涉及到的一些MQ技术的细节,基于RabbitMQ来进行更进一步的分析。
------------- END -------------


另外推荐儒猿课堂的1元系列课程给您,欢迎加入一起学习~
互联网Java工程师面试突击课(1元专享)SpringCloudAlibaba零基础入门到项目实战(1元专享)亿级流量下的电商详情页系统实战项目(1元专享)Kafka消息中间件内核源码精讲(1元专享)12个实战案例带你玩转Java并发编程(1元专享)Elasticsearch零基础入门到精通(1元专享)基于Java手写分布式中间件系统实战(1元专享)基于ShardingSphere的分库分表实战课(1元专享)
,
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






