最好的pandas函数(Pandas的函数应用及映射方法)

CDA数据分析师 出品
在数据分析师日常的数据清洗工作中,经常需要对数据进行各种映射变换,通过Pandas可以非常方便地解决此问题,其提供了map()、apply()、mapapply()等方法,下面将一一详细介绍这三个映射函数的用法及三者的区别。
1. map( )map方法主要是运用在Series中,用来对Series中的元素进行转化。其语法及参数说明如下:
语法:se.map(arg, na_action=None)
参数说明:
· arg:函数、字典或序列对应的映射
· na_action: 是否忽略NA,默认None
当传入参数arg为序列时,会将传入的序列中与原序列value相匹配的key,所对应的value映射到原序列的value中。
# 根据指定序列进行一一映射<<< se1 =pd.Series({'a':1,'b':2,'c':3,'d':4})<<< se1a 1b 2c 3d 4dtype: int64<<< se2 =pd.Series({1:11,2:22,3:33,4:44})<<< se21 112 223 334 44dtype: int64<<< se1.map(se2)a 11b 22c 33d 44dtype: int64
将以上操作分解为两步来理解:
第一步:将序列se1中的value与序列se2中的key进行匹配。
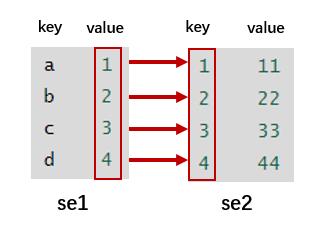
第二步:将序列se2中key对应的value映射到序列se1中的value

当传入的参数arg为字典时,返回一个根据字典的映射关系对原序列的value进行转换的新序列。
# 根据指定字典进行一一映射<<< se =pd.Series({'a':1,'b':2,'c':3,'d':4})<<< sea 1b 2c 3d 4dtype: int64<<< dic={1:11,2:22,3:33,4:44}<<< dic{1: 11, 2: 22, 3: 33, 4: 44}<<< se.map(dic)a 11b 22c 33d 44dtype: int64
当传入的参数arg为 函数时,会对原序列中每个元素运用该函数,并返回与原序列个数一致,index一致的新序列。运用的函数可以是numpy中的函数,也可以是匿名函数或自定义的函数。
· 直接使用numpy的函数
# 根据指定函数进行一一映射<<< se=pd.Series({'a':-1,'b':2,'c':-3,'d':4})<<< sea -1b 2c -3d 4dtype: int64# 直接使用numpy的函数,不常用 <<< se.map(np.abs)a 1b 2c 3d 4dtype: int64# 直接对Series运用numpy函数效果一致<<< se.abs()a 1b 2c 3d 4dtype: int64
· 使用匿名函数
# 使用匿名函数<<< se =pd.Series({'a':1,'b':2,'c':3,'d':4})<<< sea 1b 2c 3d 4dtype: int64<<< se.map(lambda x:x**2)a 1b 4c 9d 16dtype: int64
· 使用自定义函数
# 使用匿名函数<<< def fun(x): x=x**2 return x<<< se.map(fun)a 1b 4c 9d 16dtype: int64
2. apply( )apply()是pandas中使用频率特别高的一种方法,需要重点掌握。apply()方法不仅可以和map()方法一样,得到一个对元素进行转换后相同大小的结果数组,还可以得到一个通过函数进行汇总的标量值。其语法及参数说明如下:
语法:df.apply( ['func', 'axis=0', 'broadcast=None', 'raw=False', 'reduce=None', 'result_type=None', 'args=()', 'kwds'],)**
重要参数说明:
· func:对对象操作的函数,可以是numpy中的函数,也可以是匿名函数或自定义的函数
· axis:当输入对象为dataframe时运算依据的轴,0为将函数作用于每列,1为将函数作用于每行,默认None
当输入对象为Series时,apply()会将函数作用于对象中的每个值,效果与map()方法完全一致。
<<< se =pd.Series({'a':1,'b':2,'c':3,'d':4})<<< sea 1b 2c 3d 4# 对序列se的每个值进行开平方操作<<< se.apply(np.sqrt)a 1.000000b 1.414214c 1.732051d 2.000000dtype: float64
当输入对象为DataFrame时,apply()方法的作用对象为每一行或者每一列数据,若axis为0,即函数作用于每列数据;若axis为1,即函数作用于每行数据。
<<< df = pd.DataFrame(np.arange(16).reshape(4,4), columns=['A','B','C','D'])<<< df A B C D0 0 1 2 31 4 5 6 72 8 9 10 113 12 13 14 15# 对dataframe根据每列求和<<< df.apply(np.sum)A 24B 28C 32D 36dtype: int64 # 对dataframe根据每行求平均值<<< df.apply(np.mean,axis=1)0 1.51 5.52 9.53 13.5dtype: float64
和map()方法一样,apply()中运用的函数可以是上例所示numpy中的函数,也可以是匿名函数或自定义的函数。
# 使用匿名函数对dataframe进行操作<<< df.apply(lambda x:x**2) A B C D0 0 1 4 91 16 25 36 492 64 81 100 1213 144 169 196 225# 使用自定义函数对dataframe进行操作<<< def fun(x): x=x**2 return x<<< df.apply(fun) A B C D0 0 1 4 91 16 25 36 492 64 81 100 1213 144 169 196 225
3. applymap( )上面apply()方法主要是对dataframe数据的行或列进行操作,但如果我们想对datafram数据中的每个元素进行操作,而不进行汇总,该怎么实现呢?
pandas提供的另一个映射函数mapapply(),则能实现将函数运用在元素级别。其语法及参数说明如下:
语法:df.applymap(func)
参数说明:
· func :对元素进行操作的函数
applymap()方法只运用于dataframe数据中,对dataframe数据中的每一元素进行指定函数的操作,其作用类似于map()方法对Series的作用。
# 对dataframe数据中的每个元素保留2位小数<<< df.applymap(lambda x: '%.2f'%x) A B C D0 0.00 1.00 2.00 3.001 4.00 5.00 6.00 7.002 8.00 9.00 10.00 11.003 12.00 13.00 14.00 15.00
4. 总结map()、apply()、mapapply()三者的区别总结如下:
· map():只能作用于Series中的每个元素;
· apply():既可以作用于Series中的每个元素,也可以作用于DataFrame中的行或列;
· applymap():只能作用于DataFrame中的每个元素。

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






