用numpy计算向量之间的欧氏距离(基于numpy.einsum的张量网络计算)
目录
- 张量与张量网络
- 张量缩并顺序与计算复杂性
- 张量分割对张量网络缩并复杂性的影响
- 补充测试
- 总结概要
- 版权声明
- 参考链接
张量(Tensor)可以理解为广义的矩阵,其主要特点在于将数字化的矩阵用图形化的方式来表示,这就使得我们可以将一个大型的矩阵运算抽象化成一个具有良好性质的张量图。由一个个张量所共同构成的运算网络图,就称为张量网络(Tensor Network)。让我们用几个常用的图来看看张量网络大概长什么样子(下图转载自参考链接1):

上面这个图从左到右分别表示:一阶张量、二阶张量以及三阶张量,我们可以看出,一个张量的阶数在图像化的表示中被抽象称为了张量的腿的数量,而中间的方形或者圆形则表示张量本身。实际上,一阶张量代表的一个矢量,比如我们平时用python所定义的一个数组变量:
x = [1, 0]
y = [0, 1, 0]
z = [1, 2, 3, 4]
那么这里的x,y,z都是一阶的张量。而二阶张量所表示的含义是一个二维的矩阵,如我们常见的python多维数组:
M = [[1, -1], [-1, 1]]
N = [[1, 3], [2, 4], [5, 6]]
这里定义的M, N都是二阶的张量。通过观察这些示例中的一阶和二阶的张量我们可以得到一个规律:能够用形如var[i]的形式读取和遍历var中的标量元素的就可以称之为一阶张量,能够用形如var[i][j]的形式读取和遍历var中的标量元素的可以称之为二阶张量。显然,属于几阶的张量,跟张量内所包含的元素个数是无关的。那么根据这个客观规律,我们可以再推广到零阶张量和更加高阶的张量:
pi = 3.14
P = [[[1]]]
Q = [[[1, 1, 1], [1, 1, 1], [1, 1, 1]]]
在上述的python变量定义中,pi就是一个零阶的张量,零阶张量实际上就等同于一个标量,而P, Q都是三阶的张量。需要注意的是,虽然张量P只有一个元素,但是如果我们需要读取这个标量元素,我们必须使用如下的python指令来执行:
print (P[0][0][0])
因此P也是一个有三条腿的张量。在使用张量的形式来表示单个矩阵的同时,我们需要考虑如果有多个矩阵的乘法运算,我们该如何表示?我们先以两种形式的python矩阵运算来说明张量计算的表示方法:
import numpy as np
M = np.random.rand(2, 2)
v = np.random.rand(2)
w = np.dot(M, v)
print (M)
print (v)
print (w)
这一串python代码表示的计算过程为:w2×1=M2×2⋅v2×1,为了不失广泛有效性,这里使用随机的张量来进行计算,这里的M表示二阶张量,v,w表示一阶张量。如果从矩阵运算的角度来理解,实际上就是一个2×2的矩阵乘以一个2×1的矢量,并且得到了一个新的2×1的矢量。计算所得到的结果如下所示:
[[0.09660039 0.55849787]
[0.93007524 0.32329559]]
[0.74966152 0.59573188]
[0.40513259 0.88983912]
同时我们也考虑下另外一种张量运算的场景,一个高阶的张量与另外一个高阶的张量进行运算:
import numpy as np
A = np.random.rand(1, 2, 2, 2)
B = np.random.rand(2, 2, 2)
C = np.einsum('ijkl,klm->ijm', A, B)
print ('A:', A)
print ('B:', B)
print ('C:', C)
这一串python代码表示的计算过程为:C1×2×2=A1×2×2×2⋅B2×2×2,由于这里的多维张量运算已经不能使用普通的numpy.dot来处理,因此我们还是适用了专业的张量计算函数numpy.einsum来进行处理,计算结果如下:
A: [[[[0.85939221 0.43684494]
[0.71895754 0.31222944]]
[[0.49276976 0.13639093]
[0.04176578 0.14400289]]]]
B: [[[0.21157005 0.58052674]
[0.59166167 0.21243451]]
[[0.11420572 0.98995349]
[0.1145634 0.97101076]]]
C: [[[0.5581652 1.60661377]
[0.20621996 0.49621469]]]
以上的两个案例,从张量理论的角度来理解,相当于分别将张量w和张量C表示成了多个张量组合运算的结果。由多个张量构成的组合运算,我们可以使用张量网络来表示:
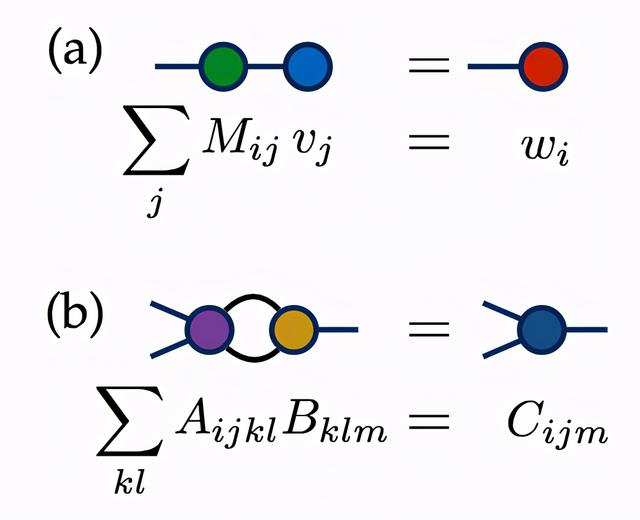
上图所示的(a)(a)和(b)(b)就分别表示张量w和张量C的张量网络图。而这个将张量网络的所有张量进行计算,最终得到一个或一系列的新的张量的矩阵乘加过程,我们也称之为张量缩并,英文叫Tensor Contraction,注:上图转载自参考链接1。
张量缩并顺序与计算复杂性不失广泛有效性的,我们可以以两个张量的缩并案例来分析张量缩并的复杂性,两个张量缩并的计算复杂性主要取决于这两个张量总的腿的数量,如果两个张量之间有共用的腿,则计为1。以上图中的(a)为例,一个2×2的矩阵乘以一个2×1的矢量,一共需要4次乘法运算,而由M和v所构成的张量网络一共有2条腿,那么4次的乘法预算符合O(d2)的计算复杂性,这里的d指的是指定的腿的维度,常用的是2。相关的复杂性除了理论推导,用numpy.einsum的功能模块也可以实现程序判断:
import numpy as np
M = np.random.rand(2, 2)
v = np.random.rand(2)
path_info = np.einsum_path('ij,j->i', M, v, optimize='greedy')
print(path_info[0])
print(path_info[1])
输出结果如下:
['einsum_path', (0, 1)]
Complete contraction: ij,j->i
Naive scaling: 2
Optimized scaling: 2
Naive FLOP count: 8.000e 00
Optimized FLOP count: 9.000e 00
Theoretical speedup: 0.889
Largest intermediate: 2.000e 00 elements
--------------------------------------------------------------------------
scaling current remaining
--------------------------------------------------------------------------
2 j,ij->i i->i
这里的scaling就是上面提到的复杂性O(d2)中的2。同样的如果以上图中的(b)为例,我们可以通过理论推导出其计算复杂性为O(d5),即理论的scaling应该是5,下面也通过程序实现来给出定论:
import numpy as np
A = np.random.rand(1, 2, 2, 2)
B = np.random.rand(2, 2, 2)
path_info = np.einsum_path('ijkl,klm->ijm', A, B, optimize='greedy')
print(path_info[0])
print(path_info[1])
以上程序的执行结果如下:
['einsum_path', (0, 1)]
Complete contraction: ijkl,klm->ijm
Naive scaling: 5
Optimized scaling: 5
Naive FLOP count: 3.200e 01
Optimized FLOP count: 3.300e 01
Theoretical speedup: 0.970
Largest intermediate: 4.000e 00 elements
--------------------------------------------------------------------------
scaling current remaining
--------------------------------------------------------------------------
5 klm,ijkl->ijm ijm->ijm
这里需要我们注意的一点是,如果有两条边同时连接,那么计算scaling的时候也是作为两条边来计算的,而不是合并为一条边之后再计算scaling。
由于上面所提到的两个例子,其实都只涉及到两个张量之间的预算,当多个张量一同进行运算时,就会引入一个新的参量:缩并顺序,在张量网络的实际应用场景中,缩并顺序会极大程度上的影响张量网络计算的速度。首先,让我们用一个例子来分析,为什么不同的缩并顺序会对张量网络计算的性能产生影响:给定四个张量为: aijk,bjlmn,cklo和dmoaijk,bjlmn,cklo和dmo 。如果先缩并 bc ,则对应的计算复杂度的scaling为6。若按照缩并顺序:cd->c,bc->b,ab->a,对应的计算复杂度scaling为5 。也就是说,从复杂度的角度来说,这里选出了一条复杂度较低的缩并路线,这一条复杂性scaling较好的缩并顺序也是由numpy.einsum的贪心算法找出来的:
import numpy as np
np.random.seed(123)
a = np.random.rand(2, 2, 2)
b = np.random.rand(2, 2, 2, 2)
c = np.random.rand(2, 2, 2)
d = np.random.rand(2, 2)
path_info = np.einsum_path('ijk,jlmn,klo,mo->in', a, b, c, d, optimize='greedy')
print(path_info[0])
print(path_info[1])
执行的结果如下所示:
['einsum_path', (2, 3), (1, 2), (0, 1)]
Complete contraction: ijk,jlmn,klo,mo->in
Naive scaling: 7
Optimized scaling: 5
Naive FLOP count: 5.120e 02
Optimized FLOP count: 1.290e 02
Theoretical speedup: 3.969
Largest intermediate: 8.000e 00 elements
--------------------------------------------------------------------------
scaling current remaining
--------------------------------------------------------------------------
4 mo,klo->klm ijk,jlmn,klm->in
5 klm,jlmn->jkn ijk,jkn->in
4 jkn,ijk->in in->in
在前面的章节中我们讨论了将一个张量网络缩并为一个张量的场景下,如何降低其复杂性scaling。其中重点说明了,在特定的缩并顺序下,可以极大程度上的优化张量缩并的性能。这里我们讨论一种在量子计算中常用的技巧:张量的分割。简单地来说,就是前面提到的张量缩并的逆向过程,既然可以将两个张量缩并成一个,那就有可能将一个张量分割成两个张量。
那么为什么需要执行张量分割的操作呢?我们可以直接通过一个案例来说明:
import numpy as np
np.random.seed(123)
a = np.random.rand(2)
b = np.random.rand(2)
c = np.random.rand(2, 2, 2, 2)
d = np.random.rand(2)
e = np.random.rand(2)
path_info = np.einsum_path('i,j,ijkl,k,l', a, b, c, d, e, optimize='greedy')
print(path_info[0])
print(path_info[1])
这里给定了5个张量,其中张量c有四条腿,那么在这个场景下不论以什么样的顺序进行缩并,得到的复杂性的scaling都必然是4,以下是numpy.einsum给出的结果:
['einsum_path', (0, 2), (0, 3), (0, 2), (0, 1)]
Complete contraction: i,j,ijkl,k,l->
Naive scaling: 4
Optimized scaling: 4
Naive FLOP count: 8.000e 01
Optimized FLOP count: 6.100e 01
Theoretical speedup: 1.311
Largest intermediate: 8.000e 00 elements
--------------------------------------------------------------------------
scaling current remaining
--------------------------------------------------------------------------
4 ijkl,i->jkl j,k,l,jkl->
3 jkl,j->kl k,l,kl->
2 kl,k->l l,l->
1 l,l-> ->
但是,如果我们考虑先将这个腿最多的张量做一个分割,使其变为两个三条腿的张量,并且这两个张量之间通过一条边进行连接,代码示例如下:
import numpy as np
np.random.seed(123)
a = np.random.rand(2)
b = np.random.rand(2)
c = np.random.rand(2, 2, 2)
d = np.random.rand(2, 2, 2)
e = np.random.rand(2)
f = np.random.rand(2)
path_info = np.einsum_path('i,j,imk,jml,k,l', a, b, c, d, e, f, optimize='greedy')
print(path_info[0])
print(path_info[1])
让我们先看看numpy.einsum是否会给出一样的缩并顺序呢?
['einsum_path', (0, 2), (0, 1), (0, 2), (0, 1), (0, 1)]
Complete contraction: i,j,imk,jml,k,l->
Naive scaling: 5
Optimized scaling: 3
Naive FLOP count: 1.920e 02
Optimized FLOP count: 5.300e 01
Theoretical speedup: 3.623
Largest intermediate: 4.000e 00 elements
--------------------------------------------------------------------------
scaling current remaining
--------------------------------------------------------------------------
3 imk,i->km j,jml,k,l,km->
3 jml,j->lm k,l,km,lm->
2 km,k->m l,lm,m->
2 lm,l->m m,m->
1 m,m-> ->
我们惊讶地发现,这个给定的scaling较低的缩并顺序并没有一开始就缩并m这条边,如果先缩并了m这条边,那么得到的结果应该跟上面未作分割的顺序和scaling是一样的。另言之,我们通过这种张量切割的方案,实际上大大降低了这个张量网络的缩并所需时间。这里的复杂性scaling每降低1,就意味着需要执行的乘加次数有可能减少到优化前的1d.
补充测试针对于上述章节提到的张量分割的方案,我们这里再多一组更加复杂一些的张量网络的测试:
import networkx as nx
graph = nx.Graph()
graph.add_nodes_from([1,2,3,4,5,6,7,8,9])
graph.add_edges_from([(1,4),(2,4),(3,5),(4,5),(4,6),(5,6),(6,7),(5,8),(6,9)])
nx.draw_networkx(graph)

考虑上图这样的一个张量网络,我们也先将其中三个四条腿的张量进行分割,分割后的张量网络变为如下所示的拓扑结构:
import networkx as nx
graph = nx.Graph()
graph.add_nodes_from([1,2,3,4,5,6,7,8,9,10,11,12])
graph.add_edges_from([(1,4),(5,4),(2,5),(4,5),(4,8),(5,6),(6,7),(3,7),(7,9),(6,11),(8,10),(8,9),(9,12)])
nx.draw_networkx(graph)

然后再次使用numpy.einsum来进行验证。首先是张量分割前的张量网络缩并:
import numpy as np
np.random.seed(123)
a = np.random.rand(2)
b = np.random.rand(2)
c = np.random.rand(2)
d = np.random.rand(2, 2, 2, 2)
e = np.random.rand(2, 2, 2, 2)
f = np.random.rand(2, 2, 2, 2)
g = np.random.rand(2)
h = np.random.rand(2)
i = np.random.rand(2)
path_info = np.einsum_path('i,j,k,ijlm,mnko,lpoq,p,n,q', a, b, c, d, e, f, g, h, i, optimize='greedy')
print(path_info[0])
print(path_info[1])
执行结果如下:
['einsum_path', (0, 3), (1, 2), (1, 2), (0, 3), (0, 2), (0, 1), (0, 1), (0, 1)]
Complete contraction: i,j,k,ijlm,mnko,lpoq,p,n,q->
Naive scaling: 9
Optimized scaling: 4
Naive FLOP count: 4.608e 03
Optimized FLOP count: 1.690e 02
Theoretical speedup: 27.266
Largest intermediate: 8.000e 00 elements
--------------------------------------------------------------------------
scaling current remaining
--------------------------------------------------------------------------
4 ijlm,i->jlm j,k,mnko,lpoq,p,n,q,jlm->
4 mnko,k->mno j,lpoq,p,n,q,jlm,mno->
4 p,lpoq->loq j,n,q,jlm,mno,loq->
3 jlm,j->lm n,q,mno,loq,lm->
3 mno,n->mo q,loq,lm,mo->
3 loq,q->lo lm,mo,lo->
3 mo,lm->lo lo,lo->
2 lo,lo-> ->
我们可以看到未进行张量分割前的复杂性scaling为4,再让我们看下张量分割之后的张量网络缩并情况:
import numpy as np
np.random.seed(123)
a = np.random.rand(2)
b = np.random.rand(2)
c = np.random.rand(2)
d = np.random.rand(2, 2, 2)
e = np.random.rand(2, 2, 2)
f = np.random.rand(2, 2, 2)
g = np.random.rand(2, 2, 2)
h = np.random.rand(2, 2, 2)
i = np.random.rand(2, 2, 2)
j = np.random.rand(2)
k = np.random.rand(2)
l = np.random.rand(2)
path_info = np.einsum_path('i,j,k,iml,jmn,nop,kpq,lrs,sqt,r,o,t', a, b, c, d, e, f, g, h, i, j, k, l, optimize='greedy')
print(path_info[0])
print(path_info[1])
执行结果如下:
['einsum_path', (0, 3), (0, 2), (0, 2), (0, 4), (0, 2), (0, 1), (0, 1), (0, 1), (0, 1), (0, 1), (0, 1)]
Complete contraction: i,j,k,iml,jmn,nop,kpq,lrs,sqt,r,o,t->
Naive scaling: 12
Optimized scaling: 3
Naive FLOP count: 4.915e 04
Optimized FLOP count: 1.690e 02
Theoretical speedup: 290.840
Largest intermediate: 4.000e 00 elements
--------------------------------------------------------------------------
scaling current remaining
--------------------------------------------------------------------------
3 iml,i->lm j,k,jmn,nop,kpq,lrs,sqt,r,o,t,lm->
3 jmn,j->mn k,nop,kpq,lrs,sqt,r,o,t,lm,mn->
3 kpq,k->pq nop,lrs,sqt,r,o,t,lm,mn,pq->
3 o,nop->np lrs,sqt,r,t,lm,mn,pq,np->
3 r,lrs->ls sqt,t,lm,mn,pq,np,ls->
3 t,sqt->qs lm,mn,pq,np,ls,qs->
3 mn,lm->ln pq,np,ls,qs,ln->
3 np,pq->nq ls,qs,ln,nq->
3 qs,ls->lq ln,nq,lq->
3 nq,ln->lq lq,lq->
2 lq,lq-> ->
我们再次发现,张量缩并的复杂性scaling被优化到了3。假如是我们常见的d=2d=2的张量网络,那么在进行张量分割之后,类似于上面这个案例的,张量缩并的时间可以加速1倍甚至更多。
总结概要本文主要介绍了张量网络的基本定义及其缩并复杂性scaling的含义,其中利用numpy.einsum这个高级轮子进行了用例的演示,并且额外的介绍了张量分割在张量网络缩并实际应用场景中的重要地位。通常我们会配合GPU来进行张量网络的缩并,那么这个时候缩并复杂性的scaling影响的就不仅仅是缩并的速度,因为GPU本身的内存是比较局限的,而不断的IO会进一步拉长张量网络缩并所需要的时间。而如果能够有方案将一个给定的张量网络的复杂性scaling降低到GPU自身内存可以存储的水平,那将极大程度上的降低使用张量网络技术求解实际问题的时间。
版权声明本文首发链接为:https://www.cnblogs.com/dechinphy/p/tensor.html作者ID:DechinPhy更多原著文章请参考:https://www.cnblogs.com/dechinphy/
参考链接- 什么是张量网络(tensor network)? - 何史提的回答 - 知乎 https://www.zhihu.com/question/54786880/answer/147099121
- Michael Streif1, Martin Leib,"Training the Quantum Approximate Optimization Algorithm without access to a Quantum Processing Unit", 2019, arXiv:1908.08862
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






