spark读写流程(Spark源码中添加deleteFile方法)
在大数据框架Spark的源码中我们使用addFile方法将一些文件分发给各个节点,当我们要访问Spark作业中的文件,将使用Sparkfiles.get(fileName)找到它的下载位置,但是Spark只提供给我们addFile方法,却没有提供deleteFile。我们知道addFile是SparkContext类的方法,而SparkContext是Spark功能的主要入口。SparkContext代表了与Spark集群的连接,可用于在该集群上创建RDD、累积器和广播变量。每个JVM只能活动一个SparkContext。
在SparkContext添加deleteFile方法下面是SparkContext中addFile的源码,首先我们是不知道源码中是怎么操作这些文件的,我们将通过阅读addFile的源码来学习怎么去添加deleteFile方法,我们只有知道怎么添加才知道怎么去修改它,所谓触类旁通。

def addFile(path: String, recursive: Boolean): Unit = {
val uri = new Path(path).toUri
val schemeCorrectedPath = uri.getScheme match {
case null | "local" => new File(path).getCanonicalFile.toURI.toString
case _ => path
}
val hadoopPath = new Path(schemeCorrectedPath)
val scheme = new URI(schemeCorrectedPath).getScheme
if (!Array("http", "https", "ftp").contains(scheme)) {
val fs = hadoopPath.getFileSystem(hadoopConfiguration)
val isDir = fs.getFileStatus(hadoopPath).isDirectory
if (!isLocal && scheme == "file" && isDir) {
throw new SparkException(s"addFile does not support local directories when not running "
"local mode.")
}
if (!recursive && isDir) {
throw new SparkException(s"Added file $hadoopPath is a directory and recursive is not "
"turned on.")
}
} else {
Utils.validateURL(uri)
}
val key = if (!isLocal && scheme == "file") {
env.rpcEnv.fileServer.addFile(new File(uri.getPath))
} else {
schemeCorrectedPath
}
val timestamp = System.currentTimeMillis
if (addedFiles.putIfAbsent(key, timestamp).isEmpty) {
logInfo(s"Added file $path at $key with timestamp $timestamp")
Utils.fetchFile(uri.toString, new File(SparkFiles.getRootDirectory()), conf,
env.securityManager, hadoopConfiguration, timestamp, useCache = false)
postEnvironmentUpdate()
}
}
通过上面的源码我们知道,是使用addedFiles 这个ConcurrentHashMap[用于存储每个静态文件/jar的URL以及文件的本地时间戳的
private[spark] val addedFiles = new ConcurrentHashMap[String, Long]().asScala
上面的学习我们已经知道了添加的方法,然后就是添加deleteFilele了,具体的实现如下:

我们已经了解了在SparkContext添加deleteFile方法,我们了解下NettyStreamManager。NettyStreamManager是StreamManager实现,用于服务于NettyRpcEnv中的文件。在这个管理器中可以注册三种资源,都是由实际文件支持的。
- - "/files":一个扁平的文件列表;作为SparkContext.addFile的后端。
- - "/jars":一个扁平的文件列表;作为SparkContext.addJar的后端。
- - 任意目录;该目录下的所有文件通过管理器变得可用,尊重目录的层次结构。只支持流媒体(openStream)。
- 我们还是先看addFile的源码,先看父类RpcEnvFileServer的接口,RpcEnv用来向应用程序所拥有的其他进程提供文件的服务器。该file Server可以返回由普通库处理的URI(如 "http "或 "hdfs"),也可以返回由RpcEnv#fetchFile处理的 "spark "URI。
def addFile(file: File): String
2. NettyStreamManager中addFile方法实现
override def addFile(file: File): String = {
val existingPath = files.putIfAbsent(file.getName, file)
require(existingPath == null || existingPath == file,
s"File ${file.getName} was already registered with a different path "
s"(old path = $existingPath, new path = $file")
s"${rpcEnv.address.toSparkURL}/files/${Utils.encodeFileNameToURIRawPath(file.getName())}"
}
3. 跟addFile一样,先去父类RpcEnvFileServer中添加deleteFile方法

4. 接下来我们将在NettyStreamManager中实现deleteFile方法,如下

我们知道Spark中的SQL解析是通过ANTLR4来解析成语法树的,如果不清楚这个过程,可以阅读我的这篇博客【Spark SQL解析过程以及Antlr4入门】来了解,所以我们如果要在Spark Sql也支持的话,那么需要修改SqlBase.g4这个文件,添加DElETE
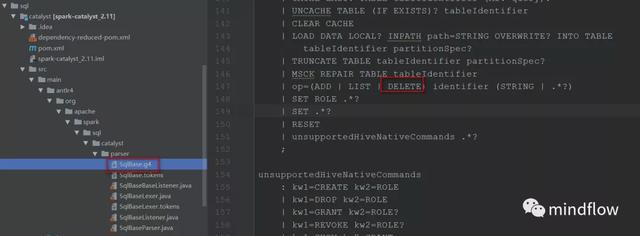
- 找到org.apache.spark.sql.execution.SparkSqlParser类,添加对移除文件的支持。SparkSqlParser是Spark SQL语句的具体解析器。
override def visitManageResource(ctx: ManageResourceContext): LogicalPlan = withOrigin(ctx) {
val mayebePaths = remainder(ctx.identifier).trim
ctx.op.getType match {
case SqlBaseParser.ADD =>
ctx.identifier.getText.toLowerCase match {
case "file" => AddFileCommand(mayebePaths)
case "jar" => AddJarCommand(mayebePaths)
case other => operationNotAllowed(s"ADD with resource type '$other'", ctx)
}
/*
*TODO 添加支持移除文件
* */
case SqlBaseParser.DELETE =>
ctx.identifier.getText.toLowerCase(Locale.ROOT) match {
case "file" => DeleteFileCommand(mayebePaths)
case other => operationNotAllowed(s"DELETE with resource type '$other'", ctx)
}
case SqlBaseParser.LIST =>
ctx.identifier.getText.toLowerCase match {
case "files" | "file" =>
if (mayebePaths.length > 0) {
ListFilesCommand(mayebePaths.split("\\s "))
} else {
ListFilesCommand()
}
case "jars" | "jar" =>
if (mayebePaths.length > 0) {
ListJarsCommand(mayebePaths.split("\\s "))
} else {
ListJarsCommand()
}
case other => operationNotAllowed(s"LIST with resource type '$other'", ctx)
}
case _ => operationNotAllowed(s"Other types of operation on resources", ctx)
}
}
- 再找到resources.scala文件

找到org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver 这个类,然后修改

我们将源码放到linux的服务器中去编译,然后部署
./dev/make-distribution.sh --name 2.6.0-cdh5.14.2 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.14.2

如果你对源码感兴趣,关注我获取已经修改好的源码
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com