redis缓存穿透的解决方案(Redis缓存击穿穿透雪崩概念及解决方案)
缓存击穿是指一个请求要访问的数据,缓存中没有,但数据库中有。
这种情况一般来说就是缓存过期了。但是这时由于并发访问这个缓存的用户特别多,这是一个热点key,这么多用户的请求同时过来,在缓存里面都没有取到数据,所以又同时去访问数据库取数据,引起数据库流量激增,压力瞬间增大,直接崩溃给你看。
所以一个数据有缓存,每次请求都从缓存中快速的返回了数据,但是某个时间点缓存失效了,某个请求在缓存中没有请求到数据,这时候我们就说这个请求就"击穿"了缓存。

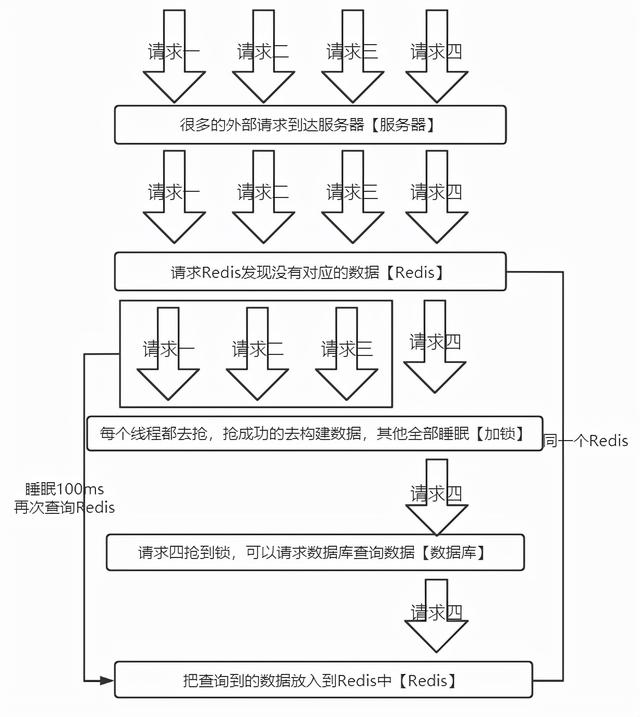
互斥锁方案的思路就是如果从redis中没有获取到数据,就让一个线程去数据库查询数据,然后构建缓存,其他的线程就等着,过一段时间后再从redis中去获取。
伪代码如下:
String get(String ycf) {
String music = redis.get(ycf);
if (music == null) {
//nx的方式设置一个key=ycf_lock,
//value=y_lock的数据,60秒后过期
if (redis.set("ycf_lock", "y_lock","nx",60)) {
//从数据库里获取数据
music = db.query(ycf);
//构建数据,24*60*60s后过期
redis.set(ycf, music,24*60*60);
//构建成功,可以删除互斥锁
redis.delete("ycf_lock");
} else {
//其他线程休息100ms后重试
Thread.sleep(100);
//再次获取数据,如果前面在100ms内设置成功,则有数据
music = redis.get(ycf);
}
}
}
这个方案能解决问题,但是一个线程构建缓存的时候,另外的线程都在睡眠或者轮询。
而且在这个四处宣讲高并发,低延时的时代,你居然让你的用户等待了宝贵的100ms。有可能别人比你快100ms,就抢走了大批用户。
2、方案二 后台续命后台续命方案的思想就是,后台开一个定时任务,专门主动更新即将过期的数据。
比如程序猿设置jay这个热点key的时候,同时设置了过期时间为60分钟,那后台程序在第55分钟的时候,会去数据库查询数据并重新放到缓存中,同时再次设置缓存为60分钟。
3、方案三 永不过期这个方案就有点简单粗暴了。
见名知意,如果结合实际场景你用脚趾头都能想到这个key是一个热点key,会有大量的请求来访问这个数据。对于这样的数据你还设置过期时间干什么?直接放进去,永不过期。

但是具体情况具体分析,没有一套方案走天下的。
比如,如果这个key是属于被各种"自来水"活生生的炒热的呢?就像哪吒一样,你预想不到这个key会闹出这么大的动静。这种情况你这么处理?
所以,具体情况,具体分析。但是思路要清晰,最终方案都是常规方案的组合或者变种。
二、缓存穿透缓存穿透的概念缓存穿透是指一个请求要访问的数据,缓存和数据库中都没有,而用户短时间、高密度的发起这样的请求,每次都打到数据库服务上,给数据库造成了压力。一般来说这样的请求属于恶意请求。

根据图片显示的,缓存中没有获取到数据,然后去请求数据库,没想到数据库里面也没有。
缓存穿透的解决方案1、方案一 缓存空对象缓存空对象就是在数据库即使查到的是空对象,我们也把这个空对象缓存起来。

缓存空对象,下次同样请求就会命中这个空对象,缓存层就处理了这个请求,不会对数据库产生压力。
这样实现起来简单,开发成本很低。但这样随之而来的问题必须要注意一下:
第一个问题:如果在某个时间,缓存为空的记录,在数据库里面有值了,你怎么办?
我知道三个解决方法:
解决方法一:设置缓存的时候,同时设置一个过期时间,这样过期之后,就会重新去数据库查询最新的数据并缓存起来。
解决方法二:如果对实时性要求非常高的话,那就写数据库的时候,同时写缓存。这样可以保障实时性。
解决方法三:如果对实时性要求不是那么高,那就写数据库的时候给消息队列发一条数据,让消息队列再通知处理缓存的逻辑去数据库取出最新的数据。
第二个问题:对于恶意攻击,请求的时候key往往各不相同,且只请求一次,那你要把这些key都缓存起来的话,因为每个key都只请求一次,那还是每次都会请求数据库,没有保护到数据库呀?
这个时候,你就告诉他:"布隆过滤器,了解一下"。
2、方案二 布隆过滤器什么是布隆过滤器?
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
所以布隆过滤器返回的结果是概率性的,所以它能缓解数据库的压力,并不能完全挡住,这点必须要明确。
guava组件可以开箱即用的实现一个布隆过滤器,但是guava是基于内存的,所以不太适用于分布式环境下。
要在分布式环境下使用布隆过滤器,那还得redis出马,redis可以用来实现布隆过滤器。
看到了吗,redis不仅仅是拿来做缓存的。这就是一个知识点呀。
三、缓存雪崩缓存雪崩的概念缓存雪崩是指缓存中大多数的数据在同一时间到达过期时间,而查询数据量巨大,这时候,又是缓存中没有,数据库中有的情况了。请求都打到数据库上,引起数据库流量激增,压力瞬间增大,直接崩溃给你看。
和前面讲的缓存击穿不同的是,缓存击穿指大量的请求并发查询同一条数据。
缓存雪崩是不同数据都到了过期时间,导致这些数据在缓存中都查询不到,
或是缓存服务直接挂掉了,所以缓存都没有了。
总之,请求都打到了数据库上。对于数据库来说,流量雪崩了,很形象。
缓存雪崩的解决方案1、方案一 加互斥锁如果是大量缓存在同一时间过期的情况,那么我们可以加互斥锁。
等等,互斥锁不是前面介绍过了吗?
是的,缓存雪崩可以看成多个缓存击穿,所以也可以使用互斥锁的解决方案,这里就不再赘述。
2、方案二 "错峰"过期如果是大量缓存在同一时间过期的情况,我们还有一种解决方案就是在设置key过期时间的时候,在加上一个短的随机过期时间,这样就能避免大量缓存在同一时间过期,引起的缓存雪崩。
比如设置一类key的过期时间是10分钟,在10分钟的基础上再加上60秒的随机事件,就像这样:
3、方案三 缓存集群
redis.set(key,value,10*60 RandomUtils.nextInt(0, 60),TimeUnit.SECONDS)如果对于缓存服务挂掉的情况,大多原因是单点应用。那么我们可以引入redis集群,使用主从加哨兵。用Redis Cluster部署集群很方便的,可以了解一下。
当然这是属于一种事前方案,在使用单点的时候,你就得考虑服务宕机后引起的问题。所以,事前部署集群,提高服务的可用性。
4、方案四 限流器 本地缓存那你要说如果Cluster集群也挂了怎么办呢?其实这就是对服务鲁棒性的考虑:
鲁棒性(robustness)就是系统的健壮性。它是指一个程序中对可能导致程序崩溃的各种情况都充分考虑到,并且作相应的处理,在程序遇到异常情况时还能正常工作,而不至于死机。
这个时候,可以考虑一下引入限流器,比如 Hystrix,然后实现服务降级。
假设你的限流器设置的一秒钟最多5千个请求,那么这个时候来了8千个请求,多出来的3000个就走降级流程,对用户进行友好提示。
进来的这5000个请求,如果redis挂了,还是有可能会干翻数据库的,那么这个时候我们在加上如果redis挂了,就查询类似于echcache或者guava cache本地缓存的逻辑,则可以帮助数据库减轻压力,挺过难关。
5、方案五 尽快恢复这个没啥说的了吧?
大哥,你服务挂了诶?赶紧恢复服务啊。
,



免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






