r语言在做双向回归分析之前的步骤(R语言实战-02-回归诊断-多重共线性与异常值)
- ☸ 多重共线性
- ☸ 异常观测值
- ✡ 离群点
- ✡ 高杠杆值点
- ✡ 强影响点
- ☸ 改进措施
本系列是对 《R语言实战》感兴趣部分的阅读笔记,学习的目的在于理解函数,理解图像含义
☸ 多重共线性让我们来看一个比较重要的问题,它与统计假设没有直接关联,但是对于解释多元回归的结果非常重要。
假设你正在进行一项握力研究,自变量包括DOB(Date Of Birth,出生日期)和年龄。
你用握力对DOB和年龄进行回归,F检验显著,p<0.001。
但是当你观察DOB和年龄的回归系数时,却 发现它们都不显著(也就是说无法证明它们与握力相关)。
到底发生了什么呢?
原因是DOB与年龄在四舍五入后相关性极大。
回归系数测量的是当其他预测变量不变时,某个预测变量对响应变量的影响。那么此处就相当于假定年龄不变,然后测量握力与年龄的关系, 这种问题就称作多重共线性(multicollinearity)。
它会导致模型参数的置信区间过大,使单个系数 解释起来很困难。
多重共线性可用统计量VIF(Variance Inflation Factor,方差膨胀因子)进行检测。VIF的平方根表示变量回归参数的置信区间能膨胀为与模型无关的预测变量的程度(因此而得名)。car 包中的vif()函数提供VIF值。一般原则下, vifvif的开根号 >2就表明存在多重共线性问题。
☸ 异常观测值✡ 离群点
#检测多重共线性 library(car) vif(fit) sqrt(vif(fit)) > 2 Population 1.24528200205236 Illiteracy 2.16584830171514 Income 1.34582173068518 Frost 2.08254682072994 Population FALSE Illiteracy FALSE Income FALSE Frost FALSE离群点是指那些模型预测效果不佳的观测点。它们通常有很大的、或正或负的残差。
正的残差说明模型低估了响应值,
负的残差则说明高估了响应值。
其中一种鉴别离群点的方法是:Q-Q图,落在置信区间大歪的点即可被认为是离群点。
另外一种粗糙的判断准则:标准化残差值大于2或者小于-2的点可能是离群点,需要特别关注。
car包提供一种离群点的统计检验方法。
outlierTest()函数可以求得最大标准化残差绝对值Bonferroni调整后的p值
library(car) outlierTest(fit) # Nevada被判定为离群点(p=0.048) #该函数只是根据单个最大(或正或负)残差值的显著性来判断是否有离群点。 #若不显著,则说明数据集中没有离群点, #若显著,则必须删除该离群点,然后再检验是否还有其他离群点存在。 out: rstudent unadjusted p-value Bonferroni p Nevada 3.542929 0.00095088 0.047544此处,你可以看到Nevada被判定为离群点(p=0.048)。注意,该函数只是根据单个最大(或正或负)残差值的显著性来判断是否有离群点。若不显著,则说明数据集中没有离群点;若显著, 则你必须删除该离群点,然后再检验是否还有其他离群点存在。
✡ 高杠杆值点即与其他预测变量有关的离群点。
换句话说,它们是有许多异常的预测变量值组合起来的,与响应变量值没有关系。
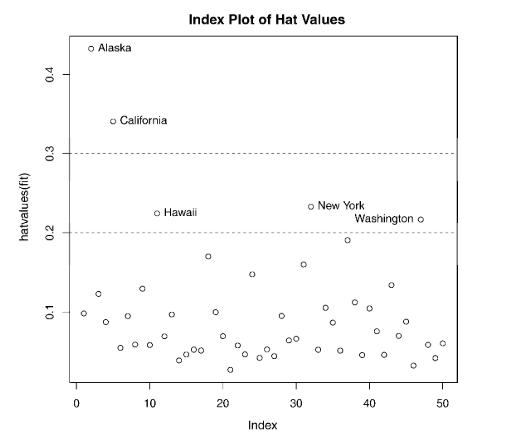
高杠杆值的观测点可通过帽子统计量(hat statistic)判断。
对于一个给定的数据集,帽子均值为p/n,其中p是模型估计的参数数目(包含截距项),n是样本量。
一般来说,若观测点的帽子值大于帽子均值的2或3倍,就可以认定为高杠杆值点。
hat.plot <- function(fit){ p <- length(coefficients(fit)) n <- length(fitted(fit)) plot(hatvalues(fit),main = "Index Plot of Hat Values") abline(h=c(2,3)*p/n, col="red",lty=2) identify(1:n, hatvalues(fit),names(hatvalues(fit))) } hat.plot(fit)result:
水平线标注的即帽子均值2倍和3倍的位置。定位函数(locator function)能以交互模式绘图: 单击感兴趣的点,然后进行标注,停止交互时,用户可按Esc键退出,或从图形下拉菜单中选择 Stop,或直接右击图形。
此图中,可以看到Alaska和California非常异常,查看它们的预测变量值,与其他48个州进行比较发现:Alaska收入比其他州高得多,而人口和温度却很低;California人口比其他州府多得多, 但收入和温度也很高。 高杠杆值点可能是强影响点,也可能不是,这要看它们是否是离群点。
✡ 强影响点即对模型参数估计值影响有些比例失衡的点。
例如:若移除模型的一个观测点事模型会发生巨大的改变,那么你就需要检测一下数据中是否存在强影响点。
两种方法检测强影响点:
Cook距离,或称D统计量,以及变量添加图。
一般来说,Cook’s D值大于4/(n-k-1),则表明他是强影像点,其中n为样本量大小,k是预测变量数目。
#鉴别强影像点的Cook's D图 cutoff <- 4/(nrow(states)-length(fit$coefficients)-2) plot(fit, which=4, cook.levels=cutoff) abline(h=cutoff, lty=2, col="red")
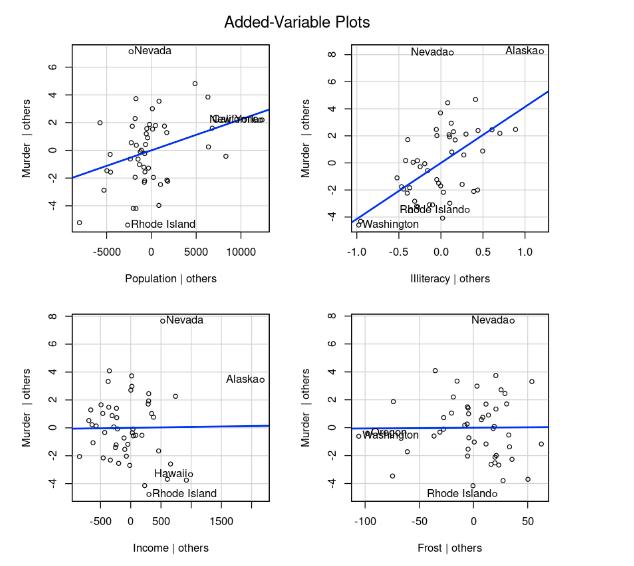
变量添加图,即对于每个预测变量Xk,绘制Xk在其他k–1个预测变量上回归的残差值相
对于响应变量在其他k–1个预测变量上回归的残差值的关系图。
library(car) avPlots(fit, ask=FALSE, id.method="identify")result
利用car包中的influencePlot()函数,你还可以将离群点、杠杆值和强影响点的信息整合到一幅图形中:
纵坐标超过 2或小于–2的州可被认为是离群点,水平轴超过0.2或0.3 的州有高杠杆值(通常为预测值的组合)。圆圈大小与影响成比例,圆圈很大 的点可能是对模型参数的估计造成的不成比例影响的强影响点
图8-16反映出Nevada和Rhode Island是离群点,New York、California、Hawaii和Washington 有高杠杆值,Nevada、Alaska和Hawaii为强影响点
☸ 改进措施我们已经花费了不少篇幅来学习回归诊断,你可能会问:“如果发现了问题,那么能做些什么呢?
”有四种方法可以处理违背回归假设的问题:
- 删除观测点;
- 变量变换;
- 添加或删除变量;
- 使用其他回归方法。
阅读至此,改进措施将会在下一篇文章予以记录。
,


免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






