java爬虫有哪些(爬虫服务器被屏蔽)
屏蔽爬虫程序是资源网站的一种保护措施,最常用的反爬虫策略应该是基于用户的访问行为。比如限制每台服务器在一定的时间内只能访问 X 次,超过该次数就认为这是爬虫程序进行的访问,基于用户访问行为判断是否是爬虫程序也不止是根据访问次数,还会根据每次请求的User Agent 请求头、每次访问的间隔时间等。总的来说是由多个因数决定的,其中以访问次数为主。
反爬虫是每个资源网站自保的措施,旨在保护资源不被爬虫程序占用。例如我们前面使用到的豆瓣网,它会根据用户访问行为来屏蔽掉爬虫程序,每个 IP 在每分钟访问次数达到一定次数后,后面一段时间内的请求返回直接返回 403 错误,以为着你没有权限访问该页面。所以我们今天再次拿豆瓣网为例,我们用程序模拟出这个现象,下面是我编写的一个采集豆瓣电影的程序
/** * 采集豆瓣电影 */ public class CrawlerMovie { public static void main(String[] args) { try { CrawlerMovie crawlerMovie = new CrawlerMovie(); // 豆瓣电影链接 List<String> movies = crawlerMovie.movieList(); //创建10个线程的线程池 ExecutorService exec = Executors.newFixedThreadPool(10); for (String url : movies) { //执行线程 exec.execute(new CrawlMovieThread(url)); } //线程关闭 exec.shutdown(); } catch (Exception e) { e.printStackTrace(); } } /** * 豆瓣电影列表链接 * 采用反向解析法 * * @return */ public List<String> movieList() throws Exception { // 获取100条电影链接 String url = "movie.douban/j/search_subjects?type=movie&tag=热门&sort=recommend&page_limit=200&page_start=0"; closeablehttpclient client = HttpClients.createDefault(); List<String> movies = new ArrayList<>(100); try { HttpGet httpGet = new HttpGet(url); CloseableHttpResponse response = client.execute(httpGet); System.out.println("获取豆瓣电影列表,返回验证码:" response.getStatusLine().getStatusCode()); if (response.getStatusLine().getStatusCode() == 200) { HttpEntity entity = response.getEntity(); String body = EntityUtils.toString(entity, "utf-8"); // 将请求结果格式化成JSON JSONObject jsonObject = JSON.parseObject(body); JSONArray data = jsonObject.getJSONArray("subjects"); for (int i = 0; i < data.size(); i ) { JSONObject movie = data.getJSONObject(i); movies.add(movie.getString("url")); } } response.close(); } catch (Exception e) { e.printStackTrace(); } finally { client.close(); } return movies; } } /** * 采集豆瓣电影线程 */ class CrawlMovieThread extends Thread { // 待采集链接 String url; public CrawlMovieThread(String url) { this.url = url; } public void run() { try { Connection connection = Jsoup.connect(url) thod(Connectionthod.GET) .timeout(50000); Connection.Response Response = connection.execute(); System.out.println("采集豆瓣电影,返回状态码:" Response.statusCode()); } catch (Exception e) { System.out.println("采集豆瓣电影,采集出异常:" e.getMessage()); } } }
这段程序的逻辑比较简单,先采集到豆瓣热门电影,这里使用直接访问 Ajax 获取豆瓣热门电影的链接,然后解析出电影的详情页链接,多线程访问详情页链接,因为只有在多线程的情况下才能达到豆瓣的访问要求。豆瓣热门电影页面如下:
多次运行上面的程序,你最后会得到下图的结果

从上图中我们可以看出,httpclient 访问返回的状态码为 403 ,说明我们已经没有权限访问该页面了,也就是说豆瓣网已经认为我们是爬虫程序啦,拒接掉了我们的访问请求。我们来分析一下我们现在的访问架构,因为我们是直接访问豆瓣网的,所以此时的访问架构如下图所示:

我们想要突破这层限制的话,我们就不能直接访问豆瓣网的服务器,我们需要拉入第三方,让别人代替我们去访问,我们每次访问都找不同的人,这样就不会被限制了,这个也就是所谓的 IP代理。 此时的访问架构就变成了下面这张图:

我们使用的 IP代理,我们就需要有 IP代理池,接下来我们就来聊一聊 IP 代理池
IP 代理池
代理服务器有很多厂商在做这一块,具体的我就不说了,自己百度 IP 代理可以搜出一大堆,这些 IP代理商都有提供收费和免费的代理 IP,收费的代理 IP可用性高,速度快,在线上环境如果需要使用代理的话,建议使用收费的代理 IP。如果只是自己研究的话,我们就可以去采集这些厂商的免费公开代理 IP,这些 IP 的性能和可用性都比较差,但是不影响我们使用。
因为我们是 Demo 项目,所以我们就自己搭建 IP代理池。我们该怎么设计一个 IP代理池呢?下图是我画的简单 IP代理池架构图

从上面的架构图中,可以看出一个 IP 代理系统会涉及到 4 个模块,分别为 IP 采集模块、 IP 存储模块、IP 检测模块和 API 接口模块。
- IP 采集模块
负责从各大 IP代理厂商采集代理 IP,采集的网站越多,代理 IP 的可用性就越高
- IP 存储模块
存储采集回来的代理 IP,比较常用的是 Redis 这样的高性能的数据库,在存储方面我们需要存储两种数据,一种是检测可用的代理 IP,另一种是采集回来还未检测的代理 IP。
- IP 检测模块
检测采集回来的 IP 是否可用,这样能够让我们提供的 IP 可用性变高,我们先过滤掉不可用的 IP。
- API 接口模块
以接口的形式对外提供可用代理 IP
上面就是关于 IP代理池的相关设计,对于这些我们只需要简单了解一下就行了,因为现在基本上不需要我们去编写 IP代理池服务啦,在 GitHub 上已经有大量优秀的开源项目,没必要重复造轮子啦。我为大家选取了在 GitHub 上有 8K star 的开源 IP代理池项目 proxy_pool ,我们将使用它作为我们 IP 代理池。关于 proxy_pool 请访问:github/jhao104/proxy_pool
部署 proxy_pool
proxy_pool 是用 python 语言写的,不过这也没什么关系,因为现在都可以容器化部署,使用容器化部署可以屏蔽掉一些环境的安装,只需要运行镜像就可以运行服务了,并不需要知道它里面的具体实现,所以这个项目不懂 Python 的 Java 程序员也是可以使用的。proxy_pool 使用的是 Redis 来存储采集的 IP,所以在启动 proxy_pool 前,你需要先启动 Redis 服务。下面是 proxy_pool docker启动步骤。
- 拉取镜像
docker pull jhao104/proxy_pool
- 运行镜像
docker run --env db_type=REDIS --env db_host=127.0.0.1 --env db_port=6379 --env db_password=pwd_str -p 5010:5010 jhao104/proxy_pool
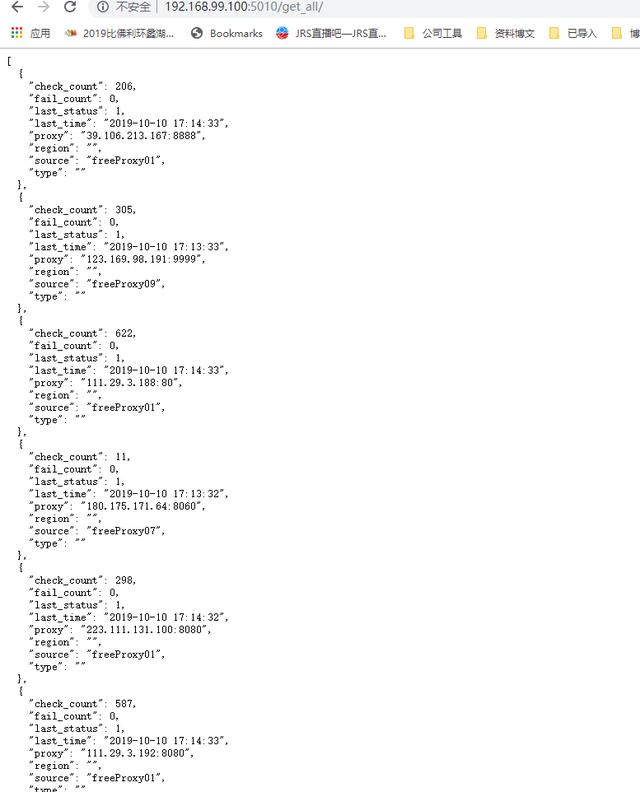
- 运行镜像后,我们等待一段时间,因为第一次启动采集数据和处理数据需要一段时间。等待之后访问 {your_host}:5010/get_all/,如果你得到下图所示的结果,说明 proxy_pool 项目你已经部署成功。
使用 IP 代理
搭建好 IP代理池之后,我们就可以使用代理 IP 来采集豆瓣电影啦,我们已经知道了除了 IP 之外,User Agent 请求头也会是豆瓣网判断访问是否是爬虫程序的一个因素,所以我们也对 User Agent 请求头进行伪造,我们每次访问使用不同的 User Agent 请求头。
我们为豆瓣电影采集程序引入 IP代理和 随机 User Agent 请求头,具体代码如下:
public class CrawlerMovieProxy { /** * 常用 user agent 列表 */ static List<String> USER_AGENT = new ArrayList<String>(10) { { add("Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19"); add("Mozilla/5.0 (Linux; U; Android 4.0.4; en-gb; GT-I9300 Build/IMM76D) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30"); add("Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"); add("Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0"); add("Mozilla/5.0 (Android; Mobile; rv:14.0) Gecko/14.0 Firefox/14.0"); add("Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36"); add("Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"); add("Mozilla/5.0 (iPad; CPU OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3"); add("Mozilla/5.0 (iPod; U; CPU like Mac OS X; en) AppleWebKit/420.1 (KHTML, like Gecko) Version/3.0 Mobile/3A101a Safari/419.3"); } }; /** * 随机获取 user agent * * @return */ public String randomUserAgent() { Random random = new Random(); int num = random.nextInt(USER_AGENT.size()); return USER_AGENT.get(num); } /** * 设置代理ip池 * * @param queue 队列 * @throws IOException */ public void proxyIpPool(LinkedBlockingQueue<String> queue) throws IOException { // 每次能随机获取一个代理ip String proxyUrl = "192.168.99.100:5010/get_all/"; CloseableHttpClient httpclient = HttpClients.createDefault(); HttpGet httpGet = new HttpGet(proxyUrl); CloseableHttpResponse response = httpclient.execute(httpGet); if (response.getStatusLine().getStatusCode() == 200) { HttpEntity entity = response.getEntity(); String body = EntityUtils.toString(entity, "utf-8"); JSONArray jsonArray = JSON.parseArray(body); int size = Math.min(100, jsonArray.size()); for (int i = 0; i < size; i ) { // 将请求结果格式化成json JSONObject data = jsonArray.getJSONObject(i); String proxy = data.getString("proxy"); queue.add(proxy); } } response.close(); httpclient.close(); return; } /** * 随机获取一个代理ip * * @return * @throws IOException */ public String randomProxyIp() throws IOException { // 每次能随机获取一个代理ip String proxyUrl = "192.168.99.100:5010/get/"; String proxy = ""; CloseableHttpClient httpclient = HttpClients.createDefault(); HttpGet httpGet = new HttpGet(proxyUrl); CloseableHttpResponse response = httpclient.execute(httpGet); if (response.getStatusLine().getStatusCode() == 200) { HttpEntity entity = response.getEntity(); String body = EntityUtils.toString(entity, "utf-8"); // 将请求结果格式化成json JSONObject data = JSON.parseObject(body); proxy = data.getString("proxy"); } return proxy; } /** * 豆瓣电影链接列表 * * @return */ public List<String> movieList(LinkedBlockingQueue<String> queue) { // 获取60条电影链接 String url = "movie.douban/j/search_subjects?type=movie&tag=热门&sort=recommend&page_limit=40&page_start=0"; List<String> movies = new ArrayList<>(40); try { CloseableHttpClient client = HttpClients.createDefault(); HttpGet httpGet = new HttpGet(url); // 设置 ip 代理 HttpHost proxy = null; // 随机获取一个代理IP String proxy_ip = randomProxyIp(); if (StringUtils.isNotBlank(proxy_ip)) { String[] proxyList = proxy_ip.split(":"); System.out.println(proxyList[0]); proxy = new HttpHost(proxyList[0], Integer.parseInt(proxyList[1])); } // 随机获取一个请求头 httpGet.setHeader("User-Agent", randomUserAgent()); RequestConfig requestConfig = RequestConfig.custom() .setProxy(proxy) .setConnectTimeout(10000) .setSocketTimeout(10000) .setConnectionRequestTimeout(3000) .build(); httpGet.setConfig(requestConfig); CloseableHttpResponse response = client.execute(httpGet); System.out.println("获取豆瓣电影列表,返回验证码:" response.getStatusLine().getStatusCode()); if (response.getStatusLine().getStatusCode() == 200) { HttpEntity entity = response.getEntity(); String body = EntityUtils.toString(entity, "utf-8"); // 将请求结果格式化成json JSONObject jsonObject = JSON.parseObject(body); JSONArray data = jsonObject.getJSONArray("subjects"); for (int i = 0; i < data.size(); i ) { JSONObject movie = data.getJSONObject(i); movies.add(movie.getString("url")); } } response.close(); } catch (Exception e) { e.printStackTrace(); } finally { } return movies; } public static void main(String[] args) { // 存放代理ip的队列 LinkedBlockingQueue<String> queue = new LinkedBlockingQueue(100); try { CrawlerMovieProxy crawlerProxy = new CrawlerMovieProxy(); // 初始化ip代理队列 crawlerProxy.proxyIpPool(queue); // 获取豆瓣电影列表 List<String> movies = crawlerProxy.movieList(queue); //创建固定大小的线程池 ExecutorService exec = Executors.newFixedThreadPool(5); for (String url : movies) { //执行线程 exec.execute(new CrawlMovieProxyThread(url, queue, crawlerProxy)); } //线程关闭 exec.shutdown(); } catch (Exception e) { e.printStackTrace(); } } } /** * 采集豆瓣电影线程 */ class CrawlMovieProxyThread extends Thread { // 待采集链接 String url; // 代理ip队列 LinkedBlockingQueue<String> queue; // 代理类 CrawlerMovieProxy crawlerProxy; public CrawlMovieProxyThread(String url, LinkedBlockingQueue<String> queue, CrawlerMovieProxy crawlerProxy) { this.url = url; this.queue = queue; this.crawlerProxy = crawlerProxy; } public void run() { String proxy; String[] proxys = new String[2]; try { Connection connection = Jsoup.connect(url) thod(Connectionthod.GET) .timeout(50000); // 如果代理ip队列为空,则重新获取ip代理 if (queue.size() == 0) crawlerProxy.proxyIpPool(queue); // 从队列中获取代理ip proxy = queue.poll(); // 解析代理ip proxys = proxy.split(":"); // 设置代理ip connection.proxy(proxys[0], Integer.parseInt(proxys[1])); // 设置 user agent connection.header("User-Agent", crawlerProxy.randomUserAgent()); Connection.Response Response = connection.execute(); System.out.println("采集豆瓣电影,返回状态码:" Response.statusCode() " ,请求ip:" proxys[0]); } catch (Exception e) { System.out.println("采集豆瓣电影,采集出异常:" e.getMessage() " ,请求ip:" proxys[0]); } } }
运行修改后的采集程序,可能需要多次运行,因为你的代理 IP 不一定每次都有效。代理 IP 有效的话,你将得到如下结果

结果中我们可以看出,40 次的电影详情页访问,有大量的代理 IP 是无效的,只有一小部分的代理 IP 有效。结果直接证明了免费的代理 IP 可用性不高,所以如果线上需要使用代理 IP 的话,最好使用收费的代理 IP。尽管我们自己搭建的 IP代理池可用性不是太高,但是我们设置的 IP 代理访问豆瓣电影已经成功了,使用 IP 代理成功绕过了豆瓣网的限制。
关于爬虫服务器被屏蔽,原因有很多,我们这篇文章主要介绍的是通过 设置 IP 代理和伪造 User Agent 请求头来绕过豆瓣网的访问限制。如何让我们的程序不被资源网站视为爬虫程序呢?需要做好以下三点:
- 伪造 User Agent 请求头
- 使用 IP 代理
- 不固定的采集间隔时间
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






