基本的python内置函数range(大数据分析Python内置函数range使用教程)
循环是任何编程语言的组成部分。在大数据分析Python中,循环的重要组成部分是内置range函数。
在本详细指南中,我们将通过range示例向您介绍该函数的工作原理,并讨论其局限性及其解决方法。尽管range对于各种各样的大数据分析Python编程任务很有用,但本指南将以该range函数的几个数据科学用例作为结尾。
就本教程而言,我们假定您至少了解一些大数据分析Python语法。如果您以前从未使用过大数据分析Python,建议您先从此交互式大数据分析Python基础知识课程开始。
大数据分析Python范围简史
本教程的重点是大数据分析Python 3,但是如果您在使用大数据分析Python 2之前已经进行过一些解释,因为range这两个版本之间的含义有所变化。
range大数据分析Python 2中 的函数生成了一个可以迭代的数字列表。因此,对于大列表大小,此过程占用了大量内存。xrange大数据分析Python 2中的函数通过惰性求值返回项目,这意味着仅在需要时才生成数字,从而使用更少的内存。
xrange大数据分析Python 2中 的函数range在大数据分析Python 3 中重命名,而range大数据分析Python 2中的函数已弃用。在本教程中,我们正在使用range大数据分析Python 3 的功能,因此它在与range大数据分析Python 2 相关时不会出现性能问题。
大数据分析Python范围:基本用途
让我们首先来看一下for循环和range大数据分析Python中函数的基本用法。让我们打印前五个整数。

上面的代码段循环显示数字0到4。请注意,这五个未包含在循环中。range因此,的基本用途是遍历数字列表。我们将range很快重新讨论范围。
我们可以使用三个参数range:开始,停止和步进。我们可以如下说明这三个:
1)range(stop):这会创建一个范围从零到小于终止号的数字范围,并增加一个。
2)范围(开始,停止):这会创建一个范围从开始编号到小于结束编号的数字范围,并增加一个。
3)范围(开始,停止,步进):这会创建一个范围从开始编号到小于停止编号的数字,并逐步递增。
上面的简单示例使用了声明range函数的第一种方式。让我们探索另外两种方式。

请注意,起始编号包含在范围内,而终止编号不包含在范围内。

在这种第三种声明方式中range,我们从起始编号开始,然后加三(步骤编号),直到达到终止编号。
范围:数据类型
让我们检查range函数返回的对象的类型。

请注意,这range是大数据分析Python中的一种类型。该类的默认打印方法将打印范围对象将迭代通过的数字范围。请注意,仍未生成数字-这是由于前面提到的节省内存的“惰性评估”。仅当数字以某种方式实际使用时才会生成数字(例如,如上所述,在print函数中被调用)。

范围对象:高级用途
有趣的是,我们可以通过范围对象的索引访问范围对象,就像使用列表一样。我们范围内的第三个对象是2。

像列表一样,我们也可以切片范围对象。这将返回一个新的范围对象!

我们也可以使用reversed()适用于列表的相同功能来反转范围对象。

范围可用于生成负数。

我们还可以定义一个负阶跃函数来按递减顺序生成数字,而不是使用该reversed函数。

请注意,如果您使用带有的step参数range,则该参数不能为零(这将导致无限循环并因此引发ValueError)。
此外,如果从您的开始参数开始计数永远不会到达您的结束参数,range则不会返回任何内容。请注意,当我们运行下面的代码时,不会打印任何内容,因为如果我们从17开始并递增计数,则永远无法达到指定的end参数10:

带浮点数的范围对象
范围功能不适用于浮点数。只能将整数值指定为开始,停止和步骤参数。

但是,如果需要使用浮点数生成类似范围的收益,则有两种解决方法。
首先,我们可以定义一个具有三个参数的简单函数,该函数逐步增加起始编号,直a到达到停止为止:
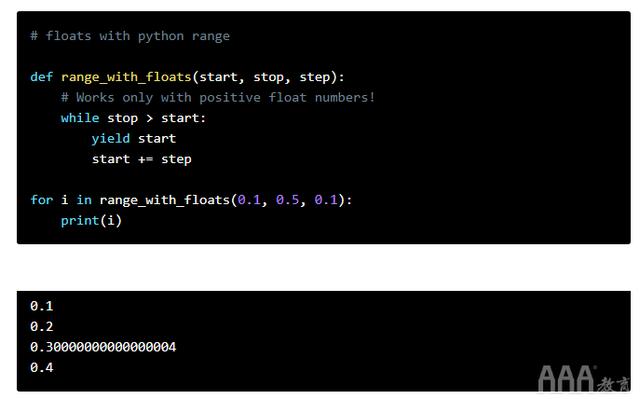
我们也可以使用NumPy从NumPy的arange()函数中获得相同的结果。
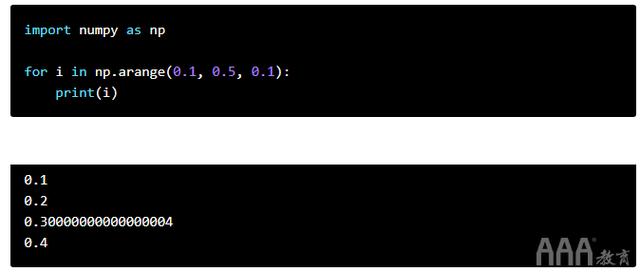
这个数字0.30000000000000004是哪里来的?系统仅存储浮点数的近似值。因此,如果要生成更清晰的输出,则在处理像这样的浮点数时可能需要使用该round()函数。

在数据科学中使用大数据分析Python的范围函数
读取大文件
在数据科学中,大数据分析Python的range函数的一种用途是在读取大型文件时。
例如,考虑一下 UCI提供的1985年的汽车进口数据集。该文件为CSV格式,其中值之间用逗号分隔。下载文件并使用open()功能打开它。让我们使用该.readline()方法打印前五行。

在头文件描述列名。最后一列包含汽车进口价格。如果我们浏览文件的前几行,则会注意到丢失的项目存储为问号(?)。
每条打印行之间以换行符(\n)结尾的行之间有一个空行。我们将需要在下面的分析中考虑这一点。让我们检查文件中存在多少行。在UNIX终端中,可以将命令wc -l以文件名作为参数来计算行数。如果使用的是Jupyter笔记本,则可以在命令前使用感叹号,以从单元格中运行终端命令。

利用205行数据,让我们尝试在数据集中查找价格最高的汽车进口和汽车的行号。首先,我们将循环遍历文件长度。接下来,使用.readline()方法读取该行,在每行末尾去除换行符,然后使用split()函数将该行转换为项目列表。
清单的最后一项是汽车进口价格。如果价格缺失,我们将遍历下一个项目。如果价格高于我们的价格max_price,则我们更改的值max_price并更新存储在变量中的行号max_price_loc。

1985年最昂贵的汽车售价为45400美元,按通胀率计算的2019年美元汇率约为108000美元。
Web爬网时遍历页面
范围函数在数据科学中的另一个用途是从某些网站进行Web抓取。
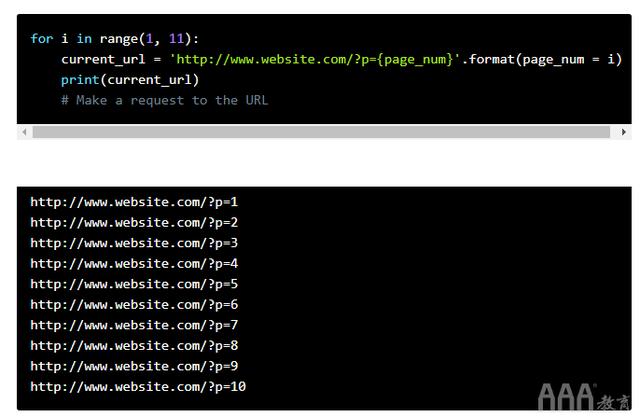
例如,假设我们要从BBS论坛中提取数据。通常,帖子分布在大量页面上,而页面编号包含在URL中。大数据分析Python内置函数range使用教程https://www.aaa-cg.com.cn/data/2297.html无需一次输入每个页面URL,我们可以一次输入URL并通过用range函数产生的每个数字替换URL中的页面号来遍历每个页面。
例如,如果我们要向URL格式为的页面发送请求http://www.website.com/?p=page_number,则可以使用range依次生成每个URL。在下面的示例中,我们获得了前十个页面的URL,但是可以使用此技术快速生成成百上千个URL,然后您就可以逐个抓取内容,而不必在您的网站中放置多个URL码。
在大数据分析Python内置函数range使用教程中,我们学习了使用该range()函数的一些不同方式,并看到了一些有关如何在数据科学工作中特别有用的示例。
如果您使用数据,range()不一定每天都会使用该功能,但是在某些情况下,一定要牢牢掌握其工作方式可以节省大量时间和精力。
相关推荐
数据工程师数据分析师和数据科学家区别与联系 R语言的学习方法大数据分析Python建立分析数据管道Excel或Python如何执行大数据分析任务大数据分析培训课程教学指南,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com