Oracle RAC讲解(详解Oracle中常见的Hint)
Oracle中的Hint可以用来调整SQL的执行计划,提高SQL执行效率。下面分类介绍Oracle数据库中常见的Hint。这里主要介绍Oracle11gR2中的常见Hint。像我们在做优化的时候,如果一个sql执行效率比较低,我们可以用不同的hint来看下执行计划,对比选择最优的hint,如果CBO选择了不好的执行计划,就要考虑是不是没对表做统计分析了...
一、与优化器模式相关的Hint
1、ALL_ROWS
ALL_ROWS是针对整个目标SQL的Hint,它的含义是让优化器启用CBO,而且在得到目标SQL的执行计划时会选择那些吞吐量最佳的执行路径。这里的“吞吐量最佳”是指资源消耗量(即对I/O、CPU等硬件资源的消耗量)最小,也就是说在ALL_ROWS Hint生效的情况下,优化器会启用CBO而且会依据各个执行路径的资源消耗量来计算它们各自的成本。
ALL_ROWS Hint的格式如下:
/* ALL_ROWS */
set line 200 set autotrace on select /* all_rows */ empno,ename,sal,job from emp where empno=7396;

从Oracle10g开始,ALL_ROWS就是默认的优化器模式,启用的就是CBO。
show parameter optimizer_mode;

如果目标SQL中除了ALL_ROWS之外还使用了其他与执行路径、表连接相关的Hint,优化器会优先考虑ALL_ROWS。
2、FIRST_ROWS(n)
FIRST_ROWS(n)是针对整个目标SQL的Hint,它的含义是让优化器启用CBO模式,而且在得到目标SQL的执行计划时会选择那些能以最快的响应时间返回头n条记录的执行路径,也就是说在FIRST_ROWS(n) Hint生效的情况下,优化器会启用CBO,而且会依据返回头n条记录的响应时间来决定目标SQL的执行计划。
FIRST_ROWS(n)格式如下:
/* FIRST_ROWS(n) */
select /* first_rows(10) */ empno,ename,sal,job from emp where deptno=30;


上述SQL中使用了/* first_rows(10) */,其含义是告诉优化器我们想以最短的响应时间返回满足条件"deptno=30"的前10条记录,并不是只返回10条,这里需要注意。
注意,FIRST_ROWS(n) Hint和优化器模式FIRST_ROWS_n不是一一对应的。优化器模式FIRST_ROWS_n中的n只能是1、10、100、1000。但FIRST_ROWS(n) Hint中的n还可以是其他值。
3、RULE(基本不用)
RULE是针对整个目标SQL的Hint,它表示对目标SQL启用RBO。
格式如下:
/* RULE */
select /* rule */ empno,ename,sal,job from emp where deptno=30;

RULE不能与除DRIVING_SITE以外的Hint联用,当RULE与除DRIVING_SITE以外的Hint联用时,其他Hint可能会失效;当RULE与DRIVING_SITE联用时,它自身可能会失效,所以RULE Hint最好是单独使用。
一般情况下,并不推荐使用RULE Hint。一来是因为Oracle早就不支持RBO了,二来启用RBO后优化器在执行目标SQL时可选择的执行路径将大大减少,很多执行路径RBO根本就不支持(比如哈希连接),就也就意味着启用RBO后目标SQL跑出正确执行计划的概率将大大降低。
二、与表访问相关的Hint
1、FULL
FULL是针对单个目标表的Hint,它的含义是让优化器对目标表执行全表扫描。
格式如下:
/* FULL(目标表) */
select /* full(emp) */ empno,ename,sal,job from emp where deptno=30;

上述SQL中Hint的含义是让优化器对目标表EMP执行全表扫描操作,而不考虑走表EMP上的任何索引(即使列EMPNO上有主键索引)。
2、ROIWD
ROIWD是针对单个目标表的Hint,它的含义是让优化器对目标表执行RWOID扫描。只有目标SQL中使用了含ROWID的where条件时ROWID Hint才有意义。
格式如下:
/* ROWID(目标表) */
select /* rowid(emp) */ empno,ename,sal,job from emp where rowid='AAAR3xAAEAAAACXAAN';

Oracle 11gR2中即使使用了ROWID Hint,Oracle还是会将读到的块缓存在Buffer Cache中。
三、与索引访问相关的Hint
1、INDEX
INDEX是针对单个目标表的Hint,它的含义是让优化器对目标表的的目标索引执行索引扫描操作。
INDEX Hint中的目标索引几乎可以是Oracle数据库中所有类型的索引(包括B树索引、位图索引、函数索引等)。
INDEX Hint的模式有四种:
格式1 /* INDEX(目标表 目标索引) */ 格式2 /* INDEX(目标表 目标索引1 目标索引2 …… 目标索引n) */ 格式3 /* INDEX(目标表 (目标索引1的索引列名) (目标索引2的索引列名) …… (目标索引n的索引列名)) */ 格式4 /* INDEX(目标表) */
格式1表示仅指定了目标表上的一个目标索引,此时优化器只会考虑对这个目标索引执行索引扫描操作,而不会去考虑全表扫描或者对该目标表上的其他索引执行索引扫描操作。
格式2表示指定了目标表上的n个目标索引,此时优化器只会考虑对这n个目标索引执行索引扫描操作,而不会去考虑全表扫描或者对该目标表上的其他索引执行索引扫描操作。注意,优化器在考虑这n个目标索引时,可能是分别计算出单独扫描各个目标索引的成本后,再选择其中成本值最低的索引;也可能是先分别扫描目标索引中的两个或多个索引,然后再对扫描结果执行合并操作。当然,后面这种可能性的前提条件是优化器计算出来这样做的成本值是最低的。
格式三也是表是指定了目标表上的n个目标索引,只不过此时是用指定目标索引的索引列名来代替对应的目标索引名。如果目标索引是复合索引,则在用于指定该索引列名的括号内也可以指定该目标索引的多个索引列,各个索引列之间用空格分隔就可以了。
格式的表示指定了目标表上所有已存在的索引,此时优化器只会考虑对该目标表上所有已存在的索引执行索引扫描操作,而不会去考虑全表扫描操作。注意,这里优化器在考虑该目标表上所有已存在的索引时,可能是分别计算出单独扫描这些索引的成本后再选择其中成本值最低的索引;也可能是先分别扫描这些索引中的两个或多个索引,然后再对扫描结果执行合并操作。当然,后面这种可能性的前提条件是优化器计算出来这样做的成本值是最低的。
select /* index(emp pk_emp) */ empno,ename,sal,job from emp where empno=7369 and mgr=7902 and deptno=20; select /* index(emp pk_emp idx_emp_mgr idx_emp_dept) */ empno,ename,sal,job from emp where empno=7369 and mgr=7902 and deptno=20; select /* index(emp (empno) (mgr) (deptno)) */ empno,ename,sal,job from emp where empno=7369 and mgr=7902 and deptno=20; select /* index */ empno,ename,sal,job from emp where empno=7369 and mgr=7902 and deptno=20;



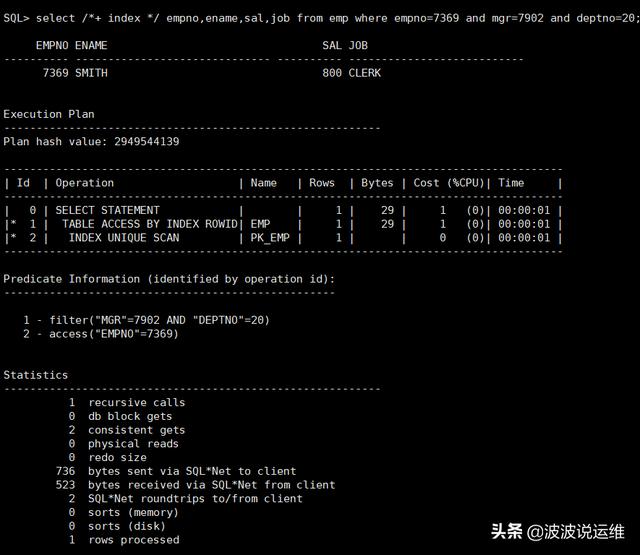
2、NO_INDEX
NO_INDEX是针对单个目标表的Hint,它是INDEX的反义Hint,其含义是让优化器不对目标表上的目标索引执行扫描操作。
INDEX Hint中的目标索引也几乎可以是Oracle数据库中所有类型的索引(包括B树索引、位图索引、函数索引等)。
格式有如下三种:
格式1 /* NO_INDEX(目标表 目标索引) */ 格式2 /* NO_INDEX(目标表 目标索引1 目标索引2 …… 目标索引n) */ 格式3 /* NO_INDEX(目标表) */
格式1表示仅指定了目标表上的一个目标索引,此时优化器只是不会考虑对这个目标索引执行索引扫描操作,但还是会考虑全表扫描或者对该目标表上的其他索引执行索引扫描操作。
格式2表示指定了目标表上的n个目标索引,此时优化器只是不会考虑对这n个目标索引执行索引扫描操作,但还是会考虑全表扫描或者对该目标表上的其他索引执行索引扫描操作。
格式3表示指定了目标表上的所有已存在的索引,即此时优化器不会考虑对该目标表上所有已存在的索引执行索引扫描操作,这相当于对目标表指定了全表扫描。
select /* no_index(emp pk_emp) */ empno,ename,sal,job from emp where empno=7369 and mgr=7902 and deptno=20; select /* no_index(emp pk_emp idx_emp_mgr idx_emp_dept) */ empno,ename,sal,job from emp where empno=7369 and mgr=7902 and deptno=20; select /* no_index */ empno,ename,sal,job from emp where empno=7369 and mgr=7902 and deptno=20;
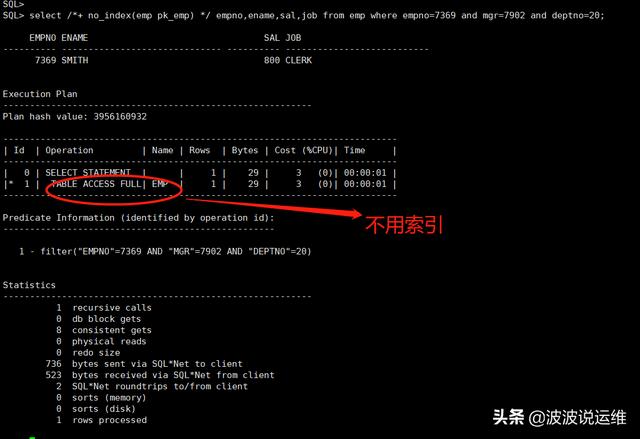

2、INDEX_DESC
INDEX_DESC是针对单个目标表的Hint,它的含义是让优化器对目标表上的目标索引执行索引降序扫描操作。如果目标索引是升序的,则INDEX_DESC Hint会使Oracle以降序的方式扫描该索引;如果目标索引是降序的,则INDEX_DESC Hint会使Oracle以升序的方式扫描该索引。
格式有三种:
格式1 /* INDEX_DESC(目标表 目标索引) */
格式2 /* INDEX_DESC(目标表 目标索引1 目标索引2 …… 目标索引n) */
格式3 /* INDEX_DESC(目标表) */
select /* index_desc(emp pk_emp) */ empno,ename,sal,job from emp where empno=7369 and mgr=7902 and deptno=20; select /* index_desc(emp pk_emp idx_emp_mgr idx_emp_dept) */ empno,ename,sal,job from emp where empno=7369 and mgr=7902 and deptno=20; select /* index_desc */ empno,ename,sal,job from emp where empno=7369 and mgr=7902 and deptno=20;

3、INDEX_JOIN
INDEX_JOIN是针对单个目标表的Hint,它的含义是让优化器对目标表上的多个目标索引执行INDEX JOIN操作。INDEX JOIN能成立的前提条件是SELECT语句中所有的查询列都存在于目标表上的多个目标索引中,即通过扫描这些索引就可以得到所有的查询列而不用回表。
格式如下:
格式1 /* INDEX_JOIN(目标表 目标索引1 目标索引2 …… 目标索引n) */ 格式2 /* INDEX_JOIN */
上述两种格式的含义与INDEX_COMBINE Hint中对应格式的含义相同。
select /* index_join(emp pk_emp idx_emp_mgr) */ empno,mgr from emp where empno>7369 and mgr<7902; select /* index_join(emp) */ empno,mgr from emp where empno>7369 and mgr<7902;
实例:
select empno,mgr from emp where empno>7369 and mgr<7902; select /* index_join(emp) */ empno,mgr from emp where empno>7369 and mgr<7902;


四、与表连接顺序相关的Hint(不演示)
1、ORDERED
ORDERED是针对多个目标表的Hint,它的含义是让优化器对多个目标表执行表连接操作时,执照它们在目标SQL的where条件中出现的顺序从左到右依次进行连接。
格式如下:
/* ORDERED */
select /* ordered */ e.ename,j.job,e.sal,d.deptno from emp e,jobs j,dept d where e.empno=j.empno and e.deptno=d.deptno and d.loc='CHICAGO' order by e.ename;
实例:
select e.ename,j.job,e.sal,d.deptno from emp e,jobs j,dept d where e.empno=j.empno and e.deptno=d.deptno and d.loc='CHICAGO' order by e.ename; select /* ordered */ e.ename,j.job,e.sal,d.deptno from emp e,jobs j,dept d where e.empno=j.empno and e.deptno=d.deptno and d.loc='CHICAGO' order by e.ename;
从上面的执行计划可以看出不使用ordered Hint时表扫描的顺序是DEPT->EMP->JOBS,但是使用ordered Hint后,表扫描的顺序变为了EMP->JOBS->DEPT与目标SQL中的顺序一致了,在修改了目标SQL文本之后表的扫描顺序也相应地变为了EMP->DEPT->JOBS。
2、LEADING
LEADING是针对多个目标表的Hint,它的含义是让优化器将我们指定的多个表的连接结果作为目标SQL表连接过程中的驱动结果集,并且将LEADING Hint中从左至右出现的第一个目标表作为整个表连接过程中的首个驱动表。
LEADING比ORDERED要温和一些,因为它只是指定了首个驱动表和驱动结果集,没有像ORDERED那样完全指定了表连接的顺序,也就是说LEADING给了优化器更大的调整余地。
当LEADING Hint中指定的表并不能作为目标SQL的连接过程中的驱动表或者驱动结果集时,Oracle会忽略该Hint。
格式如下:
/* LEADING(目标表1 目标表2 …… 目标表n) */
select /* leading(t e) */ e.ename,j.job,e.sal,d.deptno from emp e,jobs j,dept d,emp_temp t where e.empno=j.empno and e.deptno=d.deptno and d.loc='CHICAGO' and e.ename=t.ename order by e.ename;
实例:
select e.ename,j.job,e.sal,d.deptno from emp e,jobs j,dept d,emp_temp t where e.empno=j.empno and e.deptno=d.deptno and d.loc='CHICAGO' and e.ename=t.ename order by e.ename; select /* leading(t e) */ e.ename,j.job,e.sal,d.deptno from emp e,jobs j,dept d,emp_temp t where e.empno=j.empno and e.deptno=d.deptno and d.loc='CHICAGO' and e.ename=t.ename order by e.ename; select /* ordered */ e.ename,j.job,e.sal,d.deptno from emp e,jobs j,dept d,emp_temp t where e.empno=j.empno and e.deptno=d.deptno and d.loc='CHICAGO' and e.ename=t.ename order by e.ename;
从上面的执行计划可以看出不使用Hint时表扫描顺序是DEPT->EMP->JOBS->EMP_TEMP;使用LEADING Hint时表扫描顺序是EMP_TEMP->EMP->DEPT->JOBS,EMP_TEMP做首个驱动表和表EMP的连接结果做为驱动结果集,与Hint要求一致。;使用Ordered Hint时表扫描顺序是EMP->JOBS->DEPT->EMP_TEMP,与SQL中顺序一致。
篇幅有限,关于oracle常见的一些hint就介绍到这了,如果大家想深入学习数据库的话hint这一块内容还是必不可少的,特别是做优化的时候。
后面会分享更多关于DBA方面内容,感兴趣的朋友可以关注下!

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






