关于机器人的英语思维导读图(注意力的动画解析)
本文为 AI 研习社编译的技术博客,原标题 :
Attn: Illustrated Attention
作者 | Raimi Karim
翻译 | yata 校对 | 邓普斯•杰弗
审核 | 酱番梨 整理 | Pita
原文链接:
https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3
近十年以来,直到神经机器翻译系统的诞生之前,统计机器翻译一直在机器翻译领域占据着主要地位。神经机器翻译模型作为一种新兴的机器翻译方法,其致力于构建并训练出一个可以输入文本并返回翻译文本的大型神经网络。
Kalchbrenner and Blunsom (2013), Sutskever et. al (2014) 和Cho. et. al (2014b)等人,作为先驱首先提出了神经机器翻译框架,之后由Sutskever 等人提出了更广为人知的序列到序列模型。我们这篇文章将基于序列到序列的框架,以及如何在此框架上构建attention机制,来展开讲解。
Fig. 0.1: 输入序列长度为4的序列到序列的框架
在序列到序列模型中,其主要的思想在于使用两个循环神经网络构建一个编码器-解码器的结构:首先以其中一个RNN为构成的编码器,按时间顺序一个一个读入输入的文字,之后便可以得到一个固定维度的向量;在这些输入的基础上,由另一个RNN构成的解码器按照时间顺序再进行一个一个的解码,从而得到最后的翻译。我们的解释借鉴了[5]。
Fig. 0.2: 输入序列长度为64的序列到序列框架
序列到序列模型的主要问题在于,编码器的最后一个隐层状态(见Fig.0.1中的两个红色节点),作为唯一的信息输入到解码器中来。而这最后一个隐层状态向量就好像是全部输入的一个数值汇总。所以当输入的文字很长时(Fig.0.2),仅仅利用一个汇总向量(期望他可以充分的总结输入序列的所有信息),便希望可以输出一个合理的翻译文本,便显得有些不合理,因为汇总向量的表达能力的受限,这必然会导致对输入文本灾难性的“遗忘”。这就好比给你一个由一百多个单词组成的段落,然后希望你可以在阅读完最后一个词之后,立马给出这个段落的翻译,你可以做到吗?
如果我们都做不到,我们也不应该奢求解码器能够做到。那么我们为何不考虑让解码器使用编码器部分每一个时刻的隐层状态,而不是单单只是使用编码器部分最后一个隐层状态,这样子我们应该会得到更好的翻译文本。这就要引入attention机制了。
Fig 0.3:在编码器和解码器中间加入attention机制。这里,在给出第一个翻译词汇之前,解码器就已经从解码器得到了第一个时间步长的输入信息(初始化状态)。
注意力作为编码器和解码器之间的接口,负责将编码器部分每一个时刻的隐状态提供给解码器(其中不包括在Fig.0.3中的标红的隐状态)。在这样的设定下,模型才有能力去聚焦在输入序列中有用的部分,并且从中学到输入文本与输出翻译文本之间的对齐(alignment)。这对于模型有效的处理长输入句子十分有效。
定义:对齐
对齐的意思是将原始输入文本中的片段与他们对应输出的翻译文本片段,进行匹配。
Fig.0.3:法文"la"与输入序列之间的对齐分布在输入序列中各个单词上,但是主要在其中四个单词:"the","European","Economic"和"Area"。连线的颜色越深表示attention的score越大。
在[2]中的介绍我们可以直到,这里有种形式的attention.一种是,使用编码器的所有隐层状态,我们称其为全局attention。相对的,只使用编码器隐层状态的子集来计算attention,我们将其称为局部attention。在这篇文章中,我们讨论的是全局attention。其中提到attention时大家就默认为全局attention.
在这篇文章中,我们使用动画的形式进行对attention的工作原理进行总结,所以大家再也不用对着论文或者资料里的各种数学表达式发愁了。同时作为例证,我将介绍在过去五年里发表的四种神经机器翻译的框架。并且我将在文章中为对其中的一些概念理论进行直观推断式的讲解,所以大家要注意这些讲解哦。
目录
1.Attention:综述
2.Attention:例子
3.总结
附录:attention分数计算方法
1.Attention:综述
在我们讨论attention如何使用之前,首先允许我使用直观理解的方式,解释如何将序列到序列模型运用到翻译任务上。
直观理解:序列到序列模型
一名翻译员从头到尾的读一段德语文本,一旦他读完这段文本,便开始将其逐词的翻译为英文。当这段文本很长时,他极有可能在翻译过程中已经忘记了这段文本之前的段落。
当然,上面我们说的只是一个简单的序列到序列模型。下面我将带大家厘清在序列到序列 attention模型中attention层中计算的具体步骤。在这之前,让我们首先对模型有一个直观理解。
直观理解:序列到序列 attention
一名翻译员从头到尾去读一段德语文本,只是在读的过程中,会记下来文本中涉及到的关键词。这样在之后翻译工作时,他可以在翻译每个德语单词时借鉴他在之前已经记下的关键词。
attention通过向不同的单词赋予不同的分数来表征 不同的关注程度。之后,将这些得到的分数经过softmax层(从而拿到归一化的权重),这样我们就可以将编码器阶段所有的隐层状态经过加权和得到一个上下文向量。attention层具体的实现可以分解为如下四个步骤。
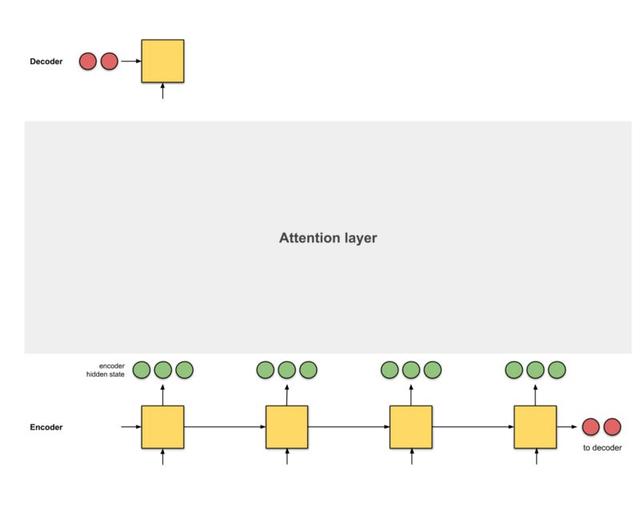
Step 0:准备隐层状态
我们要首先准备好decoder的(当前)隐层状态(红色)和所有可以拿到的编码器隐层状态(绿色)。在我们的例子中,我们有4个编码器隐层状态和一个当前解码器隐层状态。
Fig.1.0 准备关注
Step 1: 获得对每个编码器隐层状态的分数
分数(标量)可以通过分数函数(或者叫做对齐分数函数[2]或者对齐模型)得到。在这个例子中,我们使用解码器和编码器隐层状态之间的点积作为我们的分数计算函数。
附录A中给了不同的分数计算函数。
Fig. 1.1:分数获得
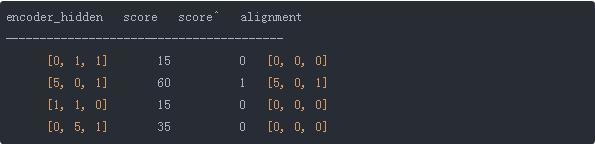
在上面这个例子中,我们在编码器隐层状态[5, 0, 1]中得到了较高的分数,这意味着下一个要翻译的单词将较大的收到这个隐层状态的影响。
Step 2 : 将所有的分数值通过一个softmax层
我们将这些分数通过一个softmax层,这样我们可以得到对应的加起来为1的值。这些经过了softmax层的分数代表了[3,10]的注意力分布。
Fig.1.2 softmaxed 分数
我们可以看到,在经过了softmax的分数score^,attention按我们的预期只分布在[5, 0, 1]上。实际上,这些数应该是0到1之间的浮点数而不是0和1的二值数。
Step 3: 将每个编码器隐状态乘以softmax层之后的分数值
通过将每个编码器的隐层状态乘上对应的softmax之后的分数值,我们就可以得到对齐向量[2]或者叫做标注向量[1]。这就是对齐的机制。
Fig. 1.3: Get the alignment vectors
这里我们可以看到除了[5, 0, 1]之外的其他隐层状态都因为其分数小的原因降至0。这意味着我们可以认为第一个被翻译出的单词应该匹配着输入单词中的[5,0,1]编码向量。
Step 4: 将所有的对齐向量相加
将所有的对齐向量相加即可得到最终的上下文向量[1,2]。一个上下文向量相当于是之前所有步骤中的对齐向量的聚合信息。
Fig. 1.4: Get the context vector
Step 5: 将上下文向量输入解码器部分
(输入解码器的)方式由我们的框架设计所决定。之后我们将在Section 2a,2b,和2c中通过例子介绍这些框架如何在解码器部分使用上下文向量信息。
Fig. 1.5: Feed the context vector to decoder
下面是整个动态的过程。
Fig. 1.6: Attention
直观理解:attention到底是如何有效的
答案:反向传播,惊喜吗?反向传播会尽其可能的去让输出接近真实答案。它需要去不断的调整RNN网络中的权值以及对应的函数方程中的权值,如果有需要的话。这些权重会去影响编码器的隐层状态和解码器的隐层状态,从而间接的去影响attention的分数。
2. Attention:例子
我们在之前的章节中已经了解了序列到序列和序列到序列 attention两种框架。在下一小节中,我们将详细的去了解3个在序列到序列基础上运用attention机制的神经机器翻译模型。为了让大家更为完整的了解(他们的具体性能),我将附上他们的双语评估分数(BLEU)——一种在真实序列基础上评价合成序列的指标。
2a. Bahdanau 等(2015)[1]
这种attention的计算实现是基础attention计算的来源之一。作者在论文题目"Neural Machine Translation by Learning to Jointly Align and Translate"中用了"align"(对齐)这和词,以此来表示在训练模型时去调整跟分数直接相关的权重。下面是对此框架的一些要点总结:
1.编码器是由双向(前向 反向)的门限循环单元(BiGRU)。解码器是由一个单向的GRU组成,它的初始化状态是由编码器的反向GRU的最后一个隐层状态变换而来。(这一点没有在下面的图中体现)
2.attention层分数的计算方式是 加/串联
3.机器码器下一个时刻的输入是由上一步解码器的输出(粉色)和当前时刻的上下文向量(深绿)串联。
Fig. 2a: NMT from Bahdanau et. al. Encoder is a BiGRU, decoder is a GRU.
作者在WMT14英-法数据集上BLEU值达到了26.75。
直观理解:由双向编码器组成的序列到序列模型 attention机制
译者A像之前我们说的那样边读边写下关键词。译者B(他属于高级译者,有可以从后往前读文章并可以进行翻译的能力)从最后一个词开始从后往前阅读,并且也做关键词的记录。这样两个人会不断的讨论他们阅读到的内容,一旦阅读完整段德语文本,译者B被要求依据他们之前讨论的内容以及他们共同整理的关键词,将德文逐词的翻译为英文。
译者A是前向RNN,译者B是反向RNN。
2b. Luong等(2015)[2]
Effective Approaches to Attention-based Neural Machine Translation的作者将Bahdanau等的框架进行了泛化,并且进行了简化。下面我们看下它的主要结构:
1.编码器是一个两层的长短时记忆网络(LSTM)。解码器也有着相同的网络框架,同时它的隐状态的初始化来自编码器的最后一个隐层状态。
2.他们在实验过的分数方程有(i)加/串联,(ii)点乘,(iii)基于位置的 和(iv)一般化的。
3.当前时刻解码器的最终输出(粉色),由当前时刻解码器部分的输出(译者注:解码器部分LSTM的输出或隐层状态)和当前时刻计算得到的上下文向量进行串联,之后经过一层全连接网络得到。
Fig. 2b: NMT from Luong et. al. Encoder is a 2 layer LSTM, likewise for decoder.
此模型在WMT15 英语-法语数据集上BLEU分数达到了25.9.
直观理解:带有两层(LSTM)堆叠编码器的序列到序列模型 attention
译者A从前至后阅读德语文本,并写下遇到的关键词。同样的,译者B(比译者A的级别要高)同样阅读这段德语文本,并且记下关键词。注意在这个过程中,译者A每读一个词就向译者A进行汇报。当文本阅读结束后。两位译者会基于他们之前共同得到的关键词进行逐词的翻译。
2c. 谷歌的神经机器翻译模型(GNMT)[9]
我们中的大多数应该都曾经以各种形式使用过谷歌翻译,所以我觉得十分有必要来讨论2016年实现的谷歌神经机器翻译系统。GNMT是我们看到的前两个例子的结合(深受第一个例子[1]的启发)。
1.编码器部分由八层LSTM堆叠而成,其中第一层是双向的(双向的输出进行串联),并且从第三层开始会进行连续的残差连接。解码器部分由8层单向的LSTM堆叠而组成。
2.分数计算函数使用的 加/串联,和文献[1]一样。
3.同样的,和文献[1]相同,解码器当前时刻的输入由上一个时刻解码器的输出(粉色)和当前时刻的上下文向量(深绿)串联而得。
Fig. 2c: Google’s NMT for Google Translate. Skip connections are denoted by curved arrows. *Note that the LSTM cells only show the hidden state and input; it does not show the cell state input.
该模型在WMT14英-法数据库上BLEU分数达到了38.95,在WMT14英-德数据库上BLEU的值达到了24.17.
直观理解:GNMT——有八层LSTM堆叠而成编码器的序列到序列模型( 双向 残差连接) attention
八个译者依次坐好,顺序是从A到B直到H。每个译者都读着相同的德语文本。在每个词上,译者A向译者B分享他的发现,译者B会改善得到的信息并将它分享给译者C,重复这样的过程直到告诉译者H。同样的,译者H会在读这段德文文本时,基于它获得的信息写下相关的关键词。
一旦每个人都读完了这段德文文本,译者A会被告知去翻译第一个词。首先他开始回想,然后他将他的答案分享给B,B改进答案后分享给C,重复这个过程直到传递给了H。然后译者H会基于他得到的答案和之前记录下的关键词,写下第一个翻译出来的单词。他会重复这个过程直到整个翻译内容结束。
3. 总结
这里我们对你在这篇文章里见过的所有架构做一个快速的总结。
序列到序列模型
序列到序列模型 attention
有双向编码器的序列到序列模型 attention
有两层(lstm)堆叠编码器的序列到序列模型 attention
GNMT-有八层堆叠编码器的序列到序列模型( 双向 残差) attention。
以上就是所有的内容。在下一篇博客中,我将为你讲述什么是self-attention,并且讲述它是怎样应用到谷歌的Transformer和self-Attention对抗神经网络模型上的。请密切关注我的空间!
附录:分数函数
下面是Lilian Weng编辑的分数函数中的一部分。加/串联 和 点乘在这篇文章中已经被提及。其中包含了点乘操作(点乘,余弦距离等)的分数函数,其主旨是为了度量两个向量之间的相似性。对于使用前馈神经网络的分数函数,其主旨是对翻译译文的对齐权重进行建模。
Fig. A0: Summary of score functions
Fig. A1: Summary of score functions. (Image source)
References
[1] Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et. al, 2015)
[2] Effective Approaches to Attention-based Neural Machine Translation (Luong et. al, 2015)
[3] Attention Is All You Need (Vaswani et. al, 2017)
[4] Self-Attention GAN (Zhang et. al, 2018)
[5] Sequence to Sequence Learning with Neural Networks (Sutskever et. al, 2014)
[6] TensorFlow’s seq2seq Tutorial with Attention (Tutorial on seq2seq attention)
[7] Lilian Weng’s Blog on Attention (Great start to attention)
[8] Jay Alammar’s Blog on Seq2Seq with Attention (Great illustrations and worked example on seq2seq attention)
[9] Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation (Wu et. al, 2016)
Related Articles on Deep Learning
Animated RNN, LSTM and GRU
Line-by-Line Word2Vec Implementation (on word embeddings)
Step-by-Step Tutorial on Linear Regression with Stochastic Gradient Descent
10 Gradient Descent Optimisation Algorithms Cheat Sheet
Counting No. of Parameters in Deep Learning Models
想要继续查看本篇文章相关链接和参考文献?
长按链接点击打开或点击【注意力的动画解析(以机器翻译为例)】:
https://ai.yanxishe.com/page/TextTranslation/1460
AI研习社每日更新精彩内容,观看更多精彩内容:雷锋网雷锋网雷锋网
CVPR 2018 最牛逼的十篇论文
深度学习目标检测算法综述
迷你自动驾驶汽车深度学习特征映射的可视化
在2018年用“笨办法”学数据科学体会分享
等你来译:
如何在神经NLP处理中引用语义结构
(Python)用Mask R-CNN检测空闲车位
高级DQNs:利用深度强化学习玩吃豆人游戏
深度强化学习新趋势:谷歌如何把好奇心引入强化学习智能体
,

















免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






