数据安全合格性评估(58安全-图像质量评价技术实践)
01
导读
图像作为信息存储和展示的一种重要载体,其质量高低对信息表达和用户体验具有重大影响,图像质量评价(IQA)主要通过图像特征进行分析,评估出图像的优劣,在视频图像质量检测、推荐排序等领域有重要应用。本文主要介绍 IQA 技术在 58 同城业务中的算法实践。
02
技术背景
图像质量评价(IQA, Image Quality Assessment)是图像领域基础技术之一,图 1 展示了影响图像质量的 9 大因素,最外层表示各个因素的细分类别。例如,清晰度越低的图像,其质量分数一般越低。

图1 图像质量的影响因素
2.1 IQA 方法的分类
IQA 方法按提供原始图像信息的多少,大致可以分为全参考(Full-Reference)、半参考(Reduced-Reference)和无参考(No- Reference 或 Blind- Reference)三种。全参考需要提供一个无失真的原始图像,通过对二者的对比,得到一个对失真图像的评估结果,传统方法有 MSE、PSNR、SSIM、VMAF等,深度学习方法有 FR-DBCNN、WaDIQaM-FR 等;半参考方法只需将失真图像的某些特征与原始图像的相同特征进行比较,比如小波变换系数的概率分布、综合多尺度几何分析和对比敏感函数等;无参考方法完全不需要参考原始图像,该类方法的难度最大,同时实用价值也最高,因为算法的真实应用场景往往很难得到失真图像的原始图像信息,无参考传统方法主要有BRISQUE、MSDD 等,深度学习方法有 NR-DBCNN、hyperIQA、WaDIQaM-NR、RankIQA等。
2.2 典型数据集
算法离不开数据,图 2 展示了近些年 IQA 算法的典型数据集,比如,LIVE 数据集发布于 2006 年,拥有 29 张参考图像,779张失真图像,共有 5 种失真类型,包括 JPEG 压缩、JPEG2K 压缩、白噪声、对比度衰减、高斯模糊。
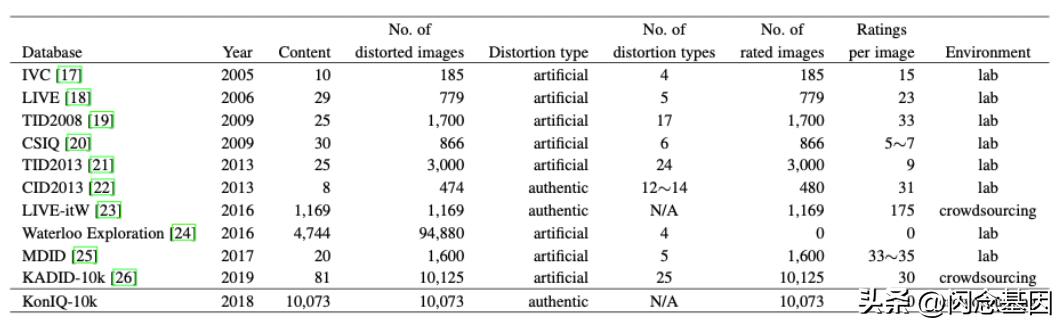
图2 IQA算法的典型数据集
TID2013 发布于 2013 年,拥有 25张参考图像,3000 张失真图像,共有 24 种失真类型;KonIQ-10k 发布于 2018 年,包含 10073 张真实失真图像,每张图像通过众包的方式进行主观评分标注。
IQA 数据集分为真实失真数据集(Authentic Database)和人工失真数据集(Synthetic Database),真实失真的数据集是使用非人工合成的失真图像进行打分标注;人工失真数据集是由原始图像利用图像处理技术来合成不同失真类型和失真程度的图像来进行打分标注,典型的如CSIQ,图像尺寸为512x512,包括 6 种失真类型,由 25个观察者进行打分标注,如图 3 所示。
图3 CSIQ人工合成数据集
IQA 数据集的 label 主要为 MOS(平均主观得分,Mean of Score)和 DMOS(平均主观得分差异,Differential Mean Opinion Score),其计算公式如图 4 所示。
图4 MOS和DMOS的计算公式
其中,M 为观察者人数,ri,j为第 i 个观察者对第 j 张图片的主观评分,U 为第 j 张图片主观得分的均值,ε为标准差,我们可以通过[U-ε,U ε]的 95%置信区间来剔除部分不合理的标注分数;DMOS需要观察者同时对失真图像和参考图像进行主观评分,两者得分差异为di,j,dij’为对第 i 个观察者的主观评分差异进行归一化的结果,最终第 j 张图片的 DMOS 为 M 个观察者的 dij’平均值。
2.3 评价指标
对于一种 IQA 算法性能好坏的评估标准就是关注其在数据集上观察者的主观评分和算法评分的相关度。如果它们的相关度较高,则说明该 IQA 算法的性能较好,否则反之。IQA 算法的评价指标通常为 PLCC/LCC(皮尔森线性相关系数,Pearson’s Linear Correlation Coefficient)和SRCC/SROCC(斯皮尔曼秩相关系数,Spearman’s Rank order Correlation Coefficient),用于衡量算法预测值和真实值的一致性与准确性,值越接近 1 代表性能越好。PLCC 的计算公式如图 5 所示,其由两个变量的协方差和标准差乘积来计算。
图5 PLCC计算公式
SRCC 主要评价的是两组数据的等级相关性,如图 6 所示,假设有 10 张图片,X 变量为图片注的 MOS 得分,Y 为模型预测的得分,分别对两个序列做排序得到变量内部的等级 Rank(X)和 Rank(Y),d 为每张图片等级差值的绝对值,由 d 的平方即可计算 SRCC 的,计算公式如图 7 所示。
图6 变量X和变量Y的等级相关性
图7 SRCC计算公式
2.4 传统方法
IQA 的传统方法 PSNR(峰值性噪比,Peak Signal to Noise Ratio),通常用来评价一幅图像压缩
后和原图像相比质量的好坏,PSNR 越高,压缩后失真越小,其可以借助均方误差 MSE 来计算,如图8,其中 I、K 表示两个 MxN 的单色图像,MAX 表示图像像素的最大值。SSIM(结构相似性指数,Structural SIMilarity Index),主要衡量两张图像的相似度,当两张图像一模一样时,SSIM 的值等于 1,其计算公式为图 9。

图8 PSNR计算公式

图9 SSIM计算公式
2.5 基于 CNN 的方法
随着深度学习的兴起,基于 CNN 的 IQA 方法也相继被提出来,在 IQA 算法性能上也获得了很大的提高。从 CVPR2020 的文章《Blindly Assess Image Quality in the Wild Guided by A Self-AdaptiveHyper Network》可以看出,hyperIQA 在人工失真数据集和真实失真数据集上均达到了较好的性能,同时 DBCNN、WaDIQaM 在LIVE 和 CSIQ 上也达到了不错的效果,接下来我们详细介绍这三种基于CNN 的 IQA 方法。

图10 IQA方法在公开数据集上的性能
2.5.1 WaDIQaM
WaDIQaM 的全参考网络结构如图 11 所示,其特征提取部分是基于 VGG-16 的孪生网络,两个分支分别输入参考图片和失真图片,输入图像是在原始图像上进行随机裁剪的32 个 32x32 的 patch图片,为了使网络适应 32x32 的输入尺寸,作者在 Backbone 上增加了两个卷积层和一个最大池化层;网络两个分支提取的特征向量分别为 fr、fd,特征融合采用 fr、fd和 fr-fd三者进行concat 操作来完成,融合之后的特征向量输入一个全连接层来回归每个 patch 图片的质量分数。网络训练过程中使用 L1loss 进行损失计算。
图11 WaDIQaM全网络参考
当网络得到每个 patch 的得分时,如何表示整张图片的质量分数呢?作者提供了两种空间池化方法:1)直接取所有patch 得分的平均值,这种方法简单直接,但忽略了失真在图像上的空间分布;2)将融合之后的特征向量输入另一个全连接层,回归出每个 patch 得分的权重,最后使用每个 patch的权重与得分进行加权平均得到整张图片的质量预测分数。
图12 WaDIQaM的无网络参考
WaDIQaM 的无参考网络是在全参考网络的基础上舍弃了全参考分支和特征融合操作,采用相同的空间池化方法和损失函数。
WaDIQaM 方法的特点是:1)与其他Data-driven 的方法不同,patch 数据没有进行归一化,考虑了整体图像亮度和对比度对质量的影响;2)各个 patch 引起观察者的注意力程度不同,局部失真的空间分布不同,给予不同的权值能够更好地评估图片质量(类似于注意力机制)。
图13 WaDIQaM 对不同失真类型图像的每个patch权重可视化,亮度越大表示权重越大
2.5.2 DBCNN
DBCNN 是发表在 IEEE 2018 上的方法,其网络结构也是由两个基于 VGG16 分支的孪生网络组成。
图14 DBCNN网络结构图
DBCNN 其中一个分支为 S-CNN,主要功能是用于人工失真分布的拟合,作者在大型图像数据集Waterloo Exploration Database 和 PASCAL VOC 进行不同失真类型和失真程度的数据合成,总共包含39 个失真类别。预训练的图像尺寸为 224x224,使用 Softmax loss 进行损失计算。
图15 PASCAL VOC 数据集上合成的人工失真图片
DBCNN 的另一个分支主要功能是识别真实失真的分支,分支权重在 ImageNet 数据集上进行预训练,损失函数也为 Softmax loss;DBCNN 特征融合部分采用了双线性池化的操作,S-CNN 提取的特征向量为 Y1,VGG16 提取的特征向量为 Y2,双线性池化之后的特征为 B=Y1TY2,最后 B 输入一个全连接层得到质量分数,并通过 L2 loss 进行回归优化。
DBCNN 方法的特点是:1)合成大型的人工失真数据集并设计 S-CNN 预训练,尽量减小真实失真和模拟失真之间的 gap,提高模型泛化性;2)使用双线性池化来进行特征融合。
2.5.3 hyperIQA
最后介绍 hyperIQA,来自于 CVPR2020,如图 16 所示,其整体网络结构包括三个部分:特征提取网络、感知规则学习网络和质量分数预测网络;由于真实场景下图像失真类型和失真程度的复杂性,作者认为对于不同内容的图片,模型对质量的评价尺度应该做自适应的调整,模型的感知规则学习网络就是为了实现这一功能。

图16 hyperIQA 网络结构图
通常 IQA 模型经过训练后,其质量预测的网络权重θ也就固定了,针对输入图片 x,与模型权重θ经过计算后输出质量分数 q;hyperIQA 针对不同图片 x,则会自适应地调整模型权重,由感知规则学习网络 H 和特征提取网络 S 生成自适应权重θx,由输入图片 x 和自适应权重θx计算质量分数 q,整体过程由图 17 的数学公式进行表示。

图17 hyperIQA 的数学公式表示
HyperIQA 的特征提取网络采用的是 ResNet50,共提取 4 个 stage 的多尺度特征,前三个特征向量输入局部失真感知模块(LDA),其由 1x1 卷积和全局平均池化层构成,输出向量采用 concat 操作进行连接,用于质量预测,如图 18 所示。

图18 hyperIQA 特征提取网络
hyperIQA 的感知规则学习网络由多个 1x1 卷积层构成,其输入为特征提取网络提取的高层语义特征,输出向量为质量预测网络全连接层的权重和偏置,即自适应权重?!。质量预测网络由 4 个全连接层构成,输入为特征提取网络提供的多尺度特征,其与自适应权重?!计算得到最终的质量分数 q。训练时 hyperIQA 对每张输入图片随机采样 25 个 224x224 的patch 进行训练,采用 L1 loss 进行损失计算。
hyperIQA 方法的特点是:1)设计更符合人类视觉系统的 Hyper Network,能够根据图像内容自适应调整质量预测网络的权重;2)局部感知模块 LDA 能够感知图像局部失真,结合全局语义信息,进行图像质量的综合评估。
总体来说,目前 IQA 方法的设计理念都是为了完成 IQA 任务的终极目标,即感知图像不同失真类型和失真程度的分布。
03
业务背景
58 同城作为国内领先的分类信息网站、专业的“本地、免费、真实、高效”的生活服务平台,包括本地服务、房产、招聘、二手市场、金融、汽车等业务板块,拥有庞大的活跃用户群,每天接受的图片流量高达数亿。
58 同城在企业招聘业务中,企业主需要上传企业相关图片到企业图库,但这些上传的图片质量良莠不齐,存在如下问题:
1、部分图片质量过低,无法满足业务标准,需要对其进行识别和剔除,降低图片不良率(目前线上不良率为 9%);
2、无法区分中高质量图片,因此无法通过排序或推荐的方式提升用户体验。
图19 招聘企业图库存在的图片类型
如图 19,展示了企业图库中存在的部分图片类型,通过需求提炼,我们归纳了业务中关于图片质量的大致需求:
1、 模糊、噪声、锐化、曝光和畸变严重等的图片属于低质量图片;
2、 长宽差距过大的图片为非高质量图片;
3、 纯色背景的产品展示图、品牌 Logo 等为非高质量图片;
4、 文字占比过大、大字报类图片为非高质量图片;
5、 证书、执照、协议、合同类图片为非高质量图片;
6、 分辨率过低的图片为低质量图片;
因此设计的图像质量评价技术方案需要解决上述问题并满足相应的业务需求,并达到良好的落地性能。
04
技术方案
为了满足当前的业务需求,我们设计了相应的技术方案,如图 20 所示,以 IQA 模型为基础得到业务图像的基础得分,通过 OCR、背景聚类等方法对质量分数进行校正,得到最终的业务评分。
图20 技术方案
为了衡量当前算法方案的性能,我们建立了业务测试集58zhaopin-5k,由表 1 所示,其含有低质量图片 814 张,中等质量图片 1605 张,高质量图片 2572 张。
表格1 58zhaopin-5k测试
由于 IQA 模型预测的质量分数为连续值,而我们的业务测试集为离散的类别,对模型输出的预测分数我们采用 K-means 方法进行分数粗聚类,由小到大排序,对于类别边界的样本采用阈值搜索来确定准确率最高的阈值。
图21 K-means 粗聚类与阈值搜索可视化
我们使用 WaDIQaM、DBCNN 和 hyperIQA 分别在人工失真数据集 LIVE、TID2013 和真实失真数据集 Koniq-10k 上进行训练,并在 58zhaopin-5k 测试集上进行测试,由表 2 可知,Koniq-10k 上训练的 hyperIQA 模型,在测试集 58zhaopin-5k 上达到了最高的准确率 86.93%,由此我们选定在真实场景中性能较强的 hyperIQA。
表格2 WaDIQaM、DBCNN 和 hyperIQA 在不同训练集上训练的模型在目标测试集上的准确率结果,其中Accuracy-low表示低质量类别的准确率,Accuracy-middle表示种类质量类别的准确率,Accuracy-high表示高质量类别的准确率
由于 hyperIQA 使用的原始 Backbone 网络为 ResNet50,我们尝试将其替换为更为轻量型的网络ResNet18、MobileNetv3,其测试结果如表 3 所示,hyperIQA-ResNet18 与 hyperIQA-ResNet50 的指标接近,但其模型复杂度较小,故采用更为轻量的hyperIQA-ResNet18。
表格3 hyperIQA不同 Backbone在58zhaopin-5k上的性能指标
hyperIQA 作为基础模型得到的质量分数为 0~100 的浮点值,经过粗聚类,0~40 为低质量分数段,40~60 为中等质量分数段,60~100 为高质量分数段,接下来我们针对各个不同的 case 进行得分校正:
1、 直接校正:低分辨率(长或宽小于 256)的图片进行惩罚,高分辨率(长或宽大于 1000)的图片
进行奖励;长宽比(长:宽<2.5或 宽:长<2.5)的图片进行惩罚;
2、 文字检测(DBNet),累计文字像素区域面积,统计文字面积占整张图片的比率,大于 30%为占
比过高,归为中低质量图片,将高质量得分映射到中质量分数段;
3、 文字识别(CRNN),含“执照”、“证书”、“合同”、“协议”、“许可”、“授权”、“统
一社会信用代码”、“注册资本”、“经营者姓名”、“经营场所”等关键字的图片,归为
中低质量图片,将高质量得分映射到中质量分数段;

图22 OCR识别
4、 通过前述校正方法后的高质量图片还会进行背景像素聚类,过滤产品展示图、Logo 图片,将高质量得分映射到中质量分数段。

图23 原始图片和背景颜色聚类后的结果图像示例
如表 4 所示,当加入上述分数校正方法后,算法方案在测试集上的准确率指标由 86.93%提高至94.72%。

表格4 加入分校正方法后,算法方案在测试集上的准确率指标,whRatio表示长宽比分数校正,textRatio表示文字占比率过大分数校正,purColor背景颜色聚类分数校正
05
落地效果
我们将算法方案工程化和服务上线后,服务每日增量图片调用量为 12 万次,存量图片调用 200万次,58 招聘企业图库的图像不良率由 9%降低至 0%,达到了业务需求的预期。

图24 算法方案的结果展示
06
总结与展望
我们基于实际业务场景,提出了一套定制化的图像质量评估算法方案,并很好地满足当前业务需求。在未来,我们将对算法方案通用化进行改进优化,使其既能提供识别high-level 特征的能力,又能提供识别特定需求 low-level 特征的能力,拓展业务场景,在视频与图像质量检测等多个业务中达到良好的落地性能。
参考文献:
[1]https://blog.csdn.net/Image_test/article/details/52036873?locationNum=2&fps=1
[2] Vlad Hosu, Hanhe Lin, Tamas Sziranyi, and Dietmar Saupe. Koniq-10k: An ecologically valid database fordeep learning of blind image quality assessment.
[3] Shaolin Su, Qingsen Yan, Yu Zhu, Blindly Assess Image Quality in the Wild Guided by A Self-AdaptiveHyper Network.
[4] Sebastian Bosse, Dominique Maniry, Klaus-Robert Mu ller, Thomas Wiegand, and Wojciech Samek. Deepneural networks for no-reference and full-reference image qual- ity assessment.
[5] Weixia Zhang, Kede Ma, Jia Yan, Dexiang Deng, and Zhou Wang. Blind image quality assessment using adeep bilinear convolutional neural network.
[6] https://blog.csdn.net/caoleiwe/article/details/49045633.
[7] https://www.cnblogs.com/zhangzizi/p/14734071.html
作者:谢章翔
来源:58技术
出处:https://mp.weixin.qq.com/s/JI6KL1JeQV99y1Eo4kkmuA
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






