opencv 开发过程(Opencv项目实战)
文章目录
opencv项目实战:01 文字检测OCR(1)(2)
Opencv项目实战:02 角度探测器
Opencv项目实战:03 扫描二维码&条形码
Opencv项目实战:04 全景图片拼接
Opencv项目实战:05 物体检测
Opencv项目实战:06 文档扫描仪
Opencv项目实战:07 人脸识别和考勤系统
Opencv项目实战:08 Yolov3更高精度的检测物体
Opencv项目实战:09 物体尺寸测量
01 文字检测OCR(1)
1,效果展示:

由图我们可知,对图片进行了数字和字母的识别。
2,准备阶段(1)下载Tesseract
点击此网址:https://sourceforge.net/projects/tesseract-ocr-alt/files/
我下载的是第四个版本,下载后是zip包的形式,压缩后可安装,选择路径可更改,否则会在默认的C:\\Program Files里面,没有什么大的影响。
(2)下载pytesseract
默认大家都已经下载好了opencv,方式相同,打开pycharm,进入此设置页面。
点击加号,收索软件包,选择蓝色条框进行下载,即可。
(3)pytesseract的函数讲解
# flake8: noqa: F401from .pytesseract import ALTONotSupportedfrom .pytesseract import get_languagesfrom .pytesseract import get_tesseract_versionfrom .pytesseract import image_to_alto_xmlfrom .pytesseract import image_to_boxesfrom .pytesseract import image_to_datafrom .pytesseract import image_to_osdfrom .pytesseract import image_to_pdf_or_hocrfrom .pytesseract import image_to_stringfrom .pytesseract import Outputfrom .pytesseract import run_and_get_outputfrom .pytesseract import TesseractErrorfrom .pytesseract import TesseractNotFoundErrorfrom .pytesseract import TSVNotSupported __version__ = '0.3.9'我们着重讲解该项目所需的三个函数:
#1,pytesseract.image_to_string(img)#2,pytesseract.image_to_boxes(img)#3,pytesseract.image_to_data(img,confg=cong)传入的参数都为img,只有用到第三个函数才会单独进行配置。
那么它们所包含的意思是什么呢?
由上至下
Returns the result of a Tesseract OCR run on the provided image to string
将在提供的图像上运行Tesseract OCR的结果返回到字符串
Returns string containing recognized characters and their box boundaries
返回包含可识别字符及其框边界的字符串
Returns string containing box boundaries, confidences,and other information.
返回包含框边界、置信度和其他信息的字符串。
3,代码的展示与讲解
import cv2import pytesseractimport numpy as npfrom PIL import ImageGrabimport time pytesseract.pytesseract.tesseract_cmd = 'E:\pythonProject\Github\Tesseract-OCR\\tesseract.exe'img = cv2.imread('1.png')img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) ##################################### Detecting Characters ####################################### print(pytesseract.image_to_string(img))hImg, wImg, _ = img.shapeboxes = pytesseract.image_to_boxes(img)for b in boxes.splitlines(): print(b) b = b.split(' ') print(b) x, y, w, h = int(b[1]), int(b[2]), int(b[3]), int(b[4]) cv2.rectangle(img, (x,hImg- y), (w,hImg- h), (50, 50, 255), 2) cv2.putText(img,b[0],(x,hImg- y 25),cv2.FONT_HERSHEY_SIMPLEX,1,(50,50,255),2) cv2.imshow('img', img)cv2.waitKey(0)我先给大家讲解一下代码的思路,对于新入门的同学是极其重要的(本人同样也是)。
首先,通过 pytesseract.pytesseract.tesseract_cmd 录入我们刚刚下载Tesseract的路径,最好不要包含中文路径。
第二步,读入我们的图像,并将其转换为RGB格式,我们知道在opencv当中颜色是BGR格式,但我们的Tesseract读取的是RGB格式,故此多了一步转换。
第三步,打印 pytesseract.image_to_string(img),识别内容会出现在运行台中,可以用来检测是否将数字和字母识别正确或者识别完。注释掉无影响。
第四步,将图片的长,宽,通道数录入。用boxes 接收 pytesseract.image_to_boxes(img) 它的参数。如下:
1 68 524 76 544 02 132 523 145 543 03 197 524 209 544 04 260 523 275 543 05 329 522 341 543 0
所获取的信息为(从左到右):识别内容;x;y;宽;高 ;0(不用此参数)
第五步,根据获得的信息,对boxes做行的录入,形成列表,同时是按空格将信息分开。如下:
['1', '68', '524', '76', '544', '0']['2', '132', '523', '145', '543', '0']['3', '197', '524', '209', '544', '0']['4', '260', '523', '275', '543', '0']
第六步,将x,y,宽,高录进参数当中,用cv2.rectangle()函数,画出相应的矩形框,这时候大家或许会有疑问,就是为什么不是下面这样的呢?
cv2.rectangle(img, (x,y), (x w,y h), (50, 50, 255), 2)而是如下所示:
cv2.rectangle(img, (x,hImg- y), (w,hImg- h), (50, 50, 255), 2)我们先看看上面代码带来的效果:
矩形框对准的部位非常糟糕,那么不要怕,我们分析下。
由图,我们可知,在x的方向上的信息是正确的,问题出在了y的坐标上,用pytesseract.image_to_boxes(img) 获得的信息可能是按下图的坐标轴:
而我们知道在opencv当中的坐标轴是按照如下所示:
所以大家能理解这个地方了吗?
最后一步就是,对图像添加文本,放在合适的位置,并进行窗口展示。
一些其他的内容我将在《Opencv项目实战:01 文字检测OCR(2)》中介绍,包括了,文字,字母的单独检测,pytesseract.image_to_data(img,confg=cong) 的配置问题,Tesseract的效果评估,以及此项目的总结。
图片素材,需用自取。
01 文字检测OCR(2)
1,相关函数的讲解image_to_data()的输出结果是表格形式,输出变量的类型依旧是字符串。
你会得到一个这样的列表['level', 'page_num', 'block_num', 'par_num', 'line_num', 'word_num', 'left', 'top', 'width', 'height', 'conf', 'text'],我们逐个解释下:
level,当前项的层级;
page_num,当前项所属页,一般情况下,单张图片的内容均会被分在同一个页;
block_num ,当前项所属块,Tesseract会将图像分割为多个不同的block,block会出现1,2,3……等等值;
par_num,当前图像中文字的段落分类;
line_num,当前项所属行;
word_num,为同一行中当前项所属的单词序号;
left\ top\ width\ height,分别为当前项所在矩形区域的左上角坐标、宽度和高度;
conf,当前检测字符的置信度,表示项无文字,值为-1,若Tesseract认为当前区域有文字,则其值得范围为0~100;
text,即为当前项的文本,若无文字此项为空。
那么关于enumerate()函数,大家可以看看此文。
2,代码展示(1)Detecting Words
import cv2import pytesseractimport numpy as npfrom PIL import ImageGrabimport time pytesseract.pytesseract.tesseract_cmd = 'E:\pythonProject\Github\Tesseract-OCR\\tesseract.exe'img = cv2.imread('1.png')img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) ################################################### Detecting Words #################################################### #[ 0 1 2 3 4 5 6 7 8 9 10 11 ] #['level', 'page_num', 'block_num', 'par_num', 'line_num', 'word_num', 'left', 'top', 'width', 'height', 'conf', 'text'] boxes = pytesseract.image_to_data(img) for a,b in enumerate(boxes.splitlines()): print(b) if a!=0: b = b.split() if len(b)==12: x,y,w,h = int(b[6]),int(b[7]),int(b[8]),int(b[9]) cv2.putText(img,b[11],(x,y-5),cv2.FONT_HERSHEY_SIMPLEX,1,(50,50,255),2) cv2.rectangle(img, (x,y), (x w, y h), (50, 50, 255), 2) cv2.imshow('img', img)cv2.waitKey(0)(2)Detecting ONLY Digits
3,问题叙述
import cv2import pytesseractimport numpy as npfrom PIL import ImageGrabimport time pytesseract.pytesseract.tesseract_cmd = 'E:\pythonProject\Github\Tesseract-OCR\\tesseract.exe'img = cv2.imread('1.png')img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) ################################################### Detecting ONLY Digits #################################################### hImg, wImg,_ = img.shape conf = r'--oem 3 --psm 6 outputbase digits' boxes = pytesseract.image_to_boxes(img,config=conf) for b in boxes.splitlines(): print(b) b = b.split(' ') print(b) x, y, w, h = int(b[1]), int(b[2]), int(b[3]), int(b[4]) cv2.rectangle(img, (x,hImg- y), (w,hImg- h), (50, 50, 255), 2) cv2.putText(img,b[0],(x,hImg- y 25),cv2.FONT_HERSHEY_SIMPLEX,1,(50,50,255),2) cv2.imshow('img', img)cv2.waitKey(0)首先,我遇到的问题有
(1)无效的TeserAct版本:“TeserAct3.02”
可能是此版本太低了,但我找了找新的版本,在此更新一下路径:
点击此网址 https://github.com/UB-Mannheim/tesseract/wiki
自行选择合适的就可以了。
(2)识别效果差
可以看到,将本来不是数字的字母也强行识别出来了,这简直说不过去了。
最后我们看看更改后的效果:
cool,非常的棒,快去试试吧!
对于数字又强差人意了,所以说它这个本身还是存在一点的问题。我觉得影响不大,你觉得不舒服,可以换张图试试。
4,image_to_data()配置讲解oem讲解
OEM _ TESSERACТ_ ONLY 只以最快的速度运行Tesseract
OEM _ CUBE _ ONLY 仅运行多维数据集-精度更高,但速度更慢
OEM _ TESSERACT _ CUBE _ cOMBINED 同时运行并组合结果-最佳精度
OEM _ DEFAULT 在调用init_*0时指定此模式,以指示应根据特定于语言的配置中的变量自动推断上述任何模式。命令行配置,或者如果没有在上面任何一项中指定,则应设置为默认的OEM_ TESSERACT_ ONLY。
psm讲解
PSM _ OSD _ ONLY 仅用于方向和脚本检测。
PSM _ AUTO _ OSD 带有方向和脚本检测的自动页面分割。(OSD)PSM _ AUTO _ ONLY 自动页面分割,但没有OSD或OCR。 PSM _ AUTO 完全自动页面分割,但没有OSD。PSM _ SINGLE _ COLUMN 假设一列大小可变的文本。PSM _ SINGLE _ BLOCK _ VERT _ TEXT 假设一个统一的垂直对齐文本块。PSM _ SINGLE _ BLOCK 假设一个统一的文本块(默认值)PSM _ SINGLE _ LINE 将图像视为单个文本行。PSM _ SINGLE _ WORD 将图像视为单个单词。PSM _ CIRCLE _ WORD 将图像视为圆圈中的单个单词。PSM _ SINGLE _ CHAR 将图像视为单个字符。PSM _ SPARSE _ TEXT 在没有特定顺序的情况下尽可能多地查找文本。PSM _ SPARSE _ TEXT _ OSD 具有方向和脚本检测的稀疏文本。
PSM _ RAW _ LINE 将图像视为单个文本行,绕过特定于Tesseract的黑客攻击。
5,项目拓展
import cv2import pytesseractimport numpy as npfrom PIL import ImageGrabimport time pytesseract.pytesseract.tesseract_cmd = 'E:\pythonProject\Github\Tesseract-OCR\\tesseract.exe'img = cv2.imread('1.png')img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)cap = cv2.VideoCapture(0)cap.set(3,640)cap.set(4,480)def captureScreen(bbox=(300,300,1500,1000)): capScr = np.array(ImageGrab.grab(bbox)) capScr = cv2.cvtColor(capScr, cv2.COLOR_RGB2BGR) return capScrwhile True: timer = cv2.getTickCount() _,img = cap.read() #img = captureScreen() #DETECTING CHARACTERES hImg, wImg,_ = img.shape boxes = pytesseract.image_to_boxes(img) for b in boxes.splitlines(): #print(b) b = b.split(' ') #print(b) x, y, w, h = int(b[1]), int(b[2]), int(b[3]), int(b[4]) cv2.rectangle(img, (x,hImg- y), (w,hImg- h), (50, 50, 255), 2) cv2.putText(img,b[0],(x,hImg- y 25),cv2.FONT_HERSHEY_SIMPLEX,1,(50,50,255),2) fps = cv2.getTickFrequency() / (cv2.getTickCount() - timer); #cv2.putText(img, str(int(fps)), (75, 40), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (20,230,20), 2); cv2.imshow("Result",img) cv2.waitKey(1) cv2.imshow('img', img)cv2.waitKey(0)进行网络摄像头的实时文字测试。
6,总结与评价我是首次使用Tesseract,体验感很不好,这是我在b站的评论中看到的:
说实话,我还没有学到用算法的地步,学学了解一下就好了,反正我是准备项目实战的中后期去学习深度学习,以及其他的算法学习,这方面我不好说,但它的精度的确是不达标,你们也看到了,居然把文字也识别成了数字。而且开启摄像头识别的也不是很好,识别不完全or识别错误。
02 角度探测器
1,效果展示
本次项目很简单,即是根据鼠标的点击,检测角度值,如上图,存在一些人为误差,效果也是相当不错的,接下来我们正式开始。
2,项目知识讲解(1)鼠标点击事件
cv2.setMouseCallback(windowName, onMouse) cv2.EVENT_LBUTTONDOWN第一个函数是指在鼠标点击后得到的响应,'windowName'参数是指鼠标点击的窗口名,'onMouse',可以作为在得到响应后,需要进一步操作的函数。
第二个函数是指敲击了鼠标左键。想了解更多可以看下面这篇博客。
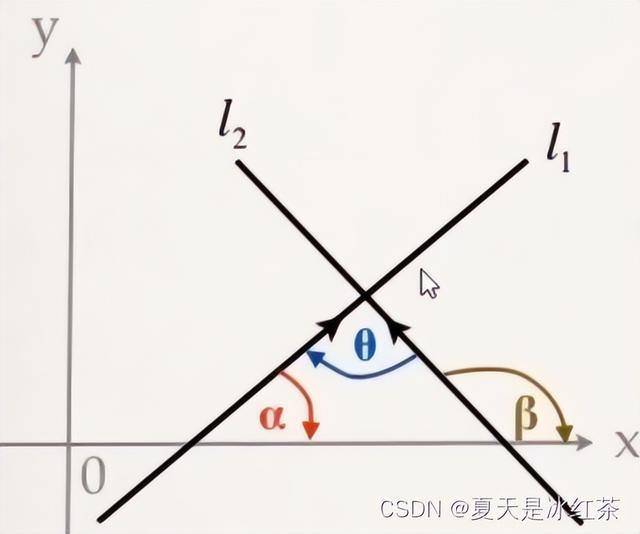
(2)两线间角度
- 有三个点的坐标,分别求出三条直线的斜率,k1,k2,k3
- 两条斜率分别为k1,k2的直线,他们的夹角公式为:
- L1与L2的夹角为θ,则tanθ=∣(k2- k1)/(1 k1*k2)∣
3,代码的展示与讲解
import cv2import math path = 'test.png'img = cv2.imread(path)pointsList = [] def mousePoints(event, x, y, flags, params): if event == cv2.EVENT_LBUTTONDOWN: size = len(pointsList) if size != 0 and size % 3 != 0: cv2.line(img, tuple(pointsList[round((size - 1) / 3) * 3]), (x, y), (0, 0, 255), 2) cv2.circle(img, (x, y), 5, (0, 0, 255), cv2.FILLED) pointsList.append([x, y]) def gradient(pt1, pt2): return (pt2[1] - pt1[1]) / (pt2[0] - pt1[0]) def getAngle(pointsList): pt1, pt2, pt3 = pointsList[-3:] m1 = gradient(pt1, pt2) m2 = gradient(pt1, pt3) angR = math.atan((m2 - m1) / (1 (m2 * m1))) #弧度制 angD = round(math.degrees(angR)) #度数 cv2.putText(img, str(angD), (pt1[0] - 40, pt1[1] - 20), cv2.FONT_HERSHEY_COMPLEX, 1.5, (0, 0, 255), 2) while True: if len(pointsList) % 3 == 0 and len(pointsList) != 0: getAngle(pointsList) img=cv2.resize(img,(1044,614)) cv2.imshow('Image', img) cv2.setMouseCallback('Image', mousePoints) if cv2.waitKey(1) & 0xFF == ord('q'): pointsList = [] img = cv2.imread(path) elif cv2.waitKey(1) & 0xFF == ord('w'): break由我来讲解一下此代码,可以先看我的分析,再去看着代码,敲一遍就好了。
首先,读入我们的图像,并建立一个空列表用来接收每次鼠标点击之后返回的坐标值。其次,(1)在mousePoints函数里面,用pointsList收集鼠标点击的坐标,并在点击处画点,而在连线处有个问题,那就是cv2.line是输入两点的坐标后画线,第二个点就保持鼠标点击得到的坐标,对于第一个点,那就是保持第一次点击的坐标,即pst1的坐标;(2)在gradient函数里面,作用就很简单了,即是求pst1与pst2,pst1与pst3之间的斜率;(3)在getAngle函数里面,则是根据公式求出角度值,并将其打印在合适的位置;最后,while True循环当中,就是对函数的调用,并且用点击键盘的'q',刷新图片和清空存储在pointsList的坐标,点击键盘的'w',退出循环。
4,项目总结本次项目较为简单,没有太过困难的地方,在结尾处我会附加上图片素材,需用自取,但我不知道在上传后,图片大小是否会改变,原图片的大小为1392*818,在本次项目中我采用了其大小的75%,拿到图片后,先看图片的属性,再在此位置进行修改
img=cv2.resize(img,(1044,614))从使用体验上,我觉得新鲜感不够,但用于新入门的来说,就还不错吧。
希望你在本项目中,玩的开心!!
5,项目素材
03 扫描二维码&条形码
1,效果展示声明:二维码会让图片违规,我处理了一下,大家看看效果
我们扫描出来的结果会有数字,网址链接,英文等。
2,项目准备(1)安装pyzbar使用pip下载,打开控制面板,输入:
(2)在此项目下建立两个.py文件,以及一个.text文件
pip install pyzbar
打开DataFile.text,输入以下内容:
111111 111112 111113 111114 111115
或则输入其他内容,包括英文和数字,注意不要用中文。
(3)准备需要的二维码和条形码二维码生成网站:
在线二维码生成器 ~ 二维工坊 (2weima.com)
https://www.2weima.com/
按照你写的DataFile.text里面的内容来生成二维码,可以准备几个其他内容的二维码,因为我们是在项目拓展中才会使用,亦或者使用生活中的二维码,比如,书籍,牛奶盒,微信收款码等等。
条形码生成网站:
免费在线条形码生成器 (t-x-m.com)
http://t-x-m.com/
条形码无所谓多少。建议大家将准备好的二维码和条形码打印到一张纸上,方便扫描,我昨天打印的不见了,所以效果展示我就用手机拍下来扫描的。
3,代码展示与讲解
import cv2import numpy as npfrom pyzbar.pyzbar import decode cap = cv2.VideoCapture(0)cap.set(3, 640)cap.set(4, 480) while True: success, img = cap.read() for barcode in decode(img): myData = barcode.data.decode('utf-8') print(myData) pts = np.array([barcode.polygon], np.int32) pts = pts.reshape((-1, 1, 2)) cv2.polylines(img, [pts], True, (255, 0, 255), 5) pts2 = barcode.rect cv2.putText(img, myData, (pts2[0], pts2[1]), cv2.FONT_HERSHEY_SIMPLEX,0.9, (255, 0, 255), 2) cv2.imshow('Result', img) k=cv2.waitKey(1) & 0xFF if k==27: break本次项目没什么难点,我们直接讲解一下,此项目实现的思路。先看我的分析,再去跟着敲一遍代码。
- 首先,在本项目中不管是读取图像,还是读取摄像头都能实现,那么我们在这里是实现摄像头的实时扫描。读取网络摄像头(在效果展示中,我采用的外用摄像头),在cap.set()函数里面,用‘3’代表的是宽,用‘4’代表的是高的设置,使其窗口大小合适。
- 其次是在while True中,success接受的是布尔值,检测是否读取成功,用img读取每一帧的图像。采取pyzbar包中的decode函数,对img进行解码,并将解码后的内容打印在控制台中,大家也可以尝试将解码的内容打印出来,看看有些什么东西。(包括barcode.rect和barcode.data)
- 除此之外,在Opencv中绘制包围住二维码的方法有很多,比如绘制矩形、绘制多边形;如果是选择矩形框框,识别时二维码存在的倾斜角度会导致添加的框框不能跟着倾斜,而这不是我们想要的效果,因此我们需要选用绘制多边形。具体如下:
第一行使用numpy库中array函数,得到一个四点数据矩阵。其中barcode.polygon作用是从轮廓中提取polygon点,作为顶点(请看下方图一);np.int32则是对于数据的类型约束。第二行的reshape((-1,1,2))函数,-1表示行有先,主要功能是将原有的数据形状转换为opencv中常用的形状:(x,1,y),便于使用(请看下方图二)。如将(4,2)转换为(4,1,2)。第三行就是绘画多边形的过程,使用cv.ploylines函数,绘制了一个闭合、紫色、宽度为五的四边形。注意此次的布尔值指的是是否为闭合图型。
图一:
图二:
- 紧接着,是放置文本框,那么我们当然不需要它移动,我们希望的是它可以固定在某一点。那么在此处我们采取了rect的方法,得到如下图所表示:
- 最后,就是展示窗口,在此处如果想关闭窗口,点击Esc键即可,27即是Esc键的Ascll码。
4,项目拓展
项目拓展描述:
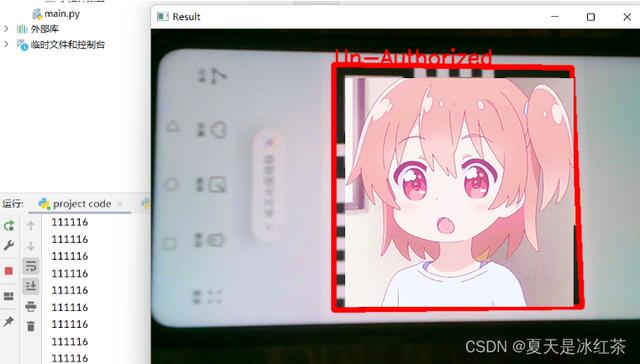
公司的员工使用工作牌扫描二维码开门的想法的实现,根据我们之前准备好的DataFile.text,以及生成的二维码,如果扫描的是DataFile.text里的内容就用绿色框和文本表示已经授权;否则,用红色框和文本表示未授权。
我们来看看它的效果是怎么样的。如下
项目实现的效果非常好,下面的代码我也不再多做讲解了,快去做起来吧!
5,项目总结与评价
import cv2import numpy as npfrom pyzbar.pyzbar import decode cap = cv2.VideoCapture(1)cap.set(3, 640)cap.set(4, 480) with open('DataFile.text') as f: myDataList = f.read().splitlines() while True: success, img = cap.read() for barcode in decode(img): myData = barcode.data.decode('utf-8') print(myData) if myData in myDataList: myOutput = 'Authorized' myColor = (0, 255, 0) else: myOutput = 'Un-Authorized' myColor = (0, 0, 255) pts = np.array([barcode.polygon], np.int32) pts = pts.reshape((-1, 1, 2)) cv2.polylines(img, [pts], True, myColor, 5) pts2 = barcode.rect cv2.putText(img, myOutput, (pts2[0], pts2[1]), cv2.FONT_HERSHEY_SIMPLEX, 0.9, myColor, 2) cv2.imshow('Result', img) k = cv2.waitKey(1) & 0xFF if k == 27: break本次项目中,由于我也不是很很了解reshape函数,还是查了资料才了解,对于二维码的扫描都是相当不错的,但对于条形码的扫描,在生活中的条形码没能成功,可能与摄像头有关吧。
希望你在本项目中玩的开心!!!
6,项目素材
可惜,二维码图片可能会违规,大家就自己在网站制作吧,需用自取
barcode:
04 全景图片拼接
1,效果展示首先,需要拍摄像这种的图片(当然,大家用我这的就可以了,我实在是太了解大家了)。
接下来,我们来看看拼接的效果图:
效果非常的棒,那我们再来看看,不同大小的图片的拼接效果
除了缺失的角,其他的都还好说,本来也在我的意料之中,如果还能实现自动补齐,那我肯定会大呼一声:“厉害!!”
2,项目准备(1)文件夹在pycharm项目中,请向我一样按照如图下所示创建。
我们只需要一个放置不同图片的文件夹和一个.py文件,注意照片一定不能放乱了,在结尾处我会附上素材。
(2)熟悉一下os
当然,此项目我们只需要一个函数,学久必有忘。
os.listdir(path) #返回path指定的文件夹包含的文件或文件夹的名字的列表。
3,代码展示与讲解
import cv2import os mainFolder = 'Images'myFolders = os.listdir(mainFolder) #读取主文件print(myFolders) for folder in myFolders: path = mainFolder '/' folder images =[] myList = os.listdir(path) print(f'Total number of images detected {len(myList)}') for imgN in myList: curImg = cv2.imread(f'{path}/{imgN}') curImg = cv2.resize(curImg,(0,0),None,0.2,0.2) images.append(curImg) stitcher = cv2.Stitcher.create() (status,result) = stitcher.stitch(images) if (status == cv2.STITCHER_OK): print('Panorama Generated') cv2.imshow(folder,result) cv2.waitKey(1) else: print('Panorama Generation Unsuccessful') cv2.waitKey(0)老规矩,还是看我分析讲解代码,再去看代码敲一遍。
首先,我们将图片是放在了Image文件,那么它就是我们的主文件夹,使用os.listdir(path)函数,他会返回一个包含了此路径下的列表如下所示: 其次,我们已经知道在Images文件夹下有两个文件,此时需要对其进行遍历,读取我们的图片,还是用os.listdir(path)函数,但此时我们的路径需要更改了,path=Images/1, Images/2,成功读取后,将图片放入列表当中,并通过打印查看是否将所有的图片读取完。除此之外,我们需要用到的是Opencv当中的Stitcher类,在这个类下有一个create函数,它的作用是简短创建在其中一种缝合模式下配置的缝合器,参数不用调配,它会提供一个默认值,它的使用方式:cv2.Stitcher.create(),接下来,我们还需要用Stitcher类下的stitch函数,它的作用是,返回状态代码和拼接结果。最后如果返回的状态码正确,即status == cv2.STITCHER_OK,当然我们将代码改成 if (status == 0):
也没有任何问题,因为STITCHER_OK = 0。
4,项目总结与评价如果你想创建一个应用程序,实现拼接功能,再了解特征检测的内部运行,将其结合在一起,这将是一个很棒思考的方向,因为我们的图片都是同一时间的场景,对比度,饱和度等是看不出变化的。
最初的效果展示中,我们可以看到在边角处还是存在着一些黑色瑕疵,那么两张尺寸不同的图,也可以进行拼接,只是有所缺角。
5,项目素材Images/1/1.jpg
Images/1/2.jpg
Images/1/3.jpg
Images/2/1.jpg
Images/2/2.jpg
希望大家可以开心的完成本项目,如果你觉得有用,请收藏和点赞。
05 物体检测
1,效果展示为此,我专门还去查了查,怎么将视频转化为gif图,不知不觉中,我又多学会了一项技能。
OK!cool,效果很不错,今天需要搭配一些文件,都是可以从官网里找到的,那么我为了方便,专门去学习怎么在GitHub上托管项目,还下载了VScode和Git,我太难受了,如果不是要写博客,我绝对懒得去找教程。谢谢自己!
那么在此gif图像中,我检测了水瓶(截图时间不够了),鼠标,剪刀,书,手机,牙刷,键盘,电脑等。
2,项目准备
- 文件搭建
我会在结尾处,提供相关的资源,我们先在项目下新建一个目录,其中包含的文件,如图所示:
3,代码的讲解与展示
import cv2 thres = 0.45 # Threshold to detect object cap = cv2.VideoCapture(1)cap.set(3,640)cap.set(4,480)cap.set(10,70) classNames= []classFile = 'coco.names'with open(classFile,'rt') as f: classNames = f.read().rstrip('\n').split('\n') #restrip返回删除尾随空白的字符串副本。如果给定了字符而不是无,则删除字符中的字符。 configPath = 'ssd_mobilenet_v3_large_coco_2020_01_14.pbtxt'weightsPath = 'frozen_inference_graph.pb' net = cv2.dnn_DetectionModel(weightsPath,configPath)net.setInputSize(320,320)net.setInputScale(1.0/ 127.5)net.setInputMean((127.5, 127.5, 127.5))net.setInputSwapRB(True) while True: success,img = cap.read() classIds, confs, bbox = net.detect(img,confThreshold=thres) print(classIds,bbox) if len(classIds) != 0: for classId, confidence,box in zip(classIds.flatten(),confs.flatten(),bbox): cv2.rectangle(img,box,color=(0,255,0),thickness=2) cv2.putText(img,classNames[classId-1].upper(),(box[0] 10,box[1] 30), cv2.FONT_HERSHEY_COMPLEX,1,(0,255,0),2) cv2.putText(img,str(round(confidence*100,2)),(box[0] 200,box[1] 30), cv2.FONT_HERSHEY_COMPLEX,1,(0,255,0),2) cv2.imshow("Output", img) if cv2.waitKey(1) & 0xFF == 27: break #对于物体的检测今天的重点在于讲解代码的思路。
首先,打开我们的外部摄像头,并且设置窗口的宽,长,亮度,注意不要将窗口的大小超出我们外部摄像头的大小,不然你得到的图像可能就是黑屏。其次,在我们的coco.names文件当中,它是每个名词单独一行,所以通过文件操作,将其内容放入一个空列表当中,我们用到了read(),rstrip(),split()函数,不清楚的地方,可以去W3school上查询。接着,我们看看在包含了net的代码,它用到了DNN算法,其余的函数都可以在dnn.py文件里面查找到。(1)setInputSize(weight,height)weight新输入宽度,height新输入宽度。(2)setInputScale(1.0/ 127.5)设置帧的缩放因子值,帧值的比例乘数。(3)setInputMean((127.5, 127.5, 127.5))简要设置帧的平均值。(4)setInputSwapRB(True)将帧的标志设置为True。 然后,又要用到一个detect()函数,它是属于class DetectionModel(Model)下的函数,在这里confThreshold用于根据置信度筛选框的阈值,我们将其阈值放在了较前面的位置,方便更改,它会返回ClassID结果检测中的类索引,一组对应的置信度,一组边界框。除此之外,我们用len(classIds) != 0来代表检测到了物体,然而我们有三个需要遍历的变量或信息,所以我们用到了zip函数,避免了写三个循环,而flatten()函数可以将其中的信息展开,再然后画框,放置文本,在这里需要提两句,在coco.name文件里面,每个名词是从1开始的,而classNames列表是从0开始的,故要在索引处-1,使用round()函数是因为confidence是小数,会与之前的classNmaes的东西叠加在一起,故此将其看作是百分数,并保留了两位小数。最后就是,imshow的展示窗口,以及点击Esc键推出。
4,项目优化我已经将注释写在了代码当中,如有不清楚的地方,可以将其打印出来,进行观察。
其优化效果——有效的优化了之前检测框闪烁和重叠的现象。
5,项目资源
import cv2import numpy as np thres = 0.45 # Threshold to detect object#使用nms,不会像先前那样检测框有重叠和闪烁nms_threshold = 0.2 #0.2 已经是较大的抑制效果#若设置成1,将没有效果cap = cv2.VideoCapture(1)cap.set(3,1280)cap.set(4,720)cap.set(10,150) classNames= []classFile = 'coco.names'with open(classFile,'rt') as f: classNames = f.read().rstrip('\n').split('\n') #print(classNames)configPath = 'ssd_mobilenet_v3_large_coco_2020_01_14.pbtxt'weightsPath = 'frozen_inference_graph.pb' net = cv2.dnn_DetectionModel(weightsPath,configPath)net.setInputSize(320,320)net.setInputScale(1.0/ 127.5)net.setInputMean((127.5, 127.5, 127.5))net.setInputSwapRB(True) while True: success,img = cap.read() classIds, confs, bbox = net.detect(img,confThreshold=thres) bbox = list(bbox) #bbox本身得到的是numpy的数组,将其改为list confs = list(np.array(confs).reshape(1,-1)[0]) #将其内容转化为只有一个列表,使用np.array()是因为元组是不能reshape confs = list(map(float,confs)) #原本的confs是float32的形式,使用map()函数将float映射在confs上 #print(type(confs[0])) #print(confs) indices = cv2.dnn.NMSBoxes(bbox,confs,thres,nms_threshold) #print(indices) for i in indices: i = i[0] #打印(indices)的内容是[[0]] box = bbox[i] x,y,w,h = box[0],box[1],box[2],box[3] cv2.rectangle(img, (x,y),(x w,h y), color=(0, 255, 0), thickness=2) cv2.putText(img,classNames[classIds[i][0]-1].upper(),(box[0] 10,box[1] 30), cv2.FONT_HERSHEY_COMPLEX,1,(0,255,0),2) #此处需要一个classIds的特殊索引,它就是i,而且已经有了一个[],所以是[i][0] cv2.imshow("Output",img) cv2.waitKey(1)GitHub:
Auorui/Opencv-project-training: According to the project made by learning murtaza Hassan's videos every day, thank the up Master of station B: a graduate student who knows a little about everything. It is mainly used to learn opencv by myself. On my CSDN blog, I have a detailed picture and text introduction of each project. I will continue to study hard. Welcome to my CSDN blog, where I store my code and some information. CSDN link: https://blog.csdn.net/m0_62919535?type=blog 。 You can check it in my column - opencv project practice. (github.com)
https://github.com/Auorui/Opencv-project-training
免费转化为Gif图网站:
踢踢零工具 - tt0.top
https://tt0.top/
6,项目总结与评价其中的很多算法我也不是很明白,只是使用的思路学会到了,后面将会有人脸检测的项目,应该会用到YOYO算法。希望有人能在这个项目中玩的开心,感谢您的关注与支持!!!
06 文档扫描仪
1,效果展示网络摄像头扫描:
图片扫描:
最终扫描保存的图片:
(视频)
(图片)
2,项目准备今天的项目文件只需要两个.py文件,其中一个.py文件是已经写好的函数,你将直接使用它,我不会在此多做讲解,因为我们将会在主要的.py文件import 导入它,如果想了解其中函数是如何写的,请自行学习。
utlis.py,需要添加的.py文件
3,代码的讲解与展示
import cv2import numpy as np # TO STACK ALL THE IMAGES IN ONE WINDOWdef stackImages(imgArray,scale,lables=[]): rows = len(imgArray) cols = len(imgArray[0]) rowsAvailable = isinstance(imgArray[0], list) width = imgArray[0][0].shape[1] height = imgArray[0][0].shape[0] if rowsAvailable: for x in range ( 0, rows): for y in range(0, cols): imgArray[x][y] = cv2.resize(imgArray[x][y], (0, 0), None, scale, scale) if len(imgArray[x][y].shape) == 2: imgArray[x][y]= cv2.cvtColor( imgArray[x][y], cv2.COLOR_GRAY2BGR) imageBlank = np.zeros((height, width, 3), np.uint8) hor = [imageBlank]*rows hor_con = [imageBlank]*rows for x in range(0, rows): hor[x] = np.hstack(imgArray[x]) hor_con[x] = np.concatenate(imgArray[x]) ver = np.vstack(hor) ver_con = np.concatenate(hor) else: for x in range(0, rows): imgArray[x] = cv2.resize(imgArray[x], (0, 0), None, scale, scale) if len(imgArray[x].shape) == 2: imgArray[x] = cv2.cvtColor(imgArray[x], cv2.COLOR_GRAY2BGR) hor= np.hstack(imgArray) hor_con= np.concatenate(imgArray) ver = hor if len(lables) != 0: eachImgWidth= int(ver.shape[1] / cols) eachImgHeight = int(ver.shape[0] / rows) print(eachImgHeight) for d in range(0, rows): for c in range (0,cols): cv2.rectangle(ver,(c*eachImgWidth,eachImgHeight*d),(c*eachImgWidth len(lables[d][c])*13 27,30 eachImgHeight*d),(255,255,255),cv2.FILLED) cv2.putText(ver,lables[d][c],(eachImgWidth*c 10,eachImgHeight*d 20),cv2.FONT_HERSHEY_COMPLEX,0.7,(255,0,255),2) return ver def reorder(myPoints): myPoints = myPoints.reshape((4, 2)) myPointsNew = np.zeros((4, 1, 2), dtype=np.int32) add = myPoints.sum(1) myPointsNew[0] = myPoints[np.argmin(add)] myPointsNew[3] =myPoints[np.argmax(add)] diff = np.diff(myPoints, axis=1) myPointsNew[1] =myPoints[np.argmin(diff)] myPointsNew[2] = myPoints[np.argmax(diff)] return myPointsNew def biggestContour(contours): biggest = np.array([]) max_area = 0 for i in contours: area = cv2.contourArea(i) if area > 5000: peri = cv2.arcLength(i, True) approx = cv2.approxPolyDP(i, 0.02 * peri, True) if area > max_area and len(approx) == 4: biggest = approx max_area = area return biggest,max_areadef drawRectangle(img,biggest,thickness): cv2.line(img, (biggest[0][0][0], biggest[0][0][1]), (biggest[1][0][0], biggest[1][0][1]), (0, 255, 0), thickness) cv2.line(img, (biggest[0][0][0], biggest[0][0][1]), (biggest[2][0][0], biggest[2][0][1]), (0, 255, 0), thickness) cv2.line(img, (biggest[3][0][0], biggest[3][0][1]), (biggest[2][0][0], biggest[2][0][1]), (0, 255, 0), thickness) cv2.line(img, (biggest[3][0][0], biggest[3][0][1]), (biggest[1][0][0], biggest[1][0][1]), (0, 255, 0), thickness) return img def nothing(x): pass def initializeTrackbars(intialTracbarVals=0): cv2.namedWindow("Trackbars") cv2.resizeWindow("Trackbars", 360, 240) cv2.createTrackbar("Threshold1", "Trackbars", 200,255, nothing) cv2.createTrackbar("Threshold2", "Trackbars", 200, 255, nothing) def valTrackbars(): Threshold1 = cv2.getTrackbarPos("Threshold1", "Trackbars") Threshold2 = cv2.getTrackbarPos("Threshold2", "Trackbars") src = Threshold1,Threshold2 return src
import cv2import numpy as npimport utlis ########################################################################webCamFeed = True #pathImage = "1.jpg" #cap = cv2.VideoCapture(1) #cap.set(10,160) #heightImg = 640 #widthImg = 480 ######################################################################### utlis.initializeTrackbars()count=0 while True: if webCamFeed: ret, img = cap.read() else: img = cv2.imread(pathImage) img = cv2.resize(img, (widthImg, heightImg)) imgBlank = np.zeros((heightImg,widthImg, 3), np.uint8) imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) imgBlur = cv2.GaussianBlur(imgGray, (5, 5), 1) # 添加高斯模糊 thres=utlis.valTrackbars() #获取阈值的轨迹栏值 imgThreshold = cv2.Canny(imgBlur,thres[0],thres[1]) # 应用CANNY模糊 kernel = np.ones((5, 5)) imgDial = cv2.dilate(imgThreshold, kernel, iterations=2) imgThreshold = cv2.erode(imgDial, kernel, iterations=1) # 查找所有轮廓 imgContours = img.copy() imgBigContour = img.copy() contours, hierarchy = cv2.findContours(imgThreshold, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # FIND ALL CONTOURS cv2.drawContours(imgContours, contours, -1, (0, 255, 0), 10) # 绘制所有检测到的轮廓 # 找到最大的轮廓 biggest, maxArea = utlis.biggestContour(contours) # 找到最大的轮廓 if biggest.size != 0: biggest=utlis.reorder(biggest) cv2.drawContours(imgBigContour, biggest, -1, (0, 255, 0), 20) # 画最大的轮廓 imgBigContour = utlis.drawRectangle(imgBigContour,biggest,2) pts1 = np.float32(biggest) # 为扭曲准备点 pts2 = np.float32([[0, 0],[widthImg, 0], [0, heightImg],[widthImg, heightImg]]) # 为扭曲准备点 matrix = cv2.getPerspectiveTransform(pts1, pts2) imgWarpColored = cv2.warpPerspective(img, matrix, (widthImg, heightImg)) #从每侧移除20个像素 imgWarpColored=imgWarpColored[20:imgWarpColored.shape[0] - 20, 20:imgWarpColored.shape[1] - 20] imgWarpColored = cv2.resize(imgWarpColored,(widthImg,heightImg)) # 应用自适应阈值 imgWarpGray = cv2.cvtColor(imgWarpColored,cv2.COLOR_BGR2GRAY) imgAdaptiveThre= cv2.adaptiveThreshold(imgWarpGray, 255, 1, 1, 7, 2) imgAdaptiveThre = cv2.bitwise_not(imgAdaptiveThre) imgAdaptiveThre=cv2.medianBlur(imgAdaptiveThre,3) # 用于显示的图像阵列 imageArray = ([img,imgGray,imgThreshold,imgContours], [imgBigContour,imgWarpColored, imgWarpGray,imgAdaptiveThre]) else: imageArray = ([img,imgGray,imgThreshold,imgContours], [imgBlank, imgBlank, imgBlank, imgBlank]) # 显示标签 lables = [["Original","Gray","Threshold","Contours"], ["Biggest Contour","Warp Prespective","Warp Gray","Adaptive Threshold"]] stackedImage = utlis.stackImages(imageArray,0.75,lables) cv2.imshow("Result",stackedImage) # 按下“s”键时保存图像 if cv2.waitKey(1) & 0xFF == ord('s'): cv2.imwrite("Scanned/myImage" str(count) ".jpg",imgWarpColored) cv2.rectangle(stackedImage, ((int(stackedImage.shape[1] / 2) - 230), int(stackedImage.shape[0] / 2) 50), (1100, 350), (0, 255, 0), cv2.FILLED) cv2.putText(stackedImage, "Scan Saved", (int(stackedImage.shape[1] / 2) - 200, int(stackedImage.shape[0] / 2)), cv2.FONT_HERSHEY_DUPLEX, 3, (0, 0, 255), 5, cv2.LINE_AA) cv2.imshow('Result', stackedImage) cv2.waitKey(300) count = 1 elif cv2.waitKey(1) & 0xFF == 27: break今天需要要讲解的还是主函数Main.py,由我来讲解,其实我也有点压力,因为这个项目它涉及了Opencv核心知识点,有的地方我也需要去查找,因为学久必会忘,更何况我也是刚刚起步的阶段,所以我会尽我所能的去讲清楚。
注意:我是以网络摄像头为例,读取图片的方式,同理可得。
首先,请看#号框内,我们将从这里开始起,设立变量webCamFeed,用其表示是否打开摄像头,接着亮度,宽,高的赋值。utlis.initializeTrackbars()是utlis.py文件当中的轨迹栏初始化函数。然后,我们依次对图像进行大小调整、灰度图像、高斯模糊、Canny边缘检测、扩张、侵蚀。之后,找出图像可以检测的所有轮廓,并找到最大的轮廓并且画出来,同时要为扫描到的文档找到四个顶点,也就是扭曲点,用cv2.getPerspectiveTransform()函数找到点的坐标,用cv2.warpPerspective()函数输出图像,如果到了这一步,我们去运行一下会发现有边角是桌子的颜色但并没有很多,所以我们需要从每侧移除20个像素,应用自适应阈值让图像变得较为清晰——黑色的文字更加的明显。接着,配置utlis.stackImages()需要的参数——图像(列表的形式),规模,标签(列表的形式,可以不用标签,程序一样可以正确运行),展示窗口。最后,如果你觉得比较满意,按下s键,即可保存,并在图中央出现有"Scan Saved"的矩形框。点击Esc键即可退出程序。
4,项目资源GitHUb:Opencv-project-training/Opencv project training/06 Document Scanner at main · Auorui/Opencv-project-training · GitHub
5,项目总结与评价它是一个很好的项目,要知道我们要实现这种效果,即修正文档,还得清晰,要么有VIP,兑换积分,看广告等。如果你发现扫描的文档不清晰,请修改合适的分辨率。
07 人脸识别和考勤系统
1、效果展示人脸识别:
考勤效果:
2、项目介绍
接下来,我们将学习如何以高精度执行面部识别,首先简要介绍理论并学习基本实现。然后我们将创建一个考勤项目,该项目将使用网络摄像头检测人脸并在 Excel 表中实时记录考勤情况。
3、项目基础理论(1)项目包的搭建在此之前,你应该看过此篇,完成了对项目包的搭建(37条消息) Python3.7最简便的方式解决下载dlib和face_recognition的问题_夏天是冰红茶的博客-CSDN博客
此外,我们还需要安装一个包,按照步骤来就好了:
(2)文件搭建
pip install face_recognition_models
按照图示配置,Attendance.csv文件当中的内容只有(Name,Time),在Attendance_images文件当中,你可以添加你想添加的图片,最好是单个人物的图片,且以他们的英文名命名图片。
(3)basic.py代码展示与讲解
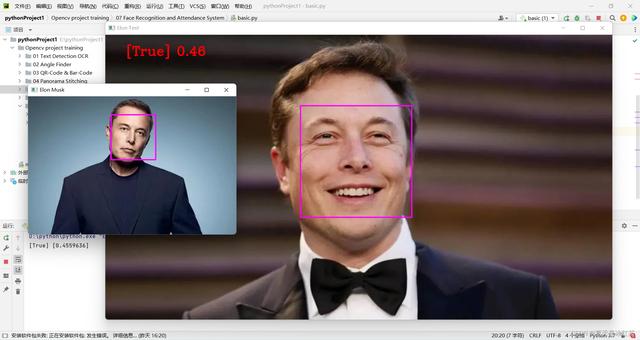
import cv2import face_recognition imgElon = face_recognition.load_image_file('ImagesBasic/Elon Musk.png')imgElon = cv2.cvtColor(imgElon, cv2.COLOR_BGR2RGB)imgTest = face_recognition.load_image_file('ImagesBasic/Elon test.png')imgTest = cv2.cvtColor(imgTest, cv2.COLOR_BGR2RGB) faceLoc = face_recognition.face_locations(imgElon)[0]encodeElon = face_recognition.face_encodings(imgElon)[0]cv2.rectangle(imgElon, (faceLoc[3], faceLoc[0]), (faceLoc[1], faceLoc[2]), (255, 0, 255), 2) faceLocTest = face_recognition.face_locations(imgTest)[0]encodeTest = face_recognition.face_encodings(imgTest)[0]cv2.rectangle(imgTest, (faceLocTest[3], faceLocTest[0]), (faceLocTest[1], faceLocTest[2]), (255, 0, 255), 2) results = face_recognition.compare_faces([encodeElon], encodeTest)faceDis = face_recognition.face_distance([encodeElon], encodeTest)print(results, faceDis)cv2.putText(imgTest, f'{results} {round(faceDis[0], 2)}', (50, 50), cv2.FONT_HERSHEY_COMPLEX, 1, (0, 0, 255), 2) cv2.imshow('Elon Musk', imgElon)cv2.imshow('Elon Test', imgTest)cv2.waitKey(0)我们将会以马斯克先生的图片,作为标准测试,即'Elon Musk.png'。另外两张图片分别是比尔盖茨先生和马斯克先生。
今天的讲解会分为两部分,这是基础部分的讲解。
首先,导入这两张代码中的图片,我们用的是face_recognition中的load_image_file函数,它会将图像文件(.jpg、.png等)加载到numpy数组中,且默认的mode='RGB'格式,故在此有一步转化。其次,faceLoc接受face_locations()函数返回的图像中人脸的边界框数组,请看注1,取第一个数,则会等到一个元组,我们要以按css(上、右、下、左)顺序找到的面位置的元组列表。encodeElon()函数是返回128维人脸编码列表(图像中每个人脸一个),为什么是128维?请看注2。在这之后,又是画框操作,我相信如果看过我前期的文章的人肯定是太熟悉了,按照注3,将坐标输入。之后,compare_faces()将面部编码列表与候选编码进行比较,以查看它们是否匹配,记住,只有第一个是列表,其将会返回真/假值列表;face_distance()需要给定人脸编码列表,将其与已知人脸编码进行比较,并获得每个比较人脸的欧几里德距离。距离会告诉您这些面有多相似。再说一次,只有第一个是列表。前看注4。最后,放置图框的信息在合适的位置,展示图片。
注1:[(44, 306, 152, 199)]
注2:机器学习很有趣!第4部分:现代人脸识别与深度学习 - 金融科技排名 (fintechranking.com),作者是Adam Geitgey 。
注3:坐标图
注4:[True] [0.4559636]
(5)效果展示
修改此处代码,我们初步实现了人脸识别。
imgTest = face_recognition.load_image_file('ImagesBasic/Bill Gates.png')imgTest = cv2.cvtColor(imgTest, cv2.COLOR_BGR2RGB)4、项目的代码展示与讲解
import cv2import numpy as npimport face_recognitionimport osfrom datetime import datetime # from PIL import ImageGrab path = 'Attendance_images'images = []classNames = []myList = os.listdir(path)print(myList)for cl in myList: curImg = cv2.imread(f'{path}/{cl}') images.append(curImg) classNames.append(os.path.splitext(cl)[0])print(classNames) def findEncodings(images): encodeList = [] for img in images: img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) encode = face_recognition.face_encodings(img)[0] encodeList.append(encode) return encodeList def markAttendance(name): with open('Attendance_lists.csv', 'r ') as f: myDataList = f.readlines() nameList = [] for line in myDataList: entry = line.split(',') nameList.append(entry[0]) if name not in nameList: now = datetime.now() dtString = now.strftime('%H:%M:%S') f.writelines(f'\n{name},{dtString}') #### FOR CAPTURING SCREEN RATHER THAN WEBCAM# def captureScreen(bbox=(300,300,690 300,530 300)):# capScr = np.array(ImageGrab.grab(bbox))# capScr = cv2.cvtColor(capScr, cv2.COLOR_RGB2BGR)# return capScr encodeListKnown = findEncodings(images)print('Encoding Complete') cap = cv2.VideoCapture(1) while True: success, img = cap.read() # img = captureScreen() imgS = cv2.resize(img, (0, 0), None, 0.25, 0.25) imgS = cv2.cvtColor(imgS, cv2.COLOR_BGR2RGB) facesCurFrame = face_recognition.face_locations(imgS) encodesCurFrame = face_recognition.face_encodings(imgS, facesCurFrame) for encodeFace, faceLoc in zip(encodesCurFrame, facesCurFrame): matches = face_recognition.compare_faces(encodeListKnown, encodeFace) faceDis = face_recognition.face_distance(encodeListKnown, encodeFace) # print(faceDis) matchIndex = np.argmin(faceDis) if matches[matchIndex]: name = classNames[matchIndex].upper() # print(name) y1, x2, y2, x1 = faceLoc y1, x2, y2, x1 = y1 * 4, x2 * 4, y2 * 4, x1 * 4 cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2) cv2.rectangle(img, (x1, y2 - 35), (x2, y2), (0, 255, 0), cv2.FILLED) cv2.putText(img, name, (x1 6, y2 - 6), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255), 2) markAttendance(name) cv2.imshow('Webcam', img) cv2.waitKey(1)这里面的一些操作,在我之前的博客中有讲过,且前面也讲的很清楚了,所以我会略讲。
首先,读取Attendance_images文件当中图片的名字,注意它是带有.png,而我们的命名并不需要它,所以取了一个[0]。其次,编写findEncodings()用于储存标准图像的编码,按照列表的形式。markAttendance()函数用于读取Attendance_lists.csv的文件信息,并写入Excel,其中还可写入时间。然后,剩余的一些,我相信参照上面的讲解应该没什么问题了。再说一下 y1, x2, y2, x1 = y1 * 4, x2 * 4, y2 * 4, x1 * 4,为什么要乘以4,还记得上面的resize吗,它并没有要求像素的改变,而是缩小的比例,正是0.25。
5、项目素材Github:Opencv-project-training/Opencv project training/07 Face Recognition and Attendance System at main · Auorui/Opencv-project-training · GitHub
6、项目总结今天的项目比起之前的物体检测还有一定的难度,对于我来说现在的效率实在不是很高,昨天的dlib和face_recognition包的下载实在没有弄好,临时换了个项目,今天也是弄了好久。
08 Yolov3更高精度的检测物体
1、效果展示本次物体检测,将采用新的方法,相比于上一次,它的检测效果更好,具体在下面的项目介绍当中 ,本次检测的物品有手机、牙刷、剪刀、杯子、运动球、书等。检测的这些物品是方便展示的,本来还有水果的,但昨天都吃完了,只有核桃了,大家做好后,可以自己去试试
2、项目介绍在本项目中,我们将用新的方法对物体的检测,采用了Yolov3,当然它又有检测范围,只能鉴定我们给予的文件当中的物体,但它相较于我们之前的物体检测又有更高的精度,没有出现边界框闪烁,重叠的问题。
3、项目搭建如图所示,其中有些文件是我从官网上下载的,那么为了说清楚它的来源,我还是写下来,以免读者看了云里雾里。
输入此网址 :YOLO:实时对象检测 (pjreddie.com)
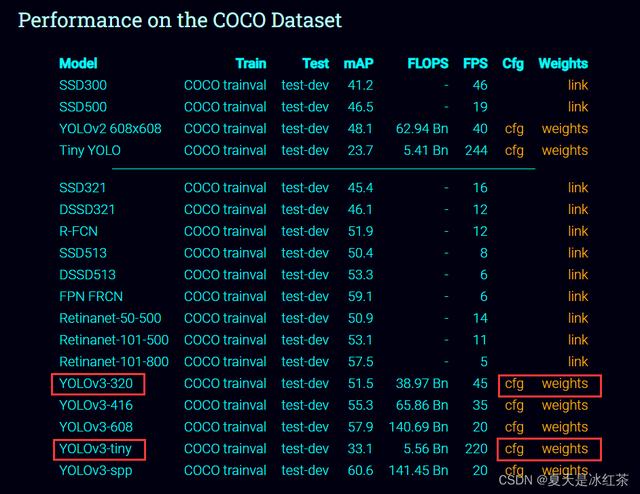
下载两种是为了比较一下它们的一些优缺点,320指的是分辨率320*320,它的检测能力属于中间吧,不过它的帧速率比起tiny要小很多,但又要比tiny的精度较高。
而coco.names是我从之前的《Opencv项目实战:05 物体检测》的一个文件,ctrl cv过来的,不知道的可以看看此篇。(16条消息) Opencv项目实战:05 物体检测_夏天是冰红茶的博客-CSDN博客,或许你先看这篇后,更容易理解此篇。
再提一句,下载cfg是在Github里面,如果网速较慢的,可以给我评论,我考虑一下抽点时间,将Github的一些加速的方法总结一篇。
4,项目知识预备如有不知道的地方再回头来看,现在看一遍,加一点表面印象,不要求理解。
架构图:
我们可以看到这个网络,有很多层,中间的部分有很多的卷积层,而我们需要的就是末尾的那三层。
打印outputs[0][0]:
[3.8534008e-02 6.2166303e-02 4.4057447e-01 1.9734769e-01 5.1320876e-090.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00]
85的含义:
85含有中心x,y,宽,高,物体的置信度 ,其余的是每个类别的预测概率,也就是value number
x, y = int((det[0] * wT) - w / 2), int((det[1] * hT) - h / 2) 手绘图版本:
真的随手画,哈哈。大家可以理解到就成。
关于coco.names文件:
与项目5当中的文件有所区别,大家按照项目介绍当中的图对其中的内容进行删改即可。
5、项目的代码与讲解
import cv2 as cvimport numpy as np cap = cv.VideoCapture(0)whT = 320confThreshold = 0.5nmsThreshold = 0.2 #the lower it is the more aggressive it will beprint(f"以下是你可以检测的{80}种物品:") #### LOAD MODEL#########################################导入coco.names文件当中的内容classesFile = "coco.names" #classNames = [] #with open(classesFile, 'rt') as f: # classNames = f.read().rstrip('\n').split('\n') #print(classNames) ####################################################### #### Model Files##################################################### 引进我们的模块modelConfiguration = "yolov3-320.cfg" #modelWeights = "yolov3-320.weights" #net = cv.dnn.readNetFromDarknet(modelConfiguration, modelWeights) # net.setPreferableBackend(cv.dnn.DNN_BACKEND_OPENCV) # net.setPreferableTarget(cv.dnn.DNN_TARGET_CPU) # ################################################################### def findObjects(outputs, img): hT, wT, cT = img.shape bbox = [] classIds = [] confs = [] for output in outputs: for det in output: scores = det[5:] #我们需要寻找某一个类中,判别最高的 classId = np.argmax(scores) confidence = scores[classId] if confidence > confThreshold: w, h = int(det[2] * wT), int(det[3] * hT) #值是百分比,乘以图像的大小才是正确的像素值 x, y = int((det[0] * wT) - w / 2), int((det[1] * hT) - h / 2) bbox.append([x, y, w, h]) classIds.append(classId) confs.append(float(confidence)) indices = cv.dnn.NMSBoxes(bbox, confs, confThreshold, nmsThreshold) #置信度阈值以及nms的阈值 # print(indices) for i in indices: box = bbox[i] x, y, w, h = box[0], box[1], box[2], box[3] # print(x,y,w,h) cv.rectangle(img, (x, y), (x w, y h), (255, 0, 255), 2) cv.putText(img, f'{classNames[classIds[i]].upper()} {int(confs[i] * 100)}%', (x, y - 10), cv.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 255), 2) while True: success, img = cap.read() blob = cv.dnn.blobFromImage(img, 1 / 255, (whT, whT), [0, 0, 0], 1, crop=False) net.setInput(blob) layersNames = net.getLayerNames() # print(layersNames) # print(net.getUnconnectedOutLayers()) outputNames = [(layersNames[i - 1]) for i in net.getUnconnectedOutLayers()] # print(outputNames) outputs = net.forward(outputNames) # print(len(outputs)) #检测是否取到我们需要的那三层,输出为3,True outputs=list(outputs) #输出之前是元组 # print(type(outputs[0])) #<class 'numpy.ndarray'> ########################################## # print(outputs[0].shape) #(300, 85) 300,1200,4800 is is the number of bounding boxes # print(outputs[1].shape) #(1200, 85) # print(outputs[2].shape) #(4800, 85) # print(outputs[0][0]) ########################################## findObjects(outputs, img) cv.imshow('Image', img) if cv.waitKey(1) & 0xFF ==27: break我们一口气讲完,准备了这些天,也不是白费的,当然有些地方,可能我讲的不是那么清楚,请见谅。但好在这次我将调试的所有过程都保留了下来,结合注释和我的讲解,7788应当是有的。
首先,开头部分都是些后来设置的默认条件,等用到的时候再将。我们需要导入我们的"coco.names文件",它是每个单词为一行,所以通过文件操作,将其中内容放入到一个新的列表当中,我们用到了read()、rstrip()、split()函数,不清楚的地方,可以去W3school上查询。其次,引入我们从官网下载的文件,用到了readNetFromDarknet()函数,它的参数是模型配置和权重配置,也就是我们下载的模块,他会读取存储在<a href=”中的网络模型https://pjreddie.com/darknet/“>Darknet</a>模型文件,返回一个网络对象,这正是我们想要的。net.setPreferableBackend()要求网络使用其支持的特定计算后,它的参数需要我们给定为cv.dnn.DNN_BACKEND_OPENCV,因为它是具有一个默认的值。net.setPreferableTarget()要求网络在特定目标设备上进行计算,我选择使用的是CPU,当然要想获得更高的精度,就要使用GPU,但我并不了解,所以点到为止哈。其次,我们再来讲解while True循环中的代码,读取摄像头,创建我们的网络,将图像转化为blob的形式,因为这是网络可以理解的形式,里面的参数我讲一下(whT,whT),其余的就是默认了,在开始时就已经定义了为320,那为什么是320,因为yolov3-320.cfg等,就是这个原因啦,它的分辨率就是320*320;net.setInput(blob) 就是设置网络前行的通行证;接下来,我们要获得我们最感兴趣的那三层,用net.getLayerNames()函数获取所有层的名字,在得到三个不同的输出层的索引值,接着用列表生成式,根据索引将内容放进去,得到['yolo_82', 'yolo_94', 'yolo_106']。net.forward(outputNames)返回指定层的第一个输出的blob。再往下就是我的一些调试过程,我保留了调试时的注释,不懂的地方,不妨就取消注释,跑一遍就成。然后,再来讲解我们的 findObjects(outputs, img)里面的内容,获取图像的宽高通道,设置空列表,放置边界框,Id,置信度等,那么下面的操作就是为了将这些空列表填满!!!,我们在上面有展示过outputs[0][0]的输出,我们不能将中心x,中心y,宽,高,置信度等作比较,因为它们相对较大,索引是从第五个开始,然后便是我所说的填满操作,应该不难,我们就此跳过。紧接着,来到尾声了,我们常会有检测时出现大小框,那么这是就需要处理,得到检测较大的那个框,让我们的检测更加的完善,cv.dnn.NMSBoxes()函数,参数confThreshold已经在开头定义,检测的大于50%,那就相当好了,nms_threshold用于非最大抑制的阈值,也是实现定义好了,这个用法我们在《Opencv项目实战:05 物体检测》就讲到过。然后就是画框,放文本的操作,几乎我们每一期的实战项目都在讲。最后,引用findObjects(outputs, img)函数,开启摄像头,展示窗口,检测物体,完成后点击Esc键即可退出。
6、项目素材GitHub:Opencv-project-training/Opencv project training/08 Yolov3 at main · Auorui/Opencv-project-training · GitHub
其中以下两个文件需要从官网下载,GitHub上面由于太大上传不了。
7、项目总结
我写的较为的详细,几乎没有我这种风格的吧,我是学c语言出生的(是我们大一的必修课,说实话我以前根本就不知道的,可能这就是小镇做题家的原因吧),后来今年的二月自学的python,中途学了些爬虫,七月在参加实验室学了点单片机(我没有基础,也被刷下去了,keil5配文件麻烦死了),给我们安排的课程python的图像处理只有区区两节,也是这两节课才对Opencv感了兴趣,自己私下在学习,后来我发现刚好学的这些东西,都是涉及人工智能领域,计算机视觉的,我想我自己一定要做出点成就来,给大家更新的系列也是我学习的过程。
1、效果展示本次物体检测,将采用新的方法,相比于上一次,它的检测效果更好,具体在下面的项目介绍当中 ,本次检测的物品有手机、牙刷、剪刀、杯子、运动球、书等。检测的这些物品是方便展示的,本来还有水果的,但昨天都吃完了,只有核桃了,大家做好后,可以自己去试试
2、项目介绍在本项目中,我们将用新的方法对物体的检测,采用了Yolov3,当然它又有检测范围,只能鉴定我们给予的文件当中的物体,但它相较于我们之前的物体检测又有更高的精度,没有出现边界框闪烁,重叠的问题。
3、项目搭建如图所示,其中有些文件是我从官网上下载的,那么为了说清楚它的来源,我还是写下来,以免读者看了云里雾里。
输入此网址 :YOLO:实时对象检测 (pjreddie.com)https://pjreddie.com/darknet/yolo/
下载两种是为了比较一下它们的一些优缺点,320指的是分辨率320*320,它的检测能力属于中间吧,不过它的帧速率比起tiny要小很多,但又要比tiny的精度较高。
而coco.names是我从之前的《Opencv项目实战:05 物体检测》的一个文件,ctrl cv过来的,不知道的可以看看此篇。
再提一句,下载cfg是在Github里面,如果网速较慢的,可以给我评论,我考虑一下抽点时间,将Github的一些加速的方法总结一篇。
4,项目知识预备如有不知道的地方再回头来看,现在看一遍,加一点表面印象,不要求理解。
架构图:
我们可以看到这个网络,有很多层,中间的部分有很多的卷积层,而我们需要的就是末尾的那三层。
打印outputs[0][0]:
[3.8534008e-02 6.2166303e-02 4.4057447e-01 1.9734769e-01 5.1320876e-090.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 000.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00 0.0000000e 00]
85的含义:
85含有中心x,y,宽,高,物体的置信度 ,其余的是每个类别的预测概率,也就是value number
x, y = int((det[0] * wT) - w / 2), int((det[1] * hT) - h / 2) 手绘图版本:
真的随手画,哈哈。大家可以理解到就成。
关于coco.names文件:
与项目5当中的文件有所区别,大家按照项目介绍当中的图对其中的内容进行删改即可。
5、项目的代码与讲解
import cv2 as cvimport numpy as np cap = cv.VideoCapture(0)whT = 320confThreshold = 0.5nmsThreshold = 0.2 #the lower it is the more aggressive it will beprint(f"以下是你可以检测的{80}种物品:") #### LOAD MODEL#########################################导入coco.names文件当中的内容classesFile = "coco.names" #classNames = [] #with open(classesFile, 'rt') as f: # classNames = f.read().rstrip('\n').split('\n') #print(classNames) ####################################################### #### Model Files##################################################### 引进我们的模块modelConfiguration = "yolov3-320.cfg" #modelWeights = "yolov3-320.weights" #net = cv.dnn.readNetFromDarknet(modelConfiguration, modelWeights) # net.setPreferableBackend(cv.dnn.DNN_BACKEND_OPENCV) # net.setPreferableTarget(cv.dnn.DNN_TARGET_CPU) # ################################################################### def findObjects(outputs, img): hT, wT, cT = img.shape bbox = [] classIds = [] confs = [] for output in outputs: for det in output: scores = det[5:] #我们需要寻找某一个类中,判别最高的 classId = np.argmax(scores) confidence = scores[classId] if confidence > confThreshold: w, h = int(det[2] * wT), int(det[3] * hT) #值是百分比,乘以图像的大小才是正确的像素值 x, y = int((det[0] * wT) - w / 2), int((det[1] * hT) - h / 2) bbox.append([x, y, w, h]) classIds.append(classId) confs.append(float(confidence)) indices = cv.dnn.NMSBoxes(bbox, confs, confThreshold, nmsThreshold) #置信度阈值以及nms的阈值 # print(indices) for i in indices: box = bbox[i] x, y, w, h = box[0], box[1], box[2], box[3] # print(x,y,w,h) cv.rectangle(img, (x, y), (x w, y h), (255, 0, 255), 2) cv.putText(img, f'{classNames[classIds[i]].upper()} {int(confs[i] * 100)}%', (x, y - 10), cv.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 255), 2) while True: success, img = cap.read() blob = cv.dnn.blobFromImage(img, 1 / 255, (whT, whT), [0, 0, 0], 1, crop=False) net.setInput(blob) layersNames = net.getLayerNames() # print(layersNames) # print(net.getUnconnectedOutLayers()) outputNames = [(layersNames[i - 1]) for i in net.getUnconnectedOutLayers()] # print(outputNames) outputs = net.forward(outputNames) # print(len(outputs)) #检测是否取到我们需要的那三层,输出为3,True outputs=list(outputs) #输出之前是元组 # print(type(outputs[0])) #<class 'numpy.ndarray'> ########################################## # print(outputs[0].shape) #(300, 85) 300,1200,4800 is is the number of bounding boxes # print(outputs[1].shape) #(1200, 85) # print(outputs[2].shape) #(4800, 85) # print(outputs[0][0]) ########################################## findObjects(outputs, img) cv.imshow('Image', img) if cv.waitKey(1) & 0xFF ==27: break我们一口气讲完,准备了这些天,也不是白费的,当然有些地方,可能我讲的不是那么清楚,请见谅。但好在这次我将调试的所有过程都保留了下来,结合注释和我的讲解,7788应当是有的。
首先,开头部分都是些后来设置的默认条件,等用到的时候再将。我们需要导入我们的"coco.names文件",它是每个单词为一行,所以通过文件操作,将其中内容放入到一个新的列表当中,我们用到了read()、rstrip()、split()函数,不清楚的地方,可以去W3school上查询。其次,引入我们从官网下载的文件,用到了readNetFromDarknet()函数,它的参数是模型配置和权重配置,也就是我们下载的模块,他会读取存储在<a href=”中的网络模型https://pjreddie.com/darknet/“>Darknet</a>模型文件,返回一个网络对象,这正是我们想要的。net.setPreferableBackend()要求网络使用其支持的特定计算后,它的参数需要我们给定为cv.dnn.DNN_BACKEND_OPENCV,因为它是具有一个默认的值。net.setPreferableTarget()要求网络在特定目标设备上进行计算,我选择使用的是CPU,当然要想获得更高的精度,就要使用GPU,但我并不了解,所以点到为止哈。其次,我们再来讲解while True循环中的代码,读取摄像头,创建我们的网络,将图像转化为blob的形式,因为这是网络可以理解的形式,里面的参数我讲一下(whT,whT),其余的就是默认了,在开始时就已经定义了为320,那为什么是320,因为yolov3-320.cfg等,就是这个原因啦,它的分辨率就是320*320;net.setInput(blob) 就是设置网络前行的通行证;接下来,我们要获得我们最感兴趣的那三层,用net.getLayerNames()函数获取所有层的名字,在得到三个不同的输出层的索引值,接着用列表生成式,根据索引将内容放进去,得到['yolo_82', 'yolo_94', 'yolo_106']。net.forward(outputNames)返回指定层的第一个输出的blob。再往下就是我的一些调试过程,我保留了调试时的注释,不懂的地方,不妨就取消注释,跑一遍就成。然后,再来讲解我们的 findObjects(outputs, img)里面的内容,获取图像的宽高通道,设置空列表,放置边界框,Id,置信度等,那么下面的操作就是为了将这些空列表填满!!!,我们在上面有展示过outputs[0][0]的输出,我们不能将中心x,中心y,宽,高,置信度等作比较,因为它们相对较大,索引是从第五个开始,然后便是我所说的填满操作,应该不难,我们就此跳过。紧接着,来到尾声了,我们常会有检测时出现大小框,那么这是就需要处理,得到检测较大的那个框,让我们的检测更加的完善,cv.dnn.NMSBoxes()函数,参数confThreshold已经在开头定义,检测的大于50%,那就相当好了,nms_threshold用于非最大抑制的阈值,也是实现定义好了,这个用法我们在《Opencv项目实战:05 物体检测》就讲到过。然后就是画框,放文本的操作,几乎我们每一期的实战项目都在讲。最后,引用findObjects(outputs, img)函数,开启摄像头,展示窗口,检测物体,完成后点击Esc键即可退出。
6、项目素材GitHub:https://github.com/Auorui/Opencv-project-training/tree/main/Opencv project training/08 Yolov3
其中以下两个文件需要从官网下载,GitHub上面由于太大上传不了。
7、项目总结
我写的较为的详细,几乎没有我这种风格的吧,我是学c语言出生的(是我们大一的必修课,说实话我以前根本就不知道的,可能这就是小镇做题家的原因吧),后来今年的二月自学的python,中途学了些爬虫,七月在参加实验室学了点单片机(我没有基础,也被刷下去了,keil5配文件麻烦死了),给我们安排的课程python的图像处理只有区区两节,也是这两节课才对Opencv感了兴趣,自己私下在学习,后来我发现刚好学的这些东西,都是涉及人工智能领域,计算机视觉的,我想我自己一定要做出点成就来,给大家更新的系列也是我学习的过程。
09 物体尺寸测量
1、效果展示我们将以两种方式来展示我们这个项目的效果。
下面这是视频的实时检测,我分别用了盒子和盖子来检测,按理来说效果不应该怎么差的,但我实在没有找到合适的背景与物体。且我的摄像头使用的是外设,我不得不手持,所以存在一点点的抖动,但我可以保证,它是缺少了适合检测物体与背景。
我使用手机拍了一张照片并经过了ps修改了背景,效果不错。
2、项目介绍
本项目中,我将选用A4纸张为背景,找到放在该区域中对象的长、宽。打印出相关的数值。
3、项目搭建
所有的资源,你都可以在我的GitHub上找到,我将在末尾附上链接
4、utils.py文件代码展示与讲解在项目当中,我将引入utils,而utils是适用于在我们项目中所写的的文件。有了对它的理解能帮助我们更好的理解本项目,所以我觉得有必要在此叙述一番。
import cv2import numpy as np def getContours(img, cThr=[100, 100], showCanny=False, minArea=1000, filter=0, draw=False): imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) imgBlur = cv2.GaussianBlur(imgGray, (5, 5), 1) imgCanny = cv2.Canny(imgBlur, cThr[0], cThr[1]) kernel = np.ones((5, 5)) imgDial = cv2.dilate(imgCanny, kernel, iterations=3) imgThre = cv2.erode(imgDial, kernel, iterations=2) if showCanny: cv2.imshow('Canny', imgThre) contours, hiearchy = cv2.findContours(imgThre, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) finalCountours = [] for i in contours: area = cv2.contourArea(i) if area > minArea: peri = cv2.arcLength(i, True) approx = cv2.approxPolyDP(i, 0.02 * peri, True) bbox = cv2.boundingRect(approx) if filter > 0: if len(approx) == filter: finalCountours.append([len(approx), area, approx, bbox, i]) else: finalCountours.append([len(approx), area, approx, bbox, i]) finalCountours = sorted(finalCountours, key=lambda x: x[1], reverse=True) if draw: for con in finalCountours: cv2.drawContours(img, con[4], -1, (0, 0, 255), 3) return img, finalCountours def reorder(myPoints): # print(myPoints.shape) myPointsNew = np.zeros_like(myPoints) myPoints = myPoints.reshape((4, 2)) add = myPoints.sum(1) myPointsNew[0] = myPoints[np.argmin(add)] myPointsNew[3] = myPoints[np.argmax(add)] diff = np.diff(myPoints, axis=1) myPointsNew[1] = myPoints[np.argmin(diff)] myPointsNew[2] = myPoints[np.argmax(diff)] return myPointsNew def warpImg(img, points, w, h, pad=20): # print(points) points = reorder(points) pts1 = np.float32(points) pts2 = np.float32([[0, 0], [w, 0], [0, h], [w, h]]) matrix = cv2.getPerspectiveTransform(pts1, pts2) imgWarp = cv2.warpPerspective(img, matrix, (w, h)) imgWarp = imgWarp[pad:imgWarp.shape[0] - pad, pad:imgWarp.shape[1] - pad] return imgWarp def findDis(pts1, pts2): return ((pts2[0] - pts1[0]) ** 2 (pts2[1] - pts1[1]) ** 2) ** 0.5接下来,我将按照惯例讲解,我们就以每个函数的意义来讲。
- getContours()函数,曾在我以前的博客中出现过。正如它的命名,我们是为了得到轮廓。将原始图像依次经过这些转化:灰度图像、高斯模糊、canny检测边缘、膨胀、侵蚀等。 cv2.findContours()从图像ROI中提取轮廓,然后在整个图像上下文中分析轮廓,参数cv2.RETR_EXTERNAL将会获取外部边缘; cv2.contourArea()计算轮廓面积; cv2.contourArea()计算轮廓周长或曲线长度; cv2.approxPolyDP()以指定精度近似多边形曲线; cv2.boundingRect()函数计算并返回指定点集或灰度图像非零像素的最小右上边界矩形; 之后用finalCountours这个空列表来接受我们需要用到的信息,再对其轮廓的大小进行排序,因为我们需要的是最大的边界框。 cv2.drawContours()绘制轮廓轮廓或填充轮廓,最后返回img, finalCountours。
- reorder函数,myPointsNew = np.zeros_like(myPoints),返回与myPoints具有相同形状和类型的零数组,在打印了myPoints.shape,它所返回的值是(4,1,2),不难理解,4指的是四个点,2指的是x,y,我们不需要中间的1,所以要对其进行重塑。np.argmin返回沿轴的最小值的索引,np.argmax返回沿轴的最大值的索引。所以此函数的作用是将顺序改为最下面的顺序。
4.warpImg()函数,其实就是透视变换,详细的函数可以回头复习一下Opencv的文档,我在此不做多的讲述。
5.findDis()函数我们用一张图来解释,个人手绘:
4、项目代码展示与讲解
import cv2import utils ###################################webcam = Falsepath = '1.png'cap = cv2.VideoCapture(1)cap.set(10, 160)cap.set(3, 1920)cap.set(4, 1080)scale = 3wP = 210 * scalehP = 297 * scale################################### while True: if webcam: success, img = cap.read() else: img = cv2.imread(path) imgContours, conts = utils.getContours(img, minArea=50000, filter=4) if len(conts) != 0: biggest = conts[0][2] # print(biggest) imgWarp = utils.warpImg(img, biggest, wP, hP) imgContours2, conts2 = utils.getContours(imgWarp, minArea=2000, filter=4, cThr=[50, 50], draw=False) if len(conts) != 0: for obj in conts2: cv2.polylines(imgContours2, [obj[2]], True, (0, 255, 0), 2) nPoints = utils.reorder(obj[2]) nW = round((utils.findDis(nPoints[0][0] // scale, nPoints[1][0] // scale) / 10), 1) nH = round((utils.findDis(nPoints[0][0] // scale, nPoints[2][0] // scale) / 10), 1) cv2.arrowedLine(imgContours2, (nPoints[0][0][0], nPoints[0][0][1]), (nPoints[1][0][0], nPoints[1][0][1]), (255, 0, 255), 3, 8, 0, 0.05) cv2.arrowedLine(imgContours2, (nPoints[0][0][0], nPoints[0][0][1]), (nPoints[2][0][0], nPoints[2][0][1]), (255, 0, 255), 3, 8, 0, 0.05) x, y, w, h = obj[3] cv2.putText(imgContours2, '{}cm'.format(nW), (x 30, y - 10), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1.5, (255, 0, 255), 2) cv2.putText(imgContours2, '{}cm'.format(nH), (x - 70, y h // 2), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1.5, (255, 0, 255), 2) cv2.imshow('A4', imgContours2) img = cv2.resize(img, (0, 0), None, 0.5, 0.5) cv2.imshow('Original', img) if cv2.waitKey(1) & 0xFF ==27: break那么,本项目的代码我看了一下,将utils.py文件看懂之后,不难理解,所以本项目我就不仔细讲解了。
5、项目资源GitHub:https://github.com/Auorui/Opencv-project-training/tree/main/Opencv project training/09 Object Size Measurement
6、项目总结本项目主要是运用了之前扫描文档的思想,以A4纸为背景,检测其中区域的物体长和宽。我的摄像头无法固定,所以是手持的,且由于我在寝室里面是真的没有找到合适的测量物体以及背景色(全是米色或原木色的)。所以效果有所欠缺,但经过ps修改的图片,检测的效果还是很不错的。
那么祝你在本项目中玩的开心,否则我会在下一次项目中见到你!!!
,









































































免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






