mysql联合查询语句(关联两个不同数据库查询)
上一篇讲的是单表查询的优化,没看过的朋友可以去看看(本文末有链接)。当然,对数据表的多表查询也是必不可少的。本篇内容主要讲解多表联合查询的优化,阅读后有收获的朋友可以收藏关注一波,本头条号内有多个专题,致力于长期分享高质量原创java文章。
一、多表查询连接的选择:
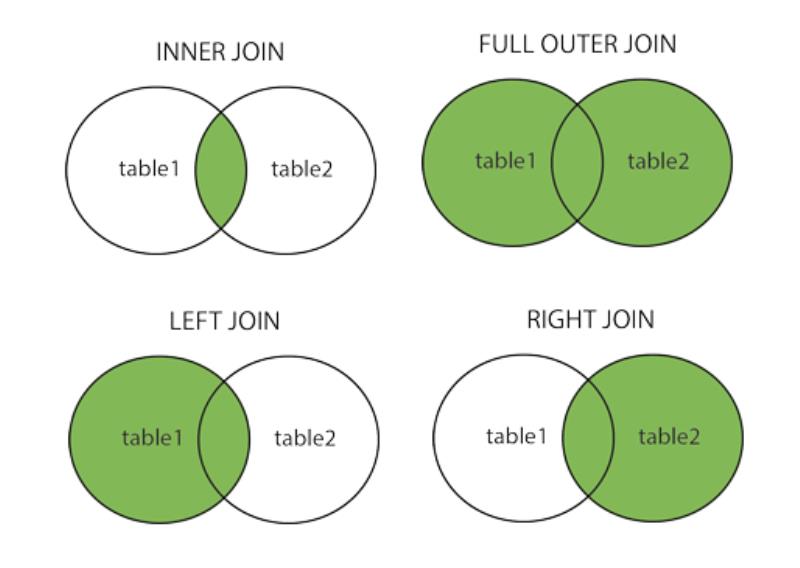
相信这内连接,左连接什么的大家都比较熟悉了,当然还有左外连接什么的,基本用不上我就不贴出来了。这图只是让大家回忆一下,各种连接查询。 然后要告诉大家的是,需要根据查询的情况,想好使用哪种连接方式效率更高。(这是技术文)
二、MySQL的JOIN实现原理
在MySQL 中,只有一种Join 算法,就是大名鼎鼎的Nested Loop Join,他没有其他很多数据库所提供的Hash Join,也没有Sort Merge Join。顾名思义,Nested Loop Join 实际上就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有第三个参与Join,则再通过前两个表的Join 结果集作为循环基础数据,再一次通过循环查询条件到第三个表中查询数据,如此往复。 ——摘自《MySQL 性能调优与架构设计》
–
三、补充:mysql对sql语句的容错问题
即在sql语句不完全符合书写建议的情况,mysql会允许这种情况,尽可能解释它:
1)一般cross join后面加上where条件,但是用cross join+on也是被解释为cross join+where;
2)一般内连接都需要加上on限定条件,如上面场景一;如果不加会被解释为交叉连接;
3)如果连接表格使用的是逗号,会被解释为交叉连接;
注:sql标准中还有union join和natural inner join,mysql不支持,而且本身也没有多大意义,其实就是为了“健壮”。但是其实结果可以用上面的几种连接方式得到。
三、超大型数据尽可能尽力不要写子查询,使用连接(JOIN)去替换它:
当然,关于这句话,也不一定就全是这样。
1)因为在大型的数据处理中,子查询是非常常见的,特别是在查询出来的数据需要进一步处理的情况,无论是可读性还是效率上,这时候的子查都是更优。
2)然而在一些特定的场景,可以直接从数据库读取就可以的,比如一个表(A表 a,b,c字段,需要内部数据交集)join自己的效率必然比放一个子查在where中快得多。(这真是技术文)
四、使用联合(UNION)来代替手动创建的临时表
UNION是会把结果排序的!!!
union查询:它可以把需要使用临时表的两条或更多的select查询合并的一个查询中(即把两次或多次查询结果合并起来。)。在客户端的查询会话结束的时候,临时表会被自动删除,从而保证数据库整齐、高效。使用union来创建查询的时候,我们只需要用UNION作为关键字把多个select语句连接起来就可以了,要注意的是所有select语句中的字段数目要想同。
#
要求:两次查询的列数必须一致(列的类型可以不一样,但推荐查询的每一列,相对应的类型要一样)
可以来自多张表的数据:多次sql语句取出的列名可以不一致,此时以第一个sql语句的列名为准。
如果不同的语句中取出的行,有完全相同(这里表示的是每个列的值都相同),那么union会将相同的行合并,最终只保留一行。也可以这样理解,union会去掉重复的行。
如果不想去掉重复的行,可以使用union all。
如果子句中有order by,limit,需用括号()包起来。推荐放到所有子句之后,即对最终合并的结果来排序或筛选。

注意:
1、UNION 结果集中的列名总是等于第一个 SELECT 语句中的列名
2、UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同
UNION ALL的作用和语法:
默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。

五、总结
(1)对于要求全面的结果时,我们需要使用连接操作(LEFT JOIN / RIGHT JOIN / FULL JOIN);
(2)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:

备注、描述、评论之类的可以设置为 NULL,其他最好不要使用NULL。
不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了, 不管是否插入值(NULL也包含在内),都是占用 100个字符的空间的,如果是varchar这样的变长字段, null 不占用空间。
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num = 0
(3)in 和 not in 也要慎用,否则会导致全表扫描,如:

对于连续的数值,能用 between 就不要用 in 了:

很多时候用 exists 代替 in 是一个好的选择:

(4)尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连 接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
(5)尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
(6)不要以为使用MySQL的一些连接操作对查询有多么大的改善,其实核心是索引
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com